- The paper shows that instruction-finetuning is the most potent predictor of alignment between LLM and human conceptual representations.
- It finds that increased MLP and attention head dimensionality significantly enhance models' ability to cluster semantic categories like humans.
- The analysis reveals that while larger model size and data exposure improve alignment, multimodal training does not yield significant benefits.
Uncovering the Computational Ingredients of Human-Like Representations in LLMs
Introduction
The study detailed in "Uncovering the Computational Ingredients of Human-Like Representations in LLMs" (2510.01030) targets a pressing question in the development of transformer-based LLMs: which computational constituents, including architectural variations, fine-tuning methods, and other components, are essential for enabling models to develop representations akin to human conceptual structures? The paper aims to elucidate these components by subjecting 77 diverse models to a triplet similarity task, enabling a comparative analysis between human and model representations. This exploration is especially critical as existing LLM benchmarks inadequately assess representational alignment, potentially misguiding the model development trajectory that seeks a closer mimicry of human-like cognitive processes.
Methodology
A comprehensive methodology underlies this research, utilizing the THINGS database to form a varied set of object concepts for evaluation through triplet similarity tasks.
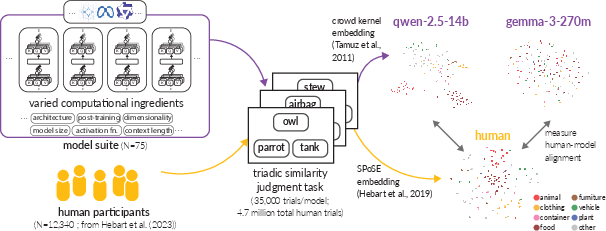
Figure 1: Method for estimating human-model alignment. We collected 35k triplet similarity judgments from each of the 77 models in our suite.
The researchers evaluated models across several dimensions of computational variations, including but not limited to instruction-fine-tuning, model architecture, and embedding dimensionality. Key tasks involved assessing how these components influenced the alignment with human semantic structures, derived from human triplet judgments processed through established embedding techniques like SPoSE.
Results
The findings indicate significant insights into various factors affecting model-human alignment:
- Instruction-Finetuning: This emerged as the most potent predictor of alignment, suggesting that models refined through instructions are better equipped to cluster semantic categories akin to human cognitive patterns (Figure 2).
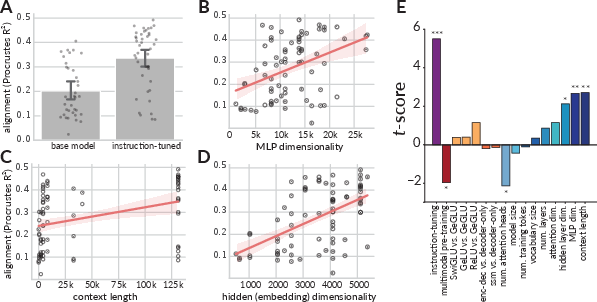
Figure 2: Computational ingredients predictive of human model alignment. A., B., C., and D. show the relationship between instruction-tuning, MLP dimensionality, context length, and embedding dimensionality on Procrustes R².
- Architectural Dimensionality: Both MLPs and attention heads' dimensionality were strongly correlated with alignment, indicating that the expressive power of larger latent spaces contributes significantly to developing human-like conceptual representations.
- Model Size and Data Exposure: Consistent with scaling laws, models with broader data exposure and larger structures inherently demonstrated better alignment with human conceptual models.
- Multimodal Training: Contrary to certain multimodal hypotheses, the study found no significant impact of multimodal training on alignment, challenging some prevailing assumptions about its necessity for enhanced representational accordance with human cognition.
Discussion
The analysis posits that focusing on representational alignment provides a pathway towards developing models that generalize across tasks and mimic human-like error patterns. The findings underscore the importance of specific computational ingredients in achieving this alignment, suggesting a reorientation of LLM development priorities towards enhancing these aspects. Additionally, the mixed-effects regression models employed highlight the hierarchical influence of ingredients, providing a nuanced context to the interdependencies among model components and their collective influence on alignment metrics.
The study further extrapolates the implications of these findings: benchmarks like BigBenchHard, which emphasize domain-general knowledge, correlate most closely with representational alignment. This insight could inform future benchmark designs aimed at capturing nuanced cognitive mimicry in LLMs.
Conclusion
This paper provides a comprehensive examination of the individual and collective impacts of various computational ingredients on the alignment of LLM representations with human conceptual structures. By identifying instruction-finetuning and dimensionality of architectures as critical factors, the research offers a substantive contribution to designing more cognitively aligned LLMs. Future directions could involve deeper explorations into how these findings might scale with emerging architectures and data types, continually refining the quest for human-like AI cognition.