- The paper shows that language models can follow instructions effectively without explicit tuning by leveraging implicit adaptation methods like response tuning and single-task finetuning.
- It employs controlled experiments and rule-based adjustments to compare alternative adaptation methods with traditional instruction tuning in models such as Llama-2-7B.
- These results imply that pretrained LMs inherently develop instruction-following behavior, enabling more efficient and versatile deployments across diverse applications.
Instruction Following without Instruction Tuning
Introduction
The paper examines how LMs can follow instructions without direct instruction tuning, a common practice in fine-tuning LMs on paired instruction-response datasets. The authors identify two alternative adaptation methods that result in implicit instruction tuning, enabling the LM to follow instructions effectively even with data that does not expressly involve instruction-response pairs. They also propose a simple rule-based method to achieve similar outcomes, demonstrating that instruction-following behavior can emerge under various, seemingly suboptimal, tuning conditions.
Implicit Instruction Tuning
Response Tuning: Training LMs solely on desired responses reveals that explicit instruction-response pairs are not essential for instruction-following behavior. By only updating the model based on response data without corresponding instructions, LMs can still achieve reasonably high instruction-following capabilities.
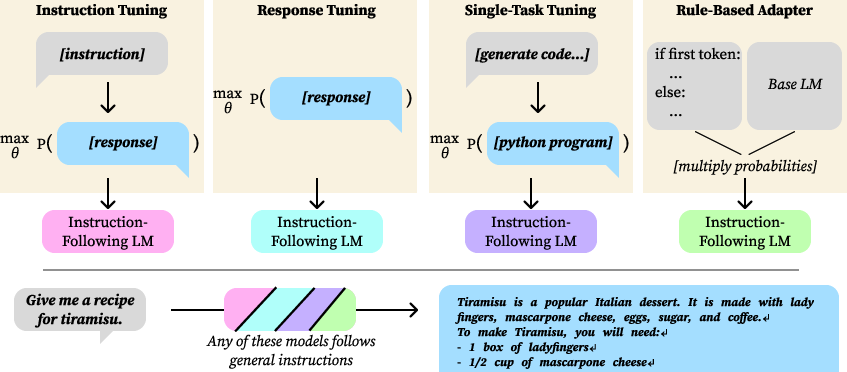
Figure 1: Instruction tuning versus other tuning methods such as response tuning and single-task finetuning, illustrating their effect on instruction-following behavior.
The investigation shows that, through pretraining, LMs seem to learn an implicit mapping from instructions to responses, and this mapping is sufficient under certain conditions.
Single-Task Finetuning: When LMs are fine-tuned on data from a narrow domain, such as poetry generation or math problem solving, they unexpectedly exhibit broad instruction-following when evaluated with unrelated instructions. This shows that even when models are adapted with a highly specialized dataset, they might generalize to follow a wide range of instructions that were not part of the original tuning dataset.

Figure 2: Example outputs from single-task finetuned models, like poetry and Python code generation, demonstrating instruction-following on unrelated tasks.
Rule-Based Model
The paper introduces a rule-based mechanism that modifies the output distribution of a pretrained LM using three simple rules to result in improved instruction-following capabilities. This "product-of-experts" approach applies:
- Increasing the probability of sequence-ending tokens (EOS) to encourage concise responses.
- Penalizing repeated tokens to enhance response variety.
- Uniformly modifying the likelihoods of a select set of tokens.
These rules, applied in the ensemble with the pretrained model, lead to effective instruction-following behavior, showing that significant transformation between pretrained and instruction-tuned models might involve relatively simple alterations of conditional distributions.

Figure 3: Responses from the rule-based model indicating general instruction-following despite simple probabilistic adjustments.
Experimental Results
The results indicate that response tuning leads to nearly equivalent instruction-following capabilities compared to instruction-tuned models for both Llama-2-7B and OLMo-7B-Feb2024. Furthermore, single-task finetuning on diverse datasets results in improved instruction-following, except in specialized domains with deterministically low variance (such as chess move listings).

Figure 4: Performance metrics comparing instruction-tuned and alternative adaptation methods showing substantial instruction-following behaviors.
The rule-based ensemble model also demonstrates instruction-following ability without any fine-tuning, achieving performance comparable to single-task models.
Implications and Future Directions
The findings suggest that instruction-following is deeply integrated into the pretraining phase of LMs, where implicit mappings between instructions and responses are likely established. This has practical implications for deploying LMs in task-specific settings; developers can anticipate broad generalization even when tuning for specific applications. Future work should explore further simplifications and variations of rule-based models and examine the impact of even narrower domain tunings across different languages and dialects.
Conclusion
This research shows that LLMs possess inherent instruction-following potential that can be unlocked using implicit adaptation methods as opposed to traditional instruction tuning. The insights demonstrate that even seemingly suboptimal finetuning strategies can lead to generalized instruction-following proficiency, opening up new avenues for efficiently deploying LMs in practical, versatile applications.