- The paper introduces a novel black-box method for uncertainty quantification in LLM evaluations using confusion matrices built from token probabilities.
- The methodology involves biased assessments and multiple inferencing calls to generate uncertainty labels that correlate with prediction accuracy.
- Experimental results show low uncertainty labels yield higher accuracies across datasets, proving the approach's potential in critical domains like law and healthcare.
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
The research focuses on a novel method for uncertainty quantification applied to the "LLM-as-a-Judge" framework. This method has been designed to improve the reliability of evaluations made by LLMs. Its objective is to provide a black-box uncertainty quantification that can be applied without requiring access to the LLM's internal states.
Introduction to Uncertainty Quantification
The paper addresses a challenge within LLM-as-a-Judge applications, specifically the need for robust uncertainty quantification. While LLMs are adept at generating evaluations across diverse tasks, their judgments often lack alignment with human assessments. Consequently, this research seeks to bridge this gap by introducing a method that quantifies uncertainty through the interaction of generated assessments and token probabilities.
The proposed approach involves evaluating relationships within confusion matrices built from token probability distributions. These matrices serve as the basis for generating uncertainty labels and offer insights into the reliability of LLM decisions.
Confusion-Based Uncertainty Framework
The method proposed comprises several steps, beginning with biased assessments generated for each output option under the guise that the option is correct.

Figure 1: A biased assessment prompt. The LLM is prompted to assess a response under the assumption that a particular output option is correct.
The assessments are then used to construct prompts that create the confusion matrix. The architecture requires multiple inferencing calls—specifically, n2 to handle combinations of outcome labels.
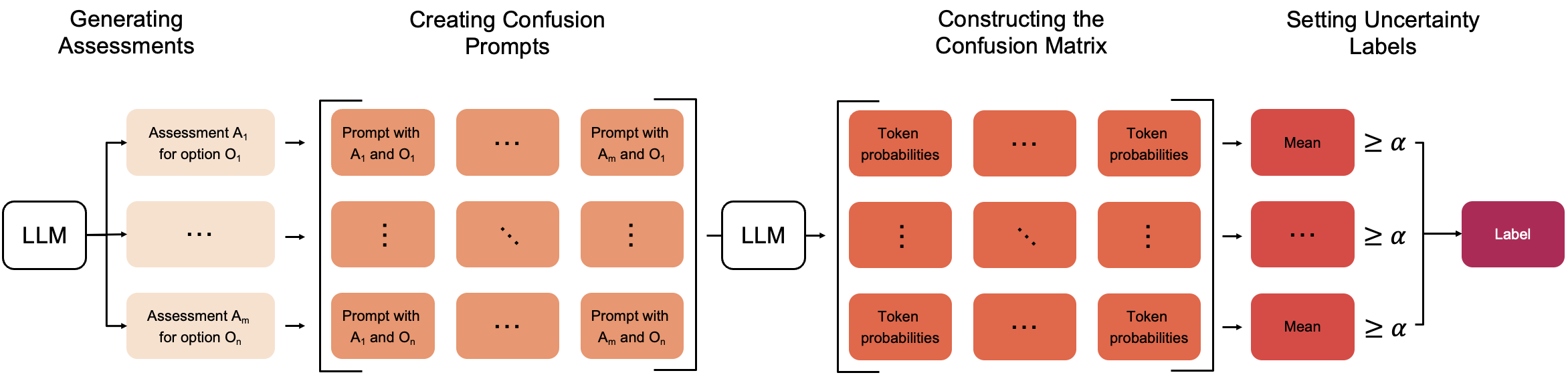
Figure 2: Method Overview. The method includes stages leading to an uncertainty label, derived from token probabilities in a confusion matrix. α denotes the threshold.
The confusion matrix is essential to the process, and uncertainty is designated as high or low. This designation helps in predicting the accuracy of evaluations, such that if a single row in the matrix consistently exhibits high probabilities across all assessments, the uncertainty is considered low.
Experimental Evaluation
The efficacy of this method was tested on several datasets, including TruthfulQA, FeedbackQA, and others, using various LLM architectures to gauge performance variability. Results indicated that low uncertainty labels highly correlated with accurate predictions. Specifically, options flagged as low uncertainty consistently surpassed baseline accuracy metrics.
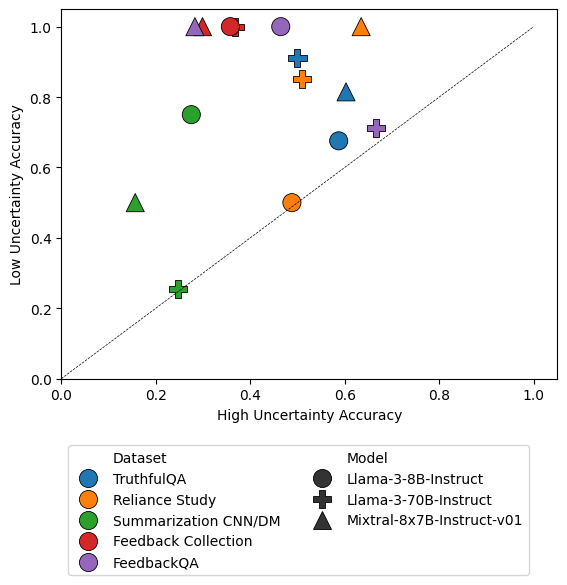
Figure 3: Accuracy comparison of options labeled low versus high uncertainty across datasets and models.
A notable observation is the relationship between uncertainty thresholds and accuracy balance, demonstrated by grid search optimizations across datasets.
Practical Implications and Future Directions
The method is positioned to significantly enhance the application of LLM-as-a-Judge frameworks by providing a robust mechanism for identifying unreliable evaluations. This is particularly advantageous in high-stakes domains requiring stringent accuracy levels, such as legal or medical fields.
Looking forward, the potential to derive even greater insights from confusion matrices is promising. Future research could aim at developing a singular uncertainty score directly from these matrices, which could refine both predictive and decision-making capabilities.
Conclusion
This work introduces a scalable and effective method for uncertainty quantification in LLM evaluations. It reliably predicts the accuracy of LLM outputs by leveraging confusion matrices and token probabilities. While there are inherent computational demands, the method's benefits underscore its applicability in enhancing the trustworthiness of LLM evaluations. Further advancements, such as threshold tuning and model training based on confusion data, hold the potential for even broader applications and performance enhancements in AI systems.