- The paper presents a chaining strategy where LLM ensembles sequentially label data based on computed confidence scores to enable dynamic routing.
- It leverages a rank-based ensemble mechanism to select the final prediction, resulting in improved F1 metrics and reduced output variance across tasks.
- The method achieves up to a 90-fold cost reduction while maintaining high accuracy in stance, ideology, and misinformation detection.
LLM Chain Ensembles for Scalable and Accurate Data Annotation
Methodological Framework
The paper "LLM Chain Ensembles for Scalable and Accurate Data Annotation" (2410.13006) presents a systematic approach for utilizing sequential LLM ensembles (chains) to achieve scalable, robust, and cost-effective text data annotation. The proposed methodology sequentially routes data through a series of pre-trained LLMs, leveraging a computed confidence metric to determine whether specific data points should be retained for labeling by the current model or forwarded to a subsequent one. Each LLM in the chain operates as an independent classifier link, assigning labels and associated confidence scores, with final label selection based on a rank-based ensemble procedure.
This chaining architecture sharply contrasts with traditional prompt engineering and ensemble methods where each model processes all data points independently, resulting in steep computational and financial costs. Instead, the sequential routing ensures that only a fraction of the data reaches the most expensive LLMs, dramatically reducing token utilization. The system diagram succinctly captures model arrangement, routing logic, and ensemble decision mechanism.
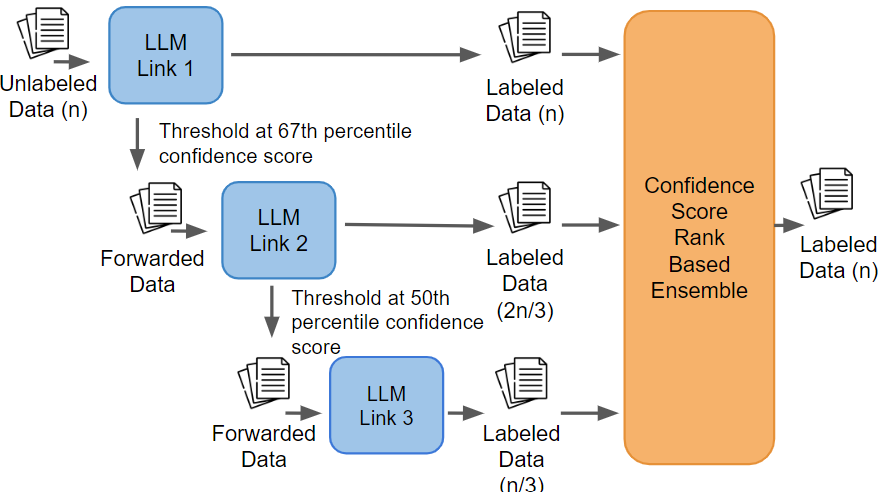
Figure 1: System diagram illustrating chaining methodology for routing data across sequential LLMs using a computed confidence metric, with rank-based ensemble for final labeling.
Confidence-Guided Forwarding and Rank-Based Ensembling
Central to the chain ensemble methodology is the robust estimation and utilization of model confidence. The authors formalize a confidence score derived from the gap between the top two log probabilities assigned to candidate class tokens, efficiently capturing prediction certainty. At each chain link, only the subset of data exceeding parameterized percentile thresholds of confidence are retained; the remainder is routed downstream.
Empirical analysis demonstrates that stratifying data by confidence effectively separates "easy" cases—handled in early, cheap links—from harder instances requiring more powerful models. The distribution of confidence scores by correctness further validates the forwarding strategy.
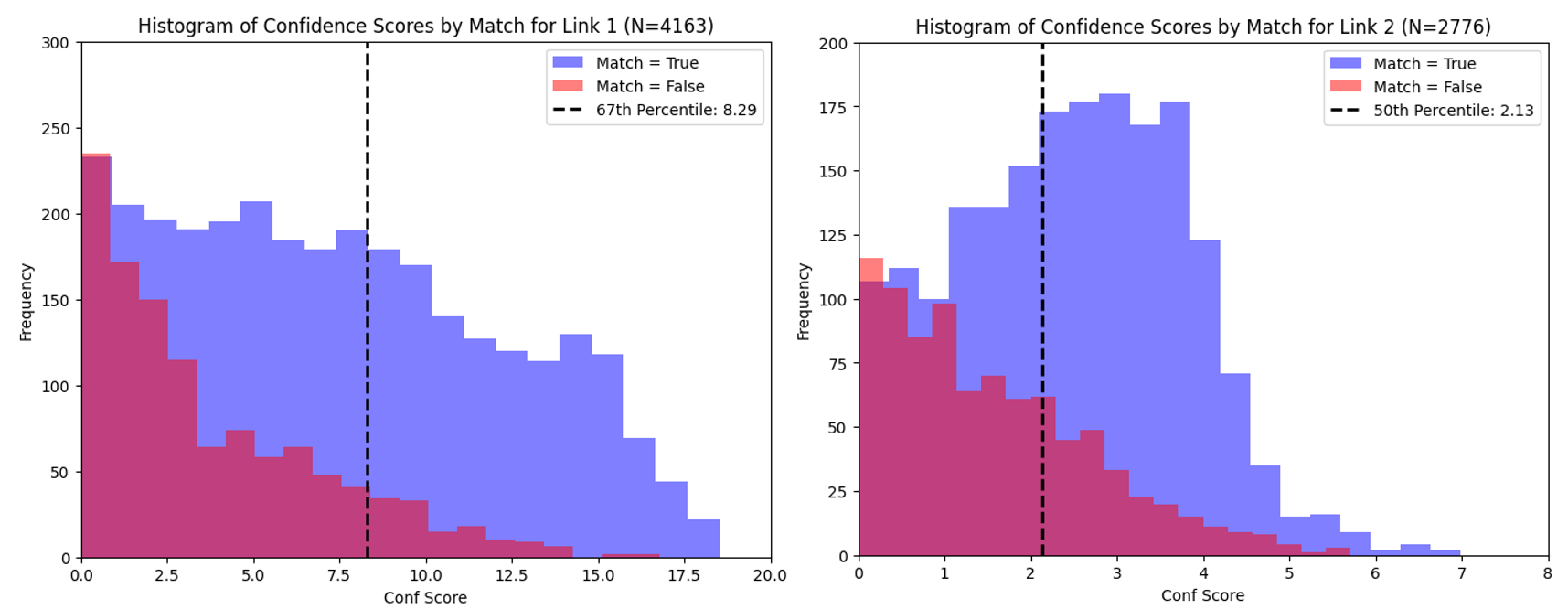
Figure 2: Confidence score distributions at chain links 1 and 2 for stance detection; thresholding enables optimal routing of difficult samples.
The final prediction for each data point is selected by maximizing the normalized confidence rank across all models that process it, allowing the system to benefit from models with instance-specific comparative advantages. This ensemble mechanism achieves performance consistency, mitigates negative impacts of weak LLMs, and obviates the need for complex, task-specific routing models.
Empirical Evaluation
The methodology is exhaustively evaluated on three classification tasks: stance detection, ideology detection, and misinformation detection. Five LLMs of varying scale and origin—LLAMA 3.1 (8B), Flan-UL2, Mistral-7b, Phi3, and GPT-4o—form chains up to length four, tested across all valid permutations. Prompting is tightly controlled, enforcing label restrictions for zero-shot settings.
Results are compelling. The chain ensemble consistently exceeds the average F1 performance of both the best single LLM and simple forwarding (last-link labeling), while substantially reducing standard deviation, indicating increased robustness. Notably, chaining yields up to 90-fold cost reduction, as only the lowest-confidence strata access the most costly commercial models (GPT-4o), and token budgets are minimized via concise one-word responses.
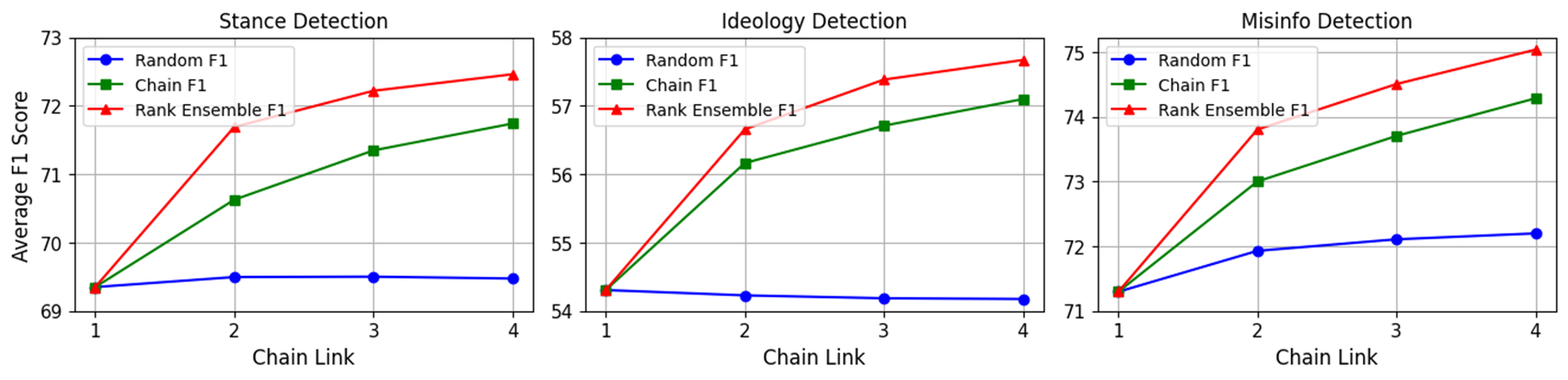
Figure 3: F1 performance by chain link for stance, ideology, and misinformation tasks; rank-based ensembling delivers marked improvements over random forwarding and single-model baselines.
Task-Specific Outcomes
- Stance Detection: Full chain ensembles reach best macro-F1 of 78.2—surpassing established zero-shot benchmarks in SemEval-16. Chains mitigate the effect of weak models (e.g., Mistral-7b).
- Ideology Detection: Production chain ensembles yield F1 improvements of 2.23 versus best individual models and halve F1 variance.
- Misinformation Detection: Ensemble method improves F1 by 1.89 over top base model and reduces variance by a factor of three, ensuring consistent accuracy.
These results hold without reliance on chain-of-thought or comparable advanced prompting schemes; in all cases, data is labeled with constrained outputs, further enhancing throughput and reliability.
Implications and Potential Extensions
This study significantly raises the bar for practical LLM-driven data annotation. By decoupling reliance on prompt engineering and circumventing exhaustive per-instance inference in all ensemble models, the chain ensemble is highly scalable for computational social science, NLP production pipelines, and real-world scenarios with variable annotation difficulty and growing dataset sizes.
The findings challenge the presupposition that individual LLMs or monolithic ensemble architectures are generally optimal for annotation tasks. The demonstrated ability to dynamically route instances based on estimated hardness, minimize computational expenditure, and sustain high or improved classification metrics suggests that chaining could be adapted to a broader range of tasks, including multi-label classification, entity recognition, or weak supervision aggregation.
Theoretically, as LLM architectures diversify and model APIs proliferate, the chain ensemble provides a robust template for integrating heterogeneous models into adaptive systems. Dynamic adjustment of confidence thresholds, online routing policies, and hierarchical chain learning—even in unsupervised or semi-supervised modalities—are promising avenues for future work.
Conclusion
The LLM chain ensemble method achieves cost-effective, high-performance zero-shot annotation across varied text classification tasks. Leveraging sequential confidence-guided routing and rank-based ensembling, the system demonstrates strong empirical gains—improved F1, reduced output variance, and drastic cost savings—while mitigating risks associated with uncertain or weak individual models. This study provides a concrete foundation for scalable AI annotation in data-rich, rapidly evolving domains and opens pathways for further algorithmic innovation in multi-model orchestration.