Human-like conceptual representations emerge from language prediction
Abstract: People acquire concepts through rich physical and social experiences and use them to understand the world. In contrast, LLMs, trained exclusively through next-token prediction over language data, exhibit remarkably human-like behaviors. Are these models developing concepts akin to humans, and if so, how are such concepts represented and organized? To address these questions, we reframed the classic reverse dictionary task to simulate human concept inference in context and investigated the emergence of human-like conceptual representations within LLMs. Our results demonstrate that LLMs can flexibly derive concepts from linguistic descriptions in relation to contextual cues about other concepts. The derived representations converged towards a shared, context-independent structure that effectively predicted human behavior across key psychological phenomena, including computation of similarities, categories and semantic scales. Moreover, these representations aligned well with neural activity patterns in the human brain, even in response to visual rather than linguistic stimuli, providing evidence for biological plausibility. These findings establish that structured, human-like conceptual representations can naturally emerge from language prediction without real-world grounding. More broadly, our work positions LLMs as promising computational tools for understanding complex human cognition and paves the way for better alignment between artificial and human intelligence.
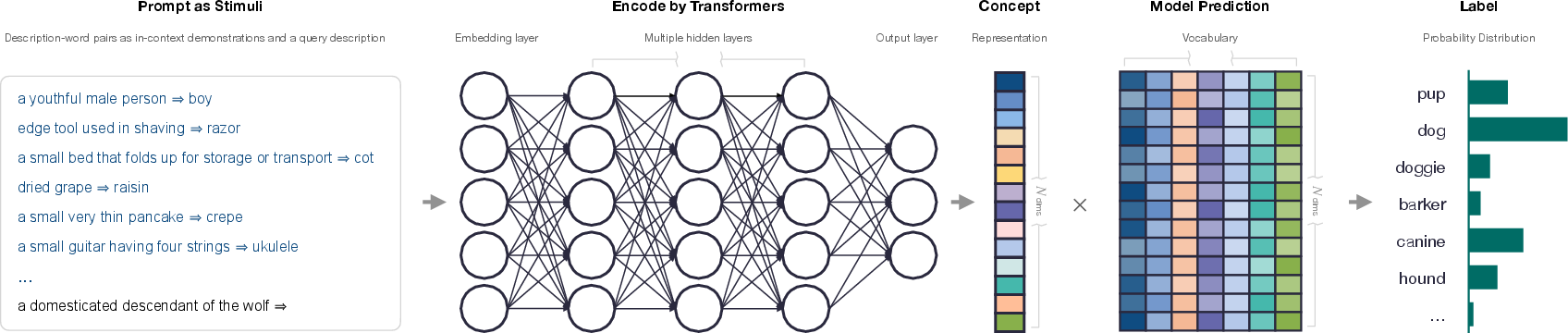
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored, framed so that future researchers can act on each point.
- Representation extraction: Sensitivity to where and how the “concept vector” is taken remains untested (e.g., layer choice, token pooling strategy, pre-/post-term hidden states, averaging across tokens vs CLS-style pooling); systematically map performance and alignment as a function of extraction method.
- Prompt/context dependence: Quantify how conceptual geometry varies with prompt templates, demonstration phrasing, ordering, number of shots, and instruction style; identify robust prompting regimes and failure modes.
- Cross-lingual generalization: Test whether the shared conceptual structure holds across languages and scripts, including zero-shot cross-lingual transfer and bilingual alignment; assess culture-specific differences in concept organization.
- Concept scope: Extend beyond primarily concrete object nouns to verbs, adjectives, events, relations, abstract/social concepts, and numeracy; measure whether convergence and human alignment persist for non-nominal concepts.
- Compositionality and logic: Evaluate concept combination and systematic generalization (e.g., conjunction/disjunction, negation, quantifiers, role-binding) using controlled semantic composition benchmarks rather than word-order perturbations alone.
- Novel “wug” concepts: Introduce entirely novel, invented concepts with definitional descriptions to test genuine concept induction beyond retrieval of known entities; assess retention and generalization of newly learned concepts.
- Polysemy and ambiguity: Stress-test disambiguation across multiple senses of a term and conflicting definitions; measure robustness to underspecified, noisy, or pragmatically rich descriptions.
- Leakage from definitional text: Control for explicit category labels and salient feature words in definitions (e.g., remove “fruit” from “apple” definitions) to determine how much category structure is induced vs directly stated.
- Dataset coverage and bias: Assess representational geometry under culturally diverse corpora, community-specific concept sets, and non-Western taxonomies; audit for stereotypes and socially salient biases encoded in the structures.
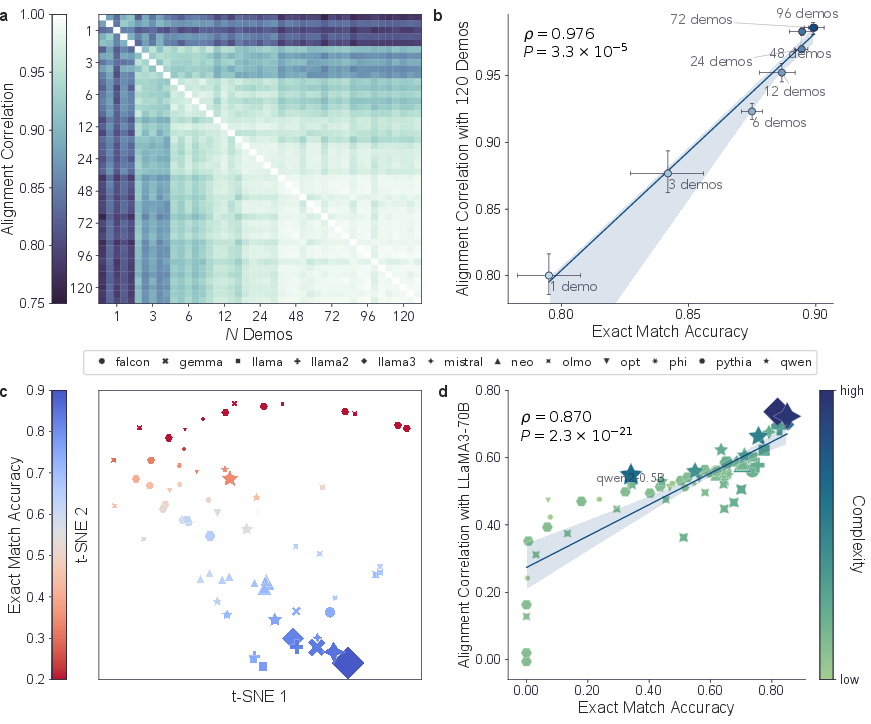
- Convergence claims: Use stronger alignment diagnostics beyond RSA (e.g., Procrustes alignment, CKA, geodesic distances, eigen-spectrum comparisons) to test whether convergence reflects true isomorphism vs trivial monotonic transforms.
- Source of convergence: Disentangle contributions of objective, data, and architecture by training ablations (same model on different corpora; different objectives on same corpus; masked-LM vs causal-LM; with/without RLHF/SFT) and measuring induced geometries.
- Size vs data quality: Separately manipulate model scale and curated training data quality to quantify their independent effects on conceptual alignment and human/brain prediction.
- Are concepts used in generation?: Causally test whether the extracted conceptual representations mediate downstream token generation (e.g., representation steering, causal mediation analysis, activation patching) vs being probe-only artifacts.
- Temporal dynamics: Examine time-resolved neural alignment (MEG/EEG/ECoG) to determine when concept-like information appears and how it unfolds relative to visual processing stages.
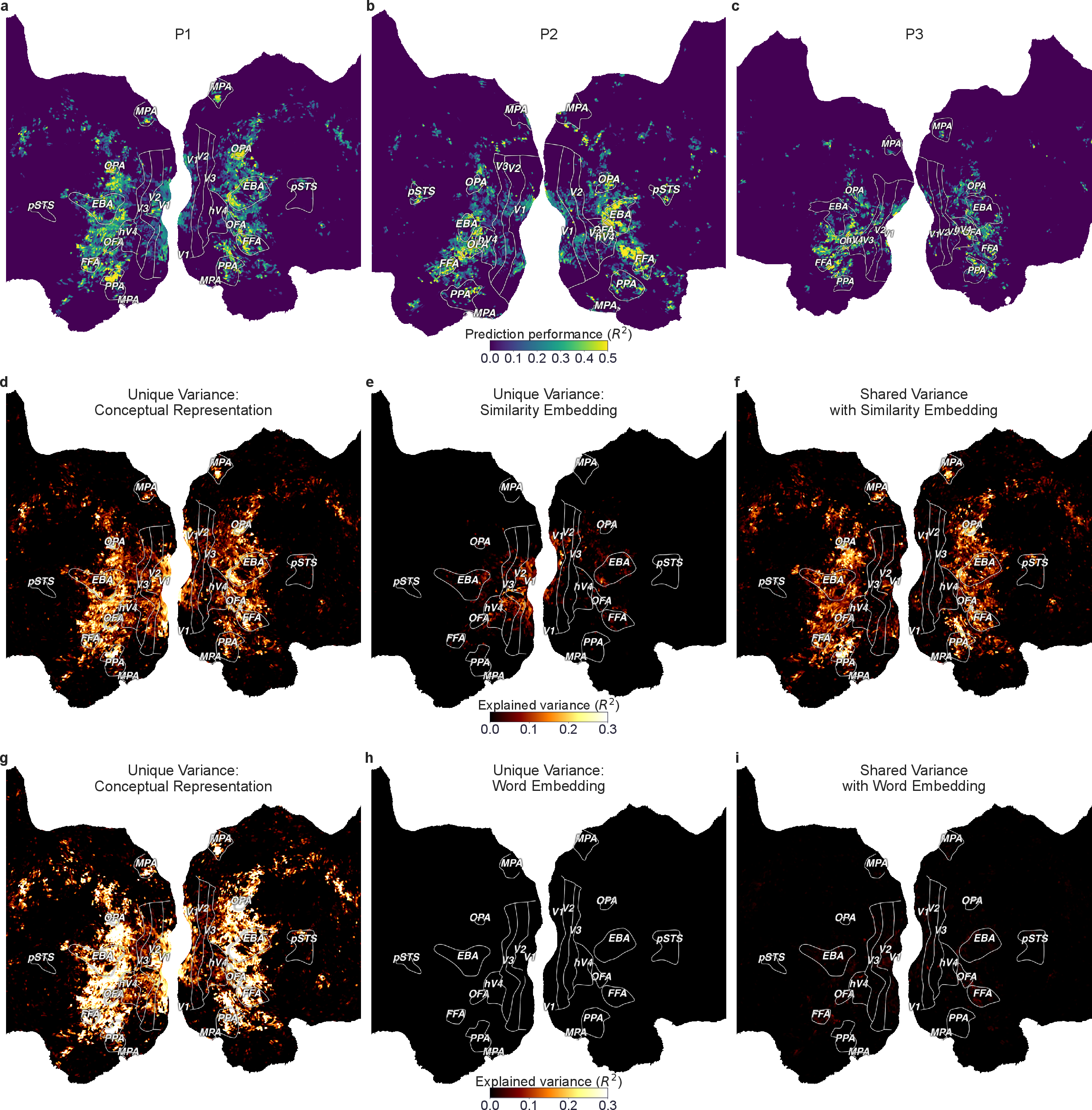
- Brain mapping baselines: Compare to state-of-the-art multimodal models (e.g., CLIP, OpenCLIP, vision transformers, multimodal LLMs) in variance partitioning to contextualize the advantage of language-only conceptual representations.
- Beyond visual cortex: Map to language, default-mode, and parietal networks involved in abstract semantic processing and control; test task-dependent modulations (e.g., active categorization vs passive viewing).
- Individual differences: Relate representational alignment to person-specific behavior and neural idiosyncrasies; test whether model–human alignment predicts individual similarity judgments or category typicality.
- Magnitude and ceiling of brain fits: Report absolute explained variance relative to noise ceilings and compare across regions; clarify how close the model comes to best-in-class encoding models for each area.
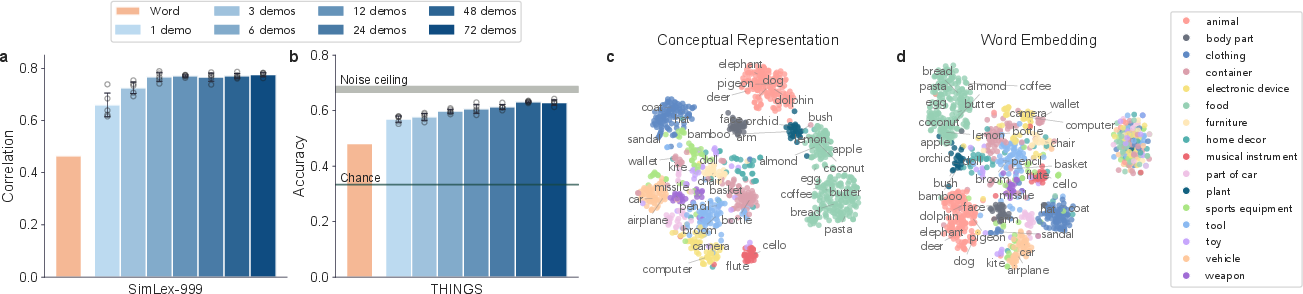
- Perceptual feature gaps: The study identifies color/texture/shape insufficiency; quantify how multimodal grounding (vision/audio/touch) changes conceptual geometry and brain alignment, and which modalities best fill these gaps.
- Category structure depth: Evaluate alignment with hierarchical taxonomies (WordNet, human taxonomies), typicality gradients, and basic-level effects; test whether hierarchical distances are preserved in geometry.
- Robustness to adversarial/noisy input: Stress-test with grammatical errors, contradictions, distractors, and domain shift to measure resilience of concept inference and stability of relational structure.
- Developmental plausibility: Compare learned structures to child-directed corpora and developmental trajectories; test whether smaller, developmentally plausible datasets induce human-like conceptual hierarchies.
- Efficiency and reuse: Determine whether concept vectors can be precomputed and reused across tasks without many-shot prompting, and how few demonstrations are needed to recover stable geometry.
- Dimensionality and interpretability: Estimate intrinsic dimensionality, identify interpretable axes (via sparse factors, concept activation vectors), and link axes to human-understandable features and neurosemantic factors.
- Generalization to other modalities: Test alignment with behavior and neural responses for auditory and olfactory concepts, and for cross-modal identity (e.g., same concept across text, image, and sound).
- Task breadth: Correlate conceptual alignment with performance on concept-heavy tasks (analogy, commonsense reasoning, causal judgments) to verify that representational quality predicts reasoning ability.
- Memorization controls: Use out-of-distribution definitional paraphrases and definitions explicitly held out from pretraining corpora to rule out lookup/memorization explanations.
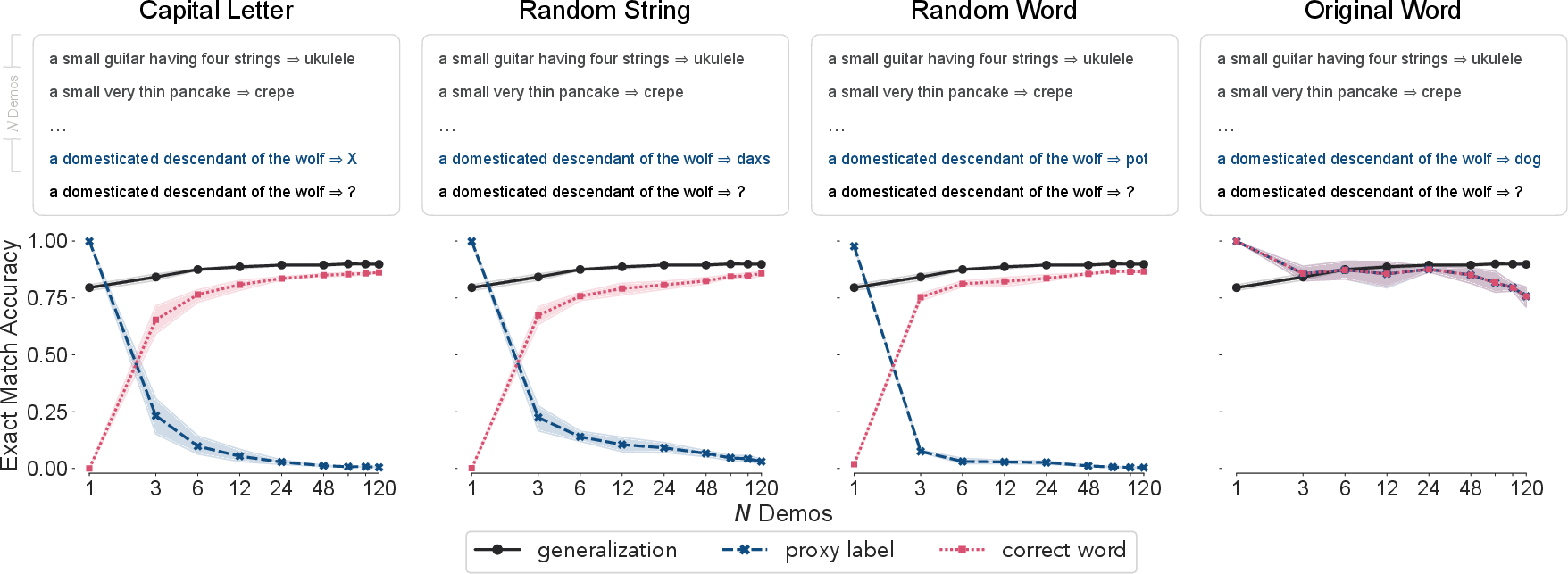
- Order/context interference: The study observes demonstration interference; systematically quantify recency/primacy and interference effects and relate them to human context effects in concept use.
- Stability under fine-tuning: Measure how instruction tuning, domain adaptation, and RLHF alter conceptual geometries and human/brain alignment; assess risks of representational drift or collapse.
Practical Applications
Immediate Applications
The findings and methods in this paper enable several practical uses that can be deployed with current LLMs by leveraging their emergent conceptual representations, reverse-dictionary probing, and strong alignment with human judgments.
- Human-centric reverse dictionary and word/term retrieval
- Sectors: education, publishing, productivity, accessibility
- Tools/products/workflows: “describe-and-find” features in writing apps and keyboards; dictionary/thesaurus plugins; assistive tools for aphasia or tip-of-the-tongue states
- Assumptions/dependencies: high-quality LLMs with strong in-context learning; carefully curated demonstration pairs; guardrails against non-human-like errors in ambiguous cases
- Concept-driven semantic search and retrieval across text and images
- Sectors: software, enterprise search, legal eDiscovery, customer support, media archives
- Tools/products/workflows: convert user descriptions to conceptual representations; similarity-based re-ranking; odd-one-out disambiguation in triage workflows; vector database integration
- Assumptions/dependencies: reliable conceptual embeddings derived from descriptions; domain-specific fine-tuning; evaluation against human relevance judgments
- Automated taxonomy/ontology induction and maintenance
- Sectors: e-commerce, libraries and archives, enterprise knowledge management
- Tools/products/workflows: prototype-based categorization; clustering product catalogs and metadata; ontology alignment using converged conceptual structures across LLMs
- Assumptions/dependencies: clean and sufficiently descriptive item text; consistent category definitions; human-in-the-loop verification to mitigate biases
- Descriptive product discovery (“describe the item” search)
- Sectors: retail/e-commerce
- Tools/products/workflows: map free-form customer descriptions to catalog concepts; similarity-based candidate suggestions; category-level disambiguation
- Assumptions/dependencies: robust handling of lay descriptions; catalog coverage and updates; safeguards against hallucinated items
- Clinical coding assistance from narrative to standardized concepts
- Sectors: healthcare (ICD, SNOMED, CPT coding)
- Tools/products/workflows: reverse-dictionary mapping from clinical notes to codes; similarity-based code suggestions; category-based validation workflows
- Assumptions/dependencies: domain-specific context demonstrations; privacy-preserving deployments; clinical validation and regulatory compliance
- Content moderation and compliance screening at the concept level
- Sectors: software platforms, policy compliance, ad tech
- Tools/products/workflows: concept similarity thresholds for sensitive topics; category separation for hate, violence, and adult content; gradient scales to rank severity
- Assumptions/dependencies: clearly defined policy taxonomies; ongoing bias audits; robust detection under paraphrase and adversarial wording
- Multilingual lexicography and sense disambiguation
- Sectors: education, language technology, publishing
- Tools/products/workflows: cross-lingual conceptual mapping; building reverse dictionaries for low-resource languages; sense selection via similarity rankings
- Assumptions/dependencies: multilingual LLM capability or bridging models; representative corpora; careful handling of cultural variation in concepts
- Cognitive neuroscience and psychology experiment support
- Sectors: academia, research institutes
- Tools/products/workflows: use LLM-derived conceptual representations for representational similarity analysis (RSA), behavioral prediction, and fMRI encoding baselines; rapid hypothesis testing
- Assumptions/dependencies: appropriate stimulus descriptions; replication across datasets; understanding that maps are strongest for higher-level visual areas
- Model auditing and explainability via conceptual maps
- Sectors: AI/ML operations, safety, compliance
- Tools/products/workflows: visualize category clusters and conceptual neighborhoods; monitor drift by comparing representation alignment across releases; cross-model interoperability checks
- Assumptions/dependencies: consistent evaluation protocols; documentation of demonstration contexts; acceptance of abstraction limits vs. word-form associations
- Creative analogy and ideation assistance
- Sectors: media, design, R&D, product development
- Tools/products/workflows: analogy search using inter-concept relationships; ideation prompts grounded in conceptual role semantics; structured exploration of conceptual neighborhoods
- Assumptions/dependencies: curated concept libraries; guardrails against misleading analogies; human oversight for novelty vs. accuracy trade-offs
Long-Term Applications
The paper’s evidence for convergent, human-like conceptual structures and biological plausibility suggests several future directions that require further research, scaling, or development.
- Concept-centric reasoning engines and neuro-symbolic pipelines
- Sectors: software, robotics, autonomous systems
- Tools/products/workflows: inference-time operations directly on conceptual embeddings; composition and planning over concepts; integration with symbolic logic
- Assumptions/dependencies: training incentives to use representations (not just tokens); benchmarks for compositional generalization and reasoning; robust out-of-domain performance
- Multimodal grounded AI aligned to conceptual spaces
- Sectors: robotics, autonomous vehicles, AR/VR
- Tools/products/workflows: align visual, auditory, and sensor modalities to the LLM conceptual space; concept-based controllers for embodied agents
- Assumptions/dependencies: large-scale multimodal training; standardized cross-modal evaluation; real-world grounding to mitigate perceptual gaps (e.g., color, texture)
- Brain–computer interfaces for semantic communication
- Sectors: healthcare, neurotech
- Tools/products/workflows: decode conceptual content from fMRI/EEG; concept-to-text communication aids for locked-in patients
- Assumptions/dependencies: improved signal-to-noise in neural recording; longitudinal clinical trials; ethical and privacy frameworks
- Cognitive diagnostics and monitoring of semantic deficits
- Sectors: healthcare, neuropsychology
- Tools/products/workflows: screen for semantic degradation (e.g., Alzheimer’s) via concept-similarity tasks; compare patient ratings against model-derived expectations
- Assumptions/dependencies: validated clinical norms; culturally sensitive instruments; explainability for clinical decisions
- Policy and standards for concept-level AI interoperability
- Sectors: policy, standards bodies, industry consortia
- Tools/products/workflows: shared “concept APIs” and benchmarks; alignment metrics based on representational convergence across models
- Assumptions/dependencies: cross-stakeholder governance; transparency on training data; procedures to audit fairness and bias at the concept level
- Cross-lingual and cross-cultural conceptual mapping
- Sectors: education, public policy, media analysis
- Tools/products/workflows: study how conceptual organization varies; monitor cultural shifts and framing in corpora; inform curriculum and translation standards
- Assumptions/dependencies: representative, high-quality multilingual datasets; robust methods for cultural nuance; ethical frameworks for interpretation
- Universal knowledge graph construction and ontology merging
- Sectors: enterprise data, scientific knowledge management
- Tools/products/workflows: build knowledge graphs anchored in converged conceptual spaces; automated ontology reconciliation across domains and languages
- Assumptions/dependencies: scalable data integration pipelines; human curation for edge cases; provenance and versioning standards
- Personalized curriculum design using conceptual feature scales
- Sectors: education, edtech
- Tools/products/workflows: map learning objectives onto conceptual features; adaptive progression across categories; concept-based assessment
- Assumptions/dependencies: pedagogy-aligned feature definitions; fairness and accessibility audits; teacher training and uptake
- Safety guardrails at the concept level
- Sectors: AI safety, compliance
- Tools/products/workflows: regulate model behavior by conceptual distance from harmful clusters; concept-aware defenses against prompt injection or adversarial phrasing
- Assumptions/dependencies: accepted ethical frameworks; reliable concept detection in real time; thorough red-teaming
- Scientific discovery and cross-domain analogy engines
- Sectors: research, pharma, materials science
- Tools/products/workflows: map concepts across disciplines; predict analogical transfers (e.g., mechanisms in biology ↔ engineering); hypothesis generation
- Assumptions/dependencies: integration with literature graphs and lab data; expert review loops; metrics for analogical validity and impact
Collections
Sign up for free to add this paper to one or more collections.

