- The paper demonstrates that a uniform RAG framework enables controlled evaluation of 24 LLMs using culturally relevant, multilingual patient queries.
- It finds that even smaller, instruction-tuned models can outperform larger counterparts while revealing significant performance drops for non-English queries.
- The study underscores the importance of locally sourced, doctor-verified datasets and combined human/LLM evaluations for reliable healthcare chatbot deployment.
Comprehensive Evaluation of RAG Models for Multilingual Health Chatbots: Insights from HEALTH-PARIKSHA
Introduction
The HEALTH-PARIKSHA study presents a rigorous evaluation of 24 LLMs in a real-world healthcare chatbot scenario, focusing on Indian English and four Indic languages. The evaluation leverages a uniform Retrieval-Augmented Generation (RAG) framework, ensuring comparability across models. The dataset comprises authentic patient queries, including code-mixed, culturally specific, and non-native English utterances, with ground-truth responses verified by medical professionals. The study addresses critical gaps in multilingual LLM evaluation, particularly the limitations of translated benchmarks and the need for culturally grounded datasets.
Methodology
Dataset and Knowledge Base
The evaluation dataset consists of 749 patient queries and corresponding doctor-verified answers, collected from a deployed medical chatbot (HEALTHBOT) at a major urban hospital in India. Queries span Indian English, Hindi, Tamil, Telugu, and Kannada, with substantial representation of code-switching, misspellings, and culturally relevant content. The knowledge base (KB) comprises curated medical documents, chunked and embedded using TEXT-EMBEDDING-ADA-002, with top-3 relevant chunks retrieved for each query.
Model Selection and RAG Framework
Twenty-four models were evaluated, including proprietary (GPT-4, GPT-4o) and open-weight multilingual and Indic LLMs. All models operated within an identical RAG pipeline, receiving the same KB chunks and prompts. The prompt design prioritized the latest KB updates and enforced response language constraints, ensuring fair and controlled comparison.
Evaluation Metrics
Four metrics were defined in consultation with domain experts:
- Factual Correctness (FC): Alignment with verified facts, critical for medical reliability.
- Semantic Similarity (SS): Core meaning and factual alignment with ground-truth.
- Coherence (COH): Logical flow and organization of the response.
- Conciseness (CON): Efficiency and brevity without loss of information.
Metric weights were assigned by medical experts, with FC and SS prioritized. Both LLM-based (GPT-4o) and human evaluations were conducted, with direct comparison of rankings and percentage agreement.
Results
The QWEN2.5-72B-Instruct model achieved the highest aggregate scores across metrics for English queries, outperforming even proprietary models in several cases. Notably, some smaller models (e.g., PHI-3.5-MoE-Instruct) outperformed larger models such as Meta-Llama-3.1-70B-Instruct, which exhibited prompt regurgitation and lower task-specific adaptation.
For non-English queries, performance dropped significantly, especially in Factual Correctness. Instruction-tuned Indic models did not consistently outperform general multilingual models on Indic queries, contradicting expectations. The AYA-23-35B model, with manually curated instruction data, was a notable exception for Hindi.
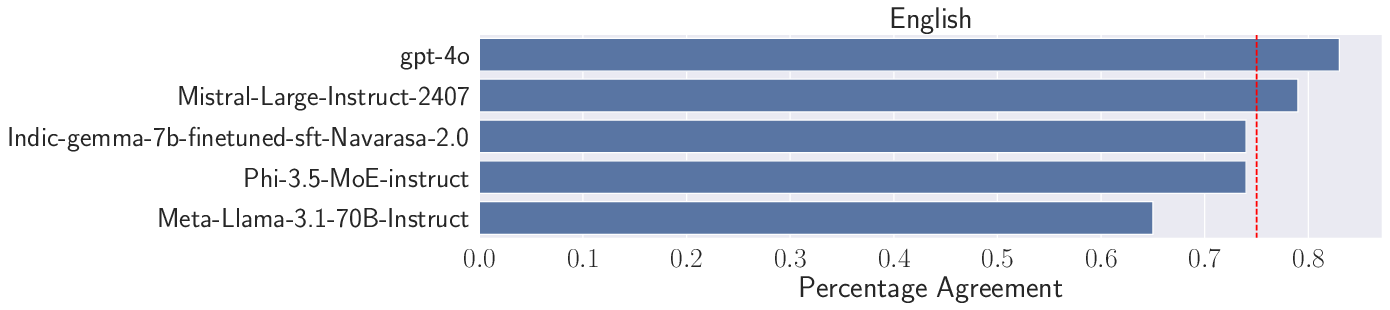
Figure 1: Percentage Agreement between human and LLM-evaluators for English queries, with the red line indicating the average agreement across models.
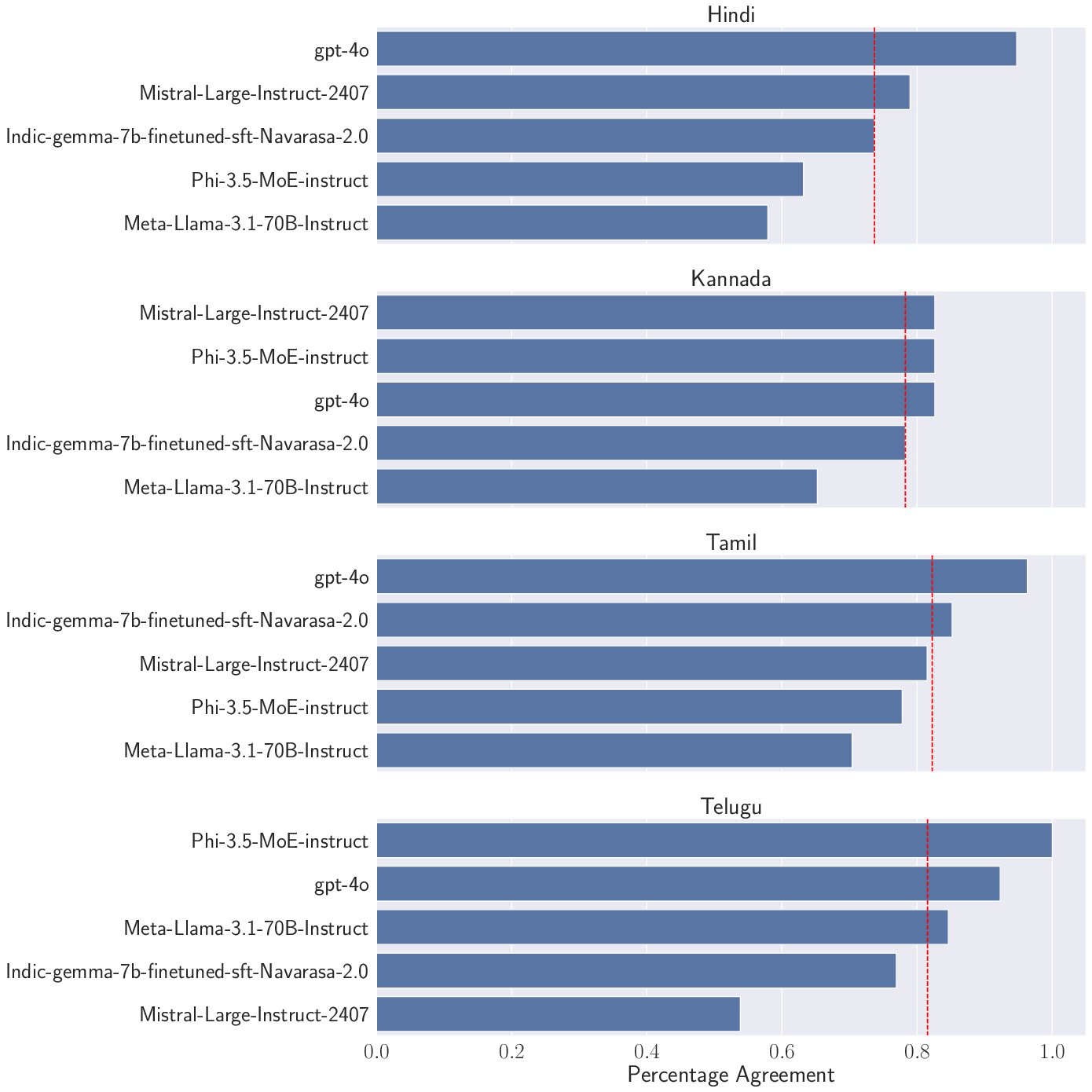
Figure 2: Percentage agreement between human and LLM-evaluators for Indic languages, demonstrating robust alignment except for Telugu.
Human vs. LLM-Based Evaluation
Human and LLM-based evaluations showed high agreement (average >0.7) for Semantic Similarity across most languages and models, validating the reliability of LLM-as-a-judge for reference-based metrics. However, discrepancies emerged for certain models and languages, underscoring the need for caution in multilingual settings.
Qualitative Analysis
Models struggled with misspelled queries and less common code-mixed terms, often failing to recover intended meaning. Indian English colloquialisms and culturally specific queries (e.g., dietary restrictions, travel to native place) elicited diverse responses, with some models providing contradictory or context-insensitive answers. Medication-specific queries revealed a tendency for models to hallucinate or overgeneralize, with only partial alignment to ground-truth.
Discussion
Model Suitability and RAG Adaptation
The wide variance in model scores highlights that not all LLMs are suitable for deployment in healthcare chatbots, especially in multilingual and culturally diverse contexts. Larger parameter count does not guarantee superior performance; adaptation to RAG and domain-specific data is critical. Instruction-tuned models based on synthetic translation data are insufficient for complex, real-world RAG tasks.
Multilingual Challenges and Dataset Contamination
Factual Correctness is consistently lower for non-English queries, raising concerns for medical reliability in multilingual deployments. The study's use of an uncontaminated, locally sourced dataset is a methodological strength, avoiding the pitfalls of benchmark leakage and translation artifacts.
Human Evaluation and Metric Design
Strong alignment between human and LLM-based evaluation for Semantic Similarity supports the use of LLM-as-a-judge for scalable assessment, but reference-free metrics and low-resource languages require further human oversight. The metric design, with explicit scoring rubrics and expert weighting, provides a robust framework for future evaluations.
Implications and Future Directions
The findings have direct implications for the deployment of LLM-powered health chatbots in multilingual settings:
- Model Selection: Careful benchmarking in target languages and cultural contexts is essential; parameter count and instruction tuning alone are insufficient.
- Dataset Design: Locally grounded, non-translated datasets are necessary for realistic evaluation and model adaptation.
- Evaluation Frameworks: Combined human and LLM-based evaluation, with explicit metric design, should be standard practice.
- RAG Optimization: Future work should explore domain-adaptive retrieval strategies and fine-tuning on authentic, code-mixed, and culturally specific data.
The study also motivates the development of more robust LLM evaluators, expansion of human evaluation to additional metrics, and broader coverage of languages and medical domains.
Conclusion
HEALTH-PARIKSHA provides a comprehensive, controlled evaluation of RAG-enabled LLMs for health chatbots in a real-world, multilingual Indian context. The results demonstrate significant disparities in model performance, especially for non-English queries, and challenge assumptions about the efficacy of instruction-tuned Indic models. The study establishes a rigorous methodology for future multilingual LLM evaluation and underscores the necessity of culturally and linguistically grounded datasets for reliable AI deployment in healthcare.