- The paper demonstrates that language models represent numbers as digit sequences in base 10, which explains systematic arithmetic errors.
- The authors apply probing experiments and causal interventions to uncover per-digit representations in hidden states of LLMs.
- Findings suggest that circular digit embeddings provide numerical resilience, offering pathways to enhanced LLM arithmetic reasoning.
LLMs Encode Numbers Using Digit Representations in Base 10
Introduction
The paper "LLMs Encode Numbers Using Digit Representations in Base 10" investigates numerical processing in LLMs, addressing the persistent issue of LLMs making systematic errors in arithmetic tasks. The study hypothesizes that these errors originate from how LLMs internally represent numbers—not as singular numeric entities but as digit-wise representations in base 10. Through probing experiments and interventions, the authors reveal the underlying mechanisms of number representation in models such as Llama 3 8B and Mistral 7B.
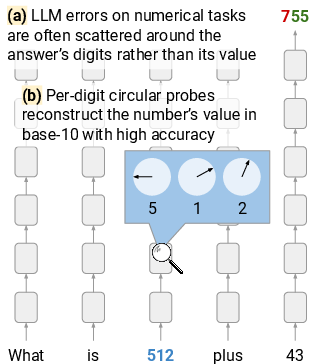
Figure 1: An illustration of key findings, suggesting that LLMs represent numbers on a per-digit base-10 basis.
Model Errors on Numerical Tasks
The analysis begins by examining error patterns in LLM arithmetic tasks. Models like Llama 3 8B display errors distributed across digit positions in multi-operand addition tasks and number comparison tasks. Specifically, errors in addition tasks tend to result in outputs with misplaced digits, demonstrating higher string-similarity to the correct result rather than proximity in value space.
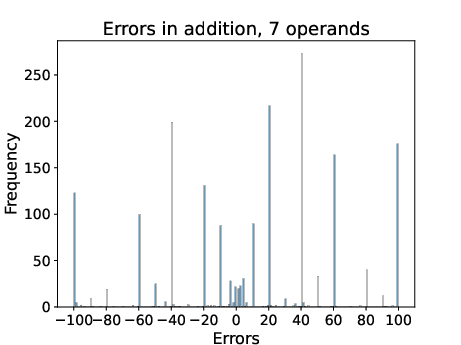
Figure 2: Error distribution in 7 operand addition.
Hypothesis Testing: Probing and Causal Interventions
To substantiate the hypothesis of digit-wise base-10 representation, the authors employed circular probing techniques. These probes successfully extract digit values from hidden states across various layers in both models, revealing a significant circular pattern indicative of base-10 digit representations. Notably, probes could decode digit values with high accuracy, contrary to value space expectations, which would predict a linear correlation.
The causal intervention experiment fortified the hypothesis: manipulating digit representations at specific layers resulted in predictable changes to the output digits, demonstrating the importance of the circular digit-wise representation.
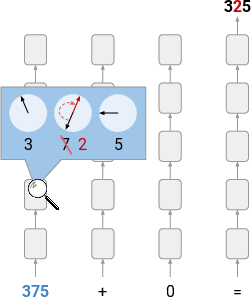
Figure 3: Illustration of intervention on number representations via circular per-digit probes in base 10.
Visualizing Number Representations
Principal Component Analysis (PCA) of hidden states visualizes these digit-wise representations. Figures project hidden states of numbers onto principal components, revealing circular patterns. Layer-by-layer analysis confirms that these circular embeddings exist within LLMs, underscoring digit-based encoding.
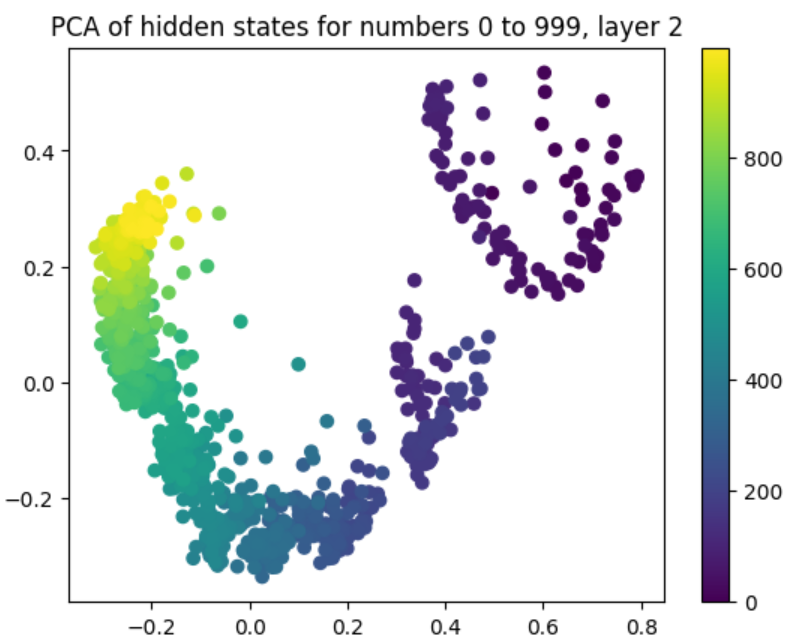
Figure 4: Visualization of hidden states for natural number tokens in layer 2 of Llama 3 8B, projected onto their top two principal components.
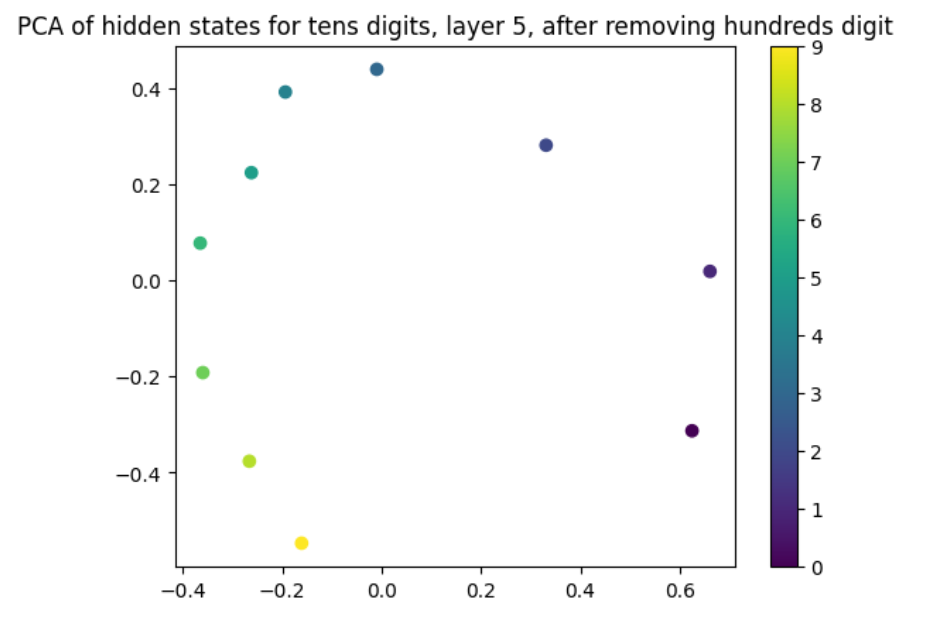
Figure 5: Averaged hidden states projected onto top principal components, grouped by tens digit.
Discussion and Implications
The digit-wise encoding in LLMs could confer resilience against computational noise, enhancing arithmetic stability in operations. Despite linear tokenization expectations, LLMs seem to utilize digit-based representations—likely a learned bias from prevalent numerical formats in training data. The findings open pathways for augmenting numeric reasoning capabilities in future LLM architectures and provide a foundation for additional interpretability research concerning mathematical operations within LLMs.
Conclusion
This research redefines understanding of numerical encoding in LLMs, revealing digit-wise base-10 structures. Such insights have profound implications for developing more accurate LLMs capable of complex numerical reasoning tasks. Future research should explore extending digit-centric representations to fractions and other numerical concepts.
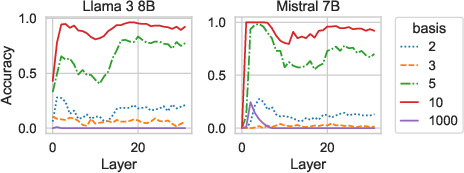
Figure 6: Accuracy of circular probes in different bases across layers in Llama and Mistral.

