- The paper presents MeMo, a multimodal dataset combining video, audio, transcripts, and non-verbal cues to capture conversational memory dynamics.
- It employs robust experimental design and validated questionnaires to link participants' memory retention with observable cues like eye gaze and gestures.
- Machine learning models applied to MeMo achieve above-chance accuracy in classifying memory retention, demonstrating its potential for advancing intelligent conversational systems.
Introducing MeMo: A Multimodal Dataset for Memory Modelling in Multiparty Conversations
This essay provides a technical overview and analysis of the paper titled "Introducing MeMo: A Multimodal Dataset for Memory Modelling in Multiparty Conversations" (2409.13715). The MeMo corpus brings forth a unique approach to understanding conversational memory by leveraging multimodal data encompassing verbal, non-verbal, and contextual information from multiparty conversations.
Core Contributions and Data Characteristics
The MeMo corpus is primarily constructed to enhance the comprehension and computational modeling of human conversational memory. It includes 31 hours of small-group discussions on COVID-19, recorded over three sessions spanning two weeks, thereby offering a longitudinal perspective on memory retention processes. Each session involves group discussions with zero acquaintance participants, governed by professional moderators to ensure managed and natural interaction dynamics conducive to memory encoding and retention.
The dataset is unparalleled in its detail and multimodality, combining video, audio, transcript data, and multimodal annotations, including eye gaze behaviors, head poses, hand gestures, and textual information. Such diverse data supports investigating memory modeling in spontaneous group interactions, tracking relational and conversational dynamics effectively.
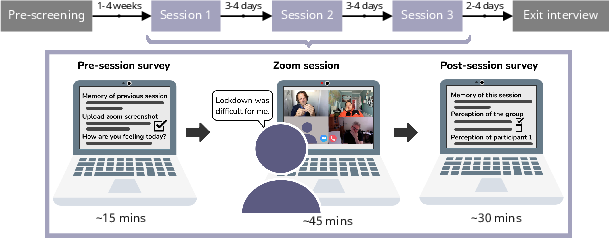
Figure 1: Experimental set-up. Upper flowchart - overall set-up. In the lower part - illustration of the procedure for every group session.
Methodology and Design Principles
The research paper details guiding principles behind MeMo's design, emphasizing ecological validity, construct validity, and context sensitivity. Ensuring ecological validity involved using natural online environments familiar to participants to elicit authentic conversational behavior. Construct validity was achieved through direct memory retention annotations by participants, linking recalled memories precisely to conversation timestamps—bypassing traditional third-party annotation limitations.
Moreover, variables such as mood, personality, values, and relationship dynamics, known to affect memory processes, were incorporated using validated questionnaires. The methodology supporting the dataset is robust, considering diverse demographic information to reflect realistic societal settings, aiding in the modeling of conversational memory in varied contexts.
Strong Numerical Results and Claims
One of the significant numerical results presented in the paper is the dataset's ability to categorize memory retention levels based on aggregated group responses. This classification showed promising computational modeling results, with machine learning algorithms performing above chance levels using non-verbal cues like eye gaze direction, achieving a balanced accuracy of approximately 0.42 to 0.43.
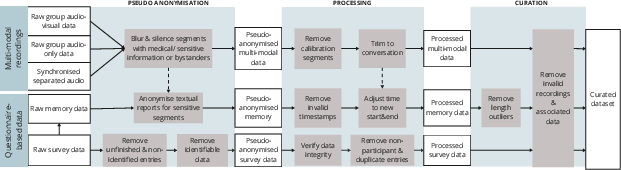
Figure 2: MeMo corpus processing and curation steps
Implications and Speculative Developments
The implications of the MeMo dataset extend to both theoretical and practical realms. Theoretically, it advances the understanding of conversational memory as a selective episodic memory phenomenon influenced by intricate socio-cognitive factors. Practically, the dataset heralds new possibilities for developing intelligent systems capable of assisting human facilitators or acting as autonomous facilitators in group interactions by tracking both real-time participant states and their retrospective memory.
For future AI developments, MeMo can serve as a foundational resource in enhancing AI systems with memory-like features, fostering long-term human-agent interaction by accurately modeling what humans remember. This prospect gains importance in applications such as meeting facilitation systems, conversational agents, and even personalized digital companions—enabling them to understand user memory dynamically.
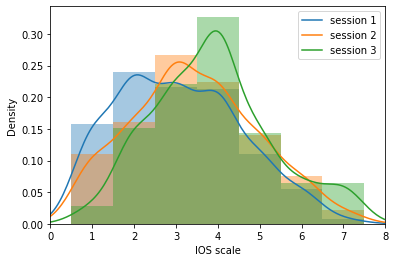
Figure 3: The change in perceived social distance between participants throughout the 3 sessions of the interactions, reported through IOS scale, with 1 = no overlap, 3 = some overlap and 7 = most overlap \cite{aron1992IOS}.
Conclusion
The MeMo corpus offers an innovative approach to exploring human conversational memory by providing a multimodal dataset with comprehensive metadata reflecting natural conversations. It promises advancements in computational modeling of memory processes, fostering novel intelligent systems designed to enhance human interactions. As researchers draw insights from MeMo, they pave the way for AI systems better equipped to comprehend, predict, and interact based on the intricate dynamics of human memory retention and retrieval.