- The paper introduces HyperCloning, a method for initializing large language models using small pretrained models to preserve function and improve convergence.
- It employs vector cloning and linear layer expansion techniques, achieving training speedups of up to 4x while maintaining accuracy.
- Experiments on OPT, Pythia, and OLMO models demonstrate significant GPU-hour reductions and consistent accuracy gains across multiple benchmarks.
Scaling Smart: Accelerating LLM Pre-training with Small Model Initialization
Introduction
The paper "Scaling Smart: Accelerating LLM Pre-training with Small Model Initialization" (2409.12903) proposes HyperCloning, an innovative approach for initializing LLMs using small pretrained models. This method effectively bridges the gap between the high accuracy demands of large models and the cost-effectiveness of smaller models by transferring knowledge from the latter to the former. The introduction highlights the significant computational challenges associated with training voluminous LLMs, emphasizing the monetary and temporal burdens imposed by large-scale training operations, such as those required for models with billions of parameters.
Methodology
HyperCloning aims to efficiently initialize larger LLMs from small pretrained networks, preserving their predictive capabilities and accuracy. The method entails expanding the parameters of a pretrained model to fit those of a larger network while ensuring that internal representations and output logits replicate those of the source. This strategy, termed "function preservation," facilitates faster convergence post-initialization, as the larger model begins with the inherited accuracy of its smaller counterpart.
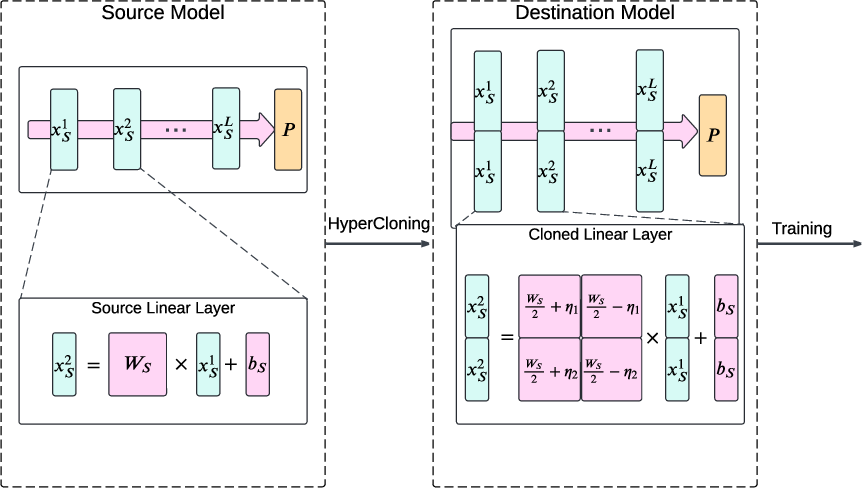
Figure 1: Illustration of HyperCloning. The parameters of the pretrained source network (left) are transferred to the destination network (right), enhancing training speed and final accuracy.
The process involves four critical design goals: expanding dimensions, preserving functions, minimizing computational overhead, and maintaining training setups. HyperCloning adopts vector cloning and linear layer expansion techniques, initializing the destination model with duplicated and normalized weight blocks. The method surmounts traditional expansion methods that require depth augmentation or iterative distillation.
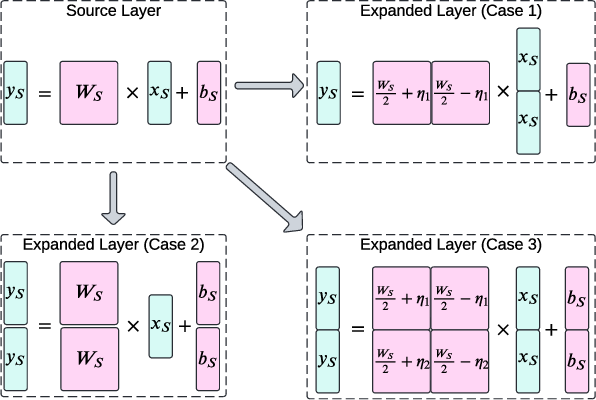
Figure 2: Demonstration of Linear layer cloning with 2-fold expansion, where Ws is the source model weight and η is a random noise matrix.
Experiments
Experiments conducted on three distinct LLMs—OPT, Pythia, and OLMO—demonstrate the efficacy of HyperCloning. Noteworthy improvements are noted in terms of reduced training time and enhanced final accuracy, with speedups of 2.2x to 4x across models. The models were evaluated using accuracy metrics across multiple benchmarks, revealing consistency in accuracy benefits when initialized with HyperCloning compared to traditional random initialization.
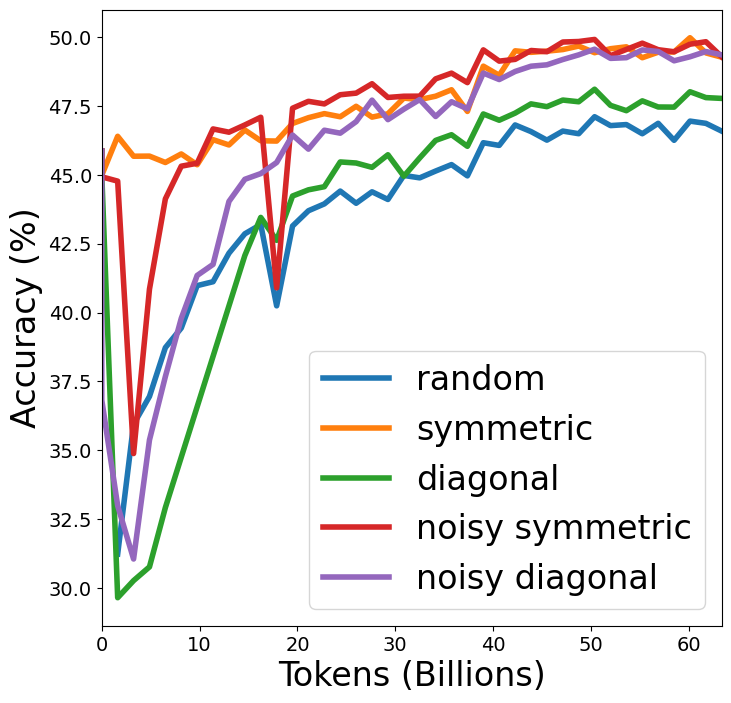
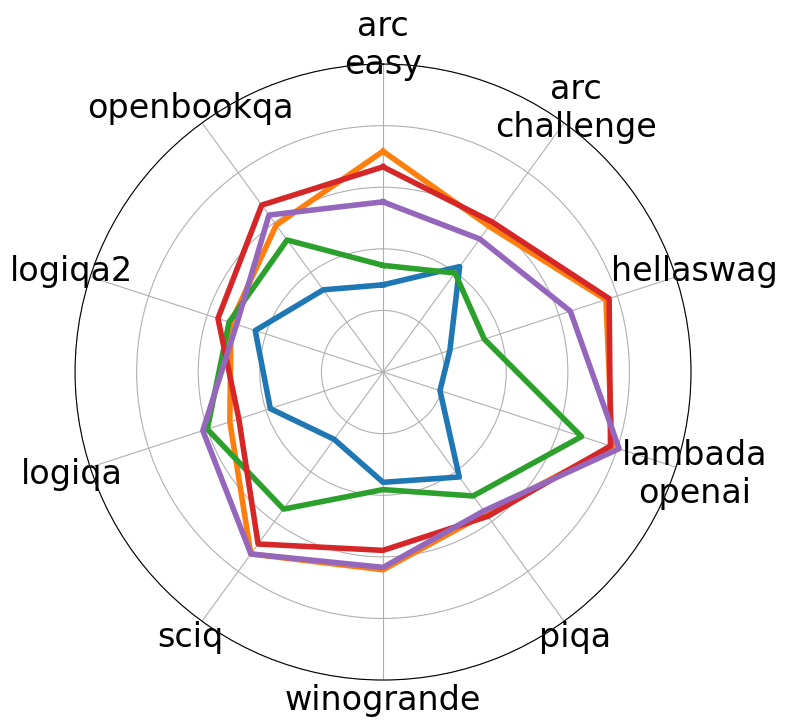
Figure 3: Average Accuracy over 10 tasks when models are initialized with random weights and HyperCloning.
In-depth analysis of weight distribution and symmetry during training supports the robustness of HyperCloning. The weight symmetry naturally breaks due to stochastic processes, such as dropout, while updates over iterations manifest significant divergence from initial symmetry, indicating effective usage of the parameter space.
HyperCloning is distinct from existing model expansion techniques, particularly due to its function-preserving nature. Traditional approaches, such as Net2Net for CNNs, and linear layer stacking methods in BERT models, primarily focus on non-function-preserving strategies. Conversely, HyperCloning ensures functional and parameter equivalency, a feature absent in most prior works, providing improved accuracy without altering training loops significantly.
Previous methodologies like staged training or diagonal expansion often result in slowed convergence or reduced accuracy gains. HyperCloning circumvents these pitfalls, leveraging symmetric and noise-added expansions for optimal performance.
Conclusion
HyperCloning emerges as a promising strategy for initializing LLMs efficiently and effectively. The method exhibits clear advantages in accelerating training and achieving superior final accuracies by utilizing previously trained models as initialization references. Importantly, it reduces GPU hours and computational costs, making it both a pragmatic and economically viable solution for large-scale LLM training.
Future research avenues may explore the particular mechanisms by which HyperCloning mitigates catastrophic forgetting and explore potential improvements in its architectural scalability and adaptability across diverse model types. This work underscores the profound benefits of leveraging small model pretrained knowledge in LLM training paradigms.
