- The paper introduces a pioneering LLM Psychology framework leveraging typoglycemia to compare cognitive processing between LLMs and humans.
- It presents the TypoBench benchmark with TypoPipe and TypoTask to systematically evaluate LLM performance on scrambled text tasks.
- Experimental results show advanced LLMs maintain higher accuracy under increased scrambling, highlighting distinctive machine cognitive strategies.
Mind Scramble: Unveiling LLM Psychology Via Typoglycemia
The paper "Mind Scramble: Unveiling LLM Psychology Via Typoglycemia" presents an innovative approach to exploring the cognitive mechanisms of LLMs by adapting the psychological phenomenon of Typoglycemia to evaluate LLMs. The research establishes a systematic framework, LLM Psychology, to assess the alignment and divergence in cognitive patterns between LLMs and humans when processing scrambled text.
Introduction to LLM Psychology and Typoglycemia
The concept of LLM Psychology is introduced as a framework for interpreting the cognitive behaviors of LLMs by drawing parallels with human psychology experiments. Typoglycemia, the human ability to decode scrambled text as long as the first and last letters remain unchanged, provides a basis for examining whether similar mechanisms exist in LLMs. This study leverages Typoglycemia to investigate the extent to which LLMs exhibit human-like comprehension processes and the underlying factors influencing their performance.
Typoglycemia Benchmark (TypoBench)
TypoBench serves as the experimental benchmark within this framework, incorporating TypoPipe and TypoTask components to challenge LLMs across various tasks involving scrambled text.

Figure 1: TypoBench Overview. TypoPipe and TypoTask form the two components of our benchmark. The overall pipeline consists of 4 steps: Calibration, Navigation, Refabrication, and Refinement. TypoTask consists of two task categories: TypoC and TypoP which emphasize performance and perception, respectively.
TypoPipe
The TypoPipe is a standardized pipeline composed of four stages: Calibration, Navigation, Refabrication, and Refinement. It rigorously prepares the evaluation datasets, transforms textual data using TypoFuncs (like Reordering, Insertion, Deletion at various text granularities), performs tasks, and refines results based on performance metrics.
TypoTask
TypoTask is divided into Typoglycemia Completion (TypoC) and Typoglycemia Perception (TypoP) tasks. TypoC measures LLMs' capability to complete core tasks like problem-solving under Typoglycemia, while TypoP evaluates broader cognitive perceptions such as rectification and transformation of scrambled text.
Experimental Results
The experiments shed light on several research questions regarding LLMs' performance under Typoglycemia.
Typoglycemia Impact (RQ1)
LLMs exhibit decreased accuracy with scrambled inputs, echoing human difficulties with Typoglycemia. Notably, more advanced models display lesser reductions in performance, indicating improved robustness against textual perturbations.
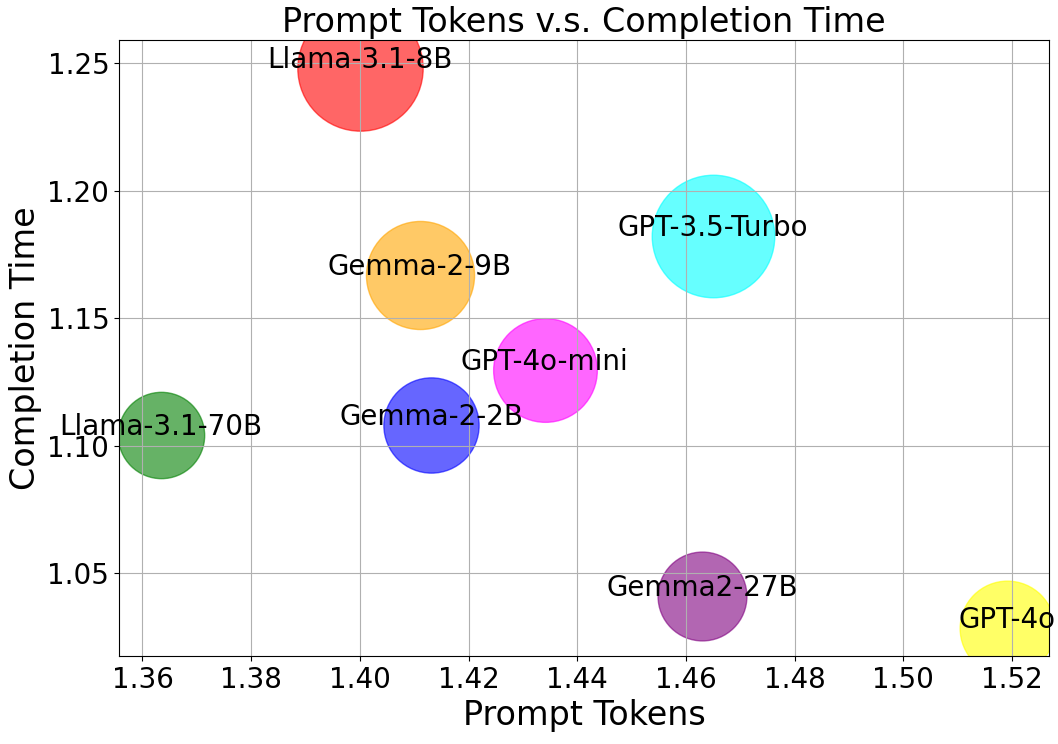
Figure 2: Token and time consumption ratio before and after being processed by TypoFunc when FΩ= REO-INT on character level for BoolQ dataset.
Other Typoglycemia Functions (RQ2)
Variants of Typoglycemia, such as Insertion and Deletion, similarly affect performance. The magnitude of impact is variable, with Insertion and Deletion generally resulting in a smaller performance drop compared to Reordering.
Scrambling Ratio (RQ3)
Increasing the scrambling ratio further impairs LLMs' task accuracy, paralleling the well-documented human struggle with increasing text complexity.
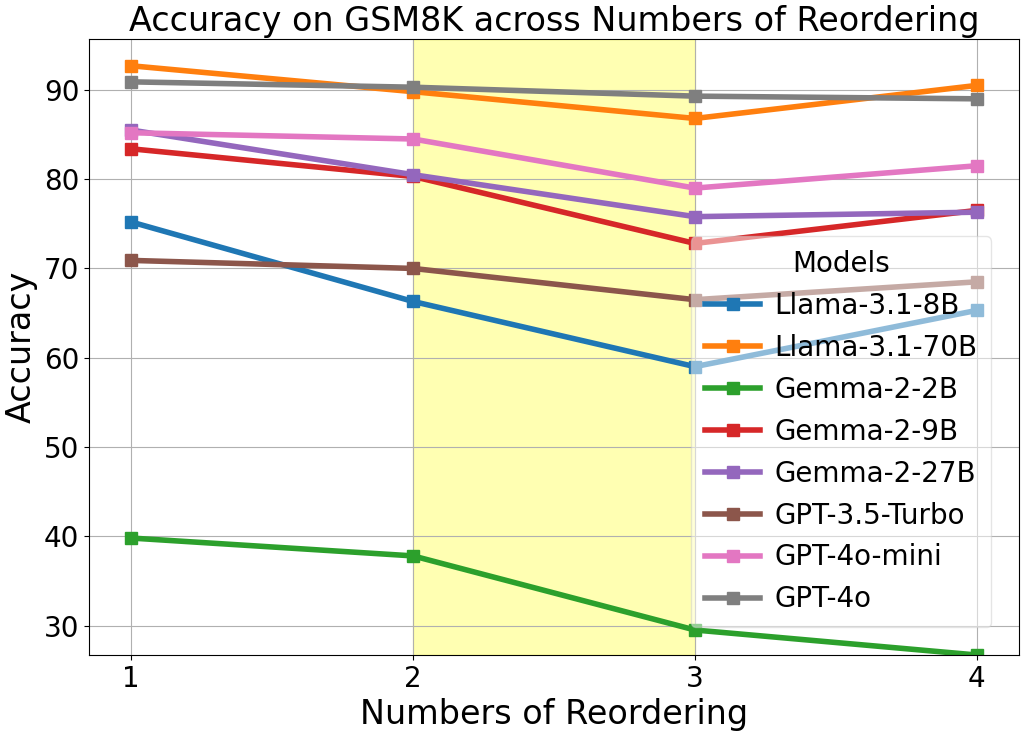
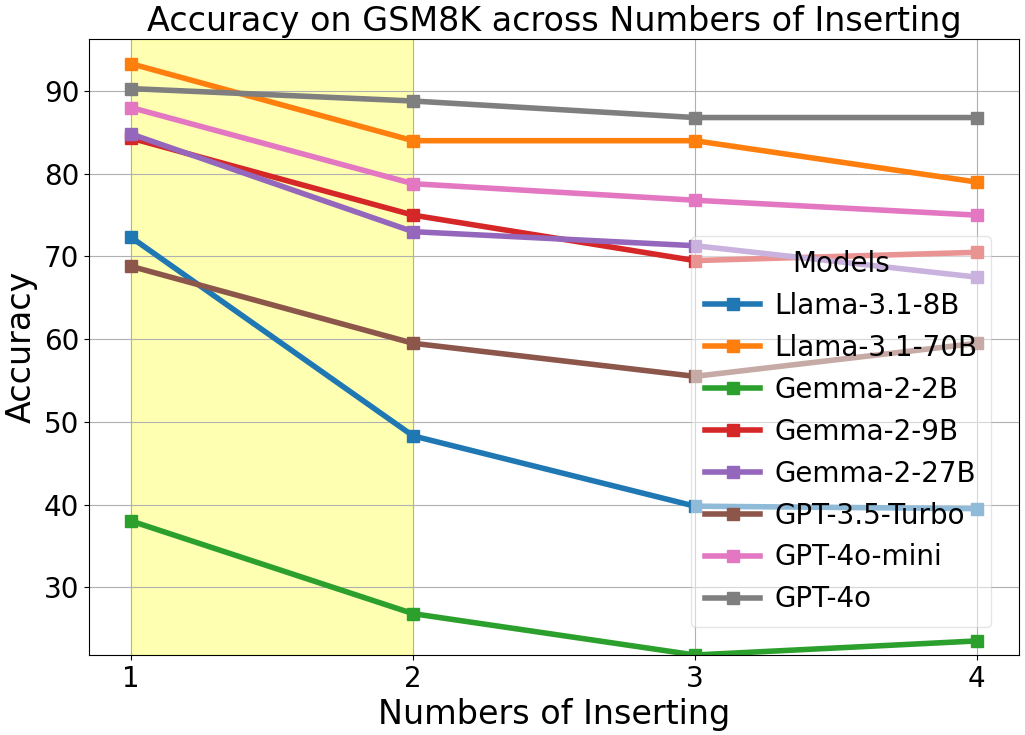
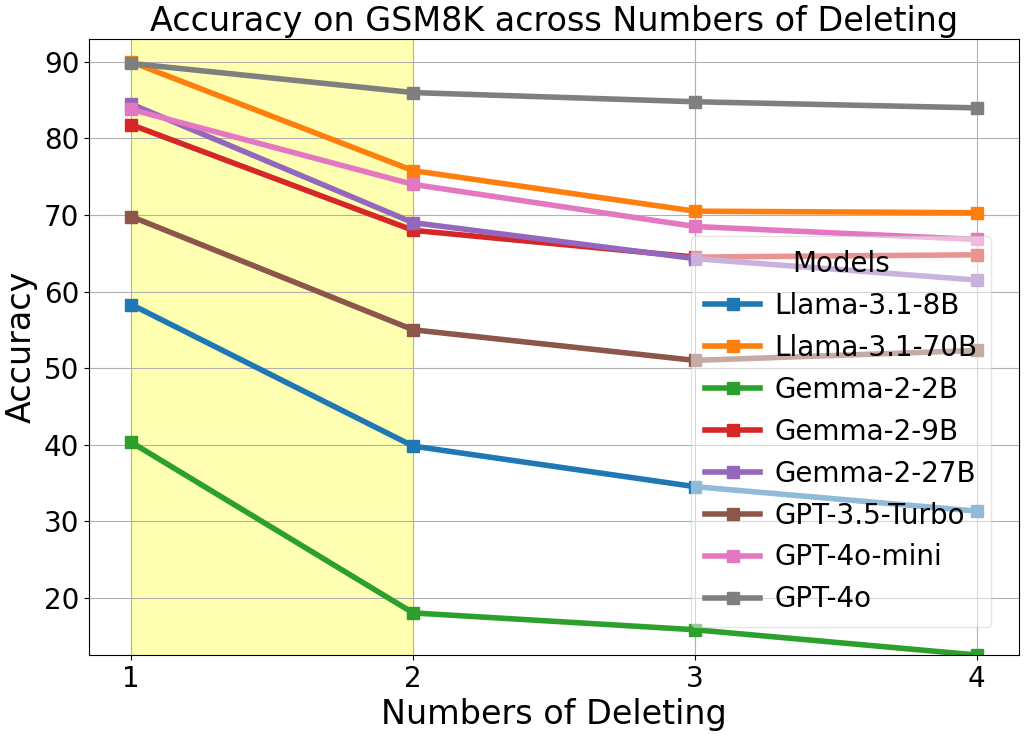
Figure 3: The line charts of accuracy for each model, as the number of operations increase from 1 to 4 when FΩ= REO on character level.
Cognitive Analysis and Mechanisms (RQ4)
Semantic analysis reveals that while LLMs' internal representations retain high semantic similarities between scrambled and coherent texts, they rely heavily on statistical patterns instead of cognitive logic to process Typoglycemia tasks.
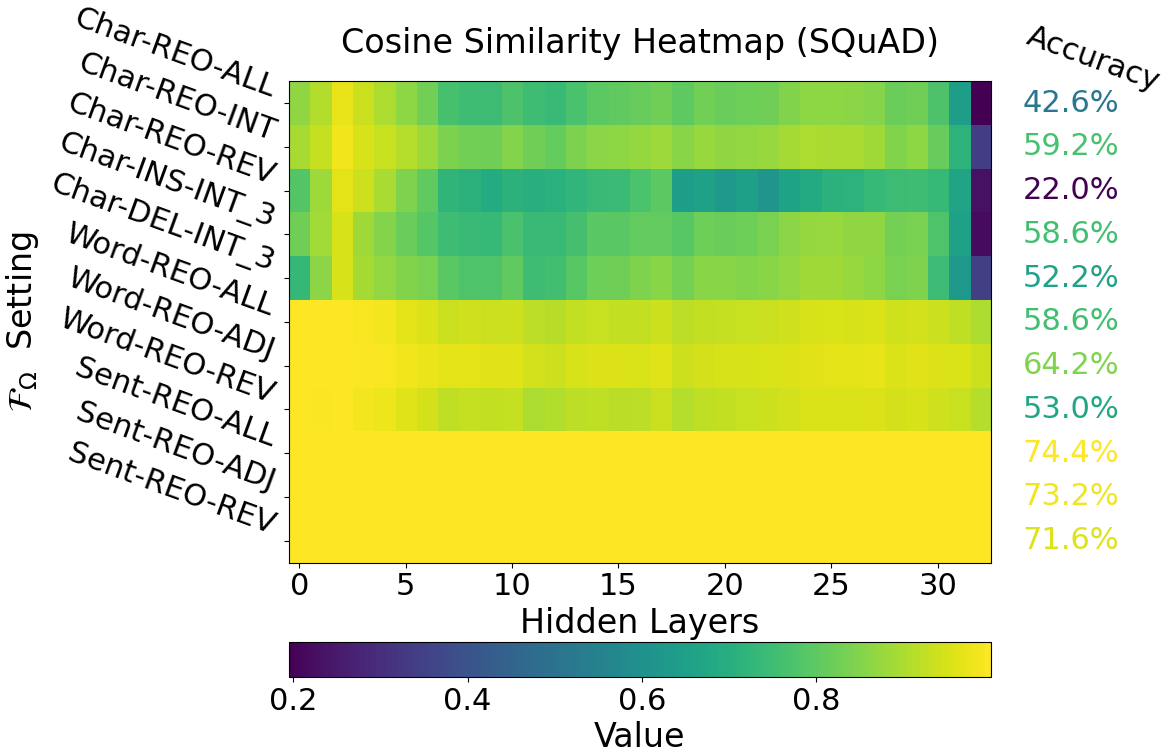
Figure 4: Decoder Perspective: The cosine similarity between the representations of normal text and the text processed by TypoFunc across various levels.
Moreover, analyses of hidden layers suggest each LLM embodies unique "cognitive patterns" in processing rearranged text, distinctive from human cognitive processes but consistent within individual models.
Conclusion
The study provides a foundational exploration of LLM Psychology through the lens of Typoglycemia, revealing both human-like behavioral patterns and machine-specific cognitive strategies in LLMs. With TypoBench offering a democratized benchmark for assessing LLM capability, this work paves the way for deeper insights into artificial cognition and its future developments. Future work should explore extending these findings to more diverse LLM architectures and linguistic phenomena.