- The paper presents SALAD, a model that uses per-token latent diffusion to perform zero-shot text-to-speech synthesis with improved intelligibility.
- The method integrates semantic and acoustic token prediction in both two-stage (T2S and S2A) and end-to-end (T2A) frameworks, ensuring high quality synthesis.
- Future work is aimed at refining multimodal integration and adaptive diffusion strategies to further boost performance in continuous speech synthesis.
Continuous Speech Synthesis using Per-Token Latent Diffusion
Introduction
The paper introduces SALAD, a model innovatively designed for zero-shot text-to-speech (TTS) synthesis leveraging per-token latent diffusion in continuous modalities. This synthesis method aims to outperform traditional autoregressive (AR) modeling techniques that rely on discrete representations. By integrating semantic tokens with a continuous diffusion model, SALAD addresses critical challenges in speech synthesis, including variable output length and enhanced intelligibility without sacrificing audio quality or speaker similarity.
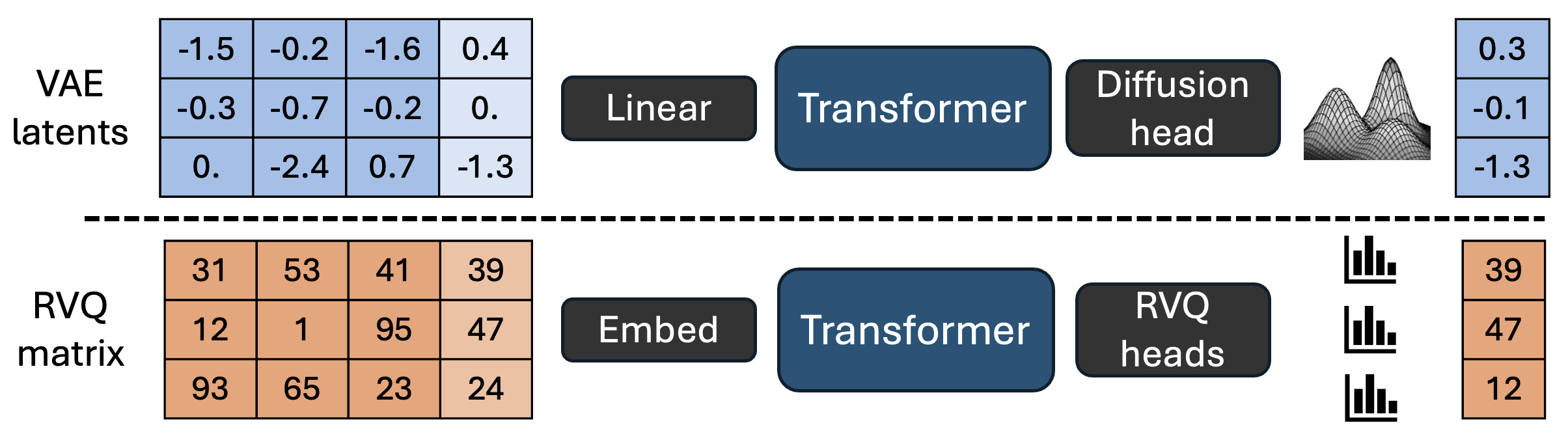
Figure 1: Continuous vs. discrete modeling.
Methodology
Per-Token Latent Diffusion Model
SALAD employs per-token latent diffusion which adapts continuous diffusion models like those used in image generation to synthesize speech. Unlike conventional diffusion models that concurrently denoise complete sequences, this model denoises independently, enabling variable-length speech generation. The diffusion head refines predictions through contextual token vectors derived from semantic information and speaker prompts.
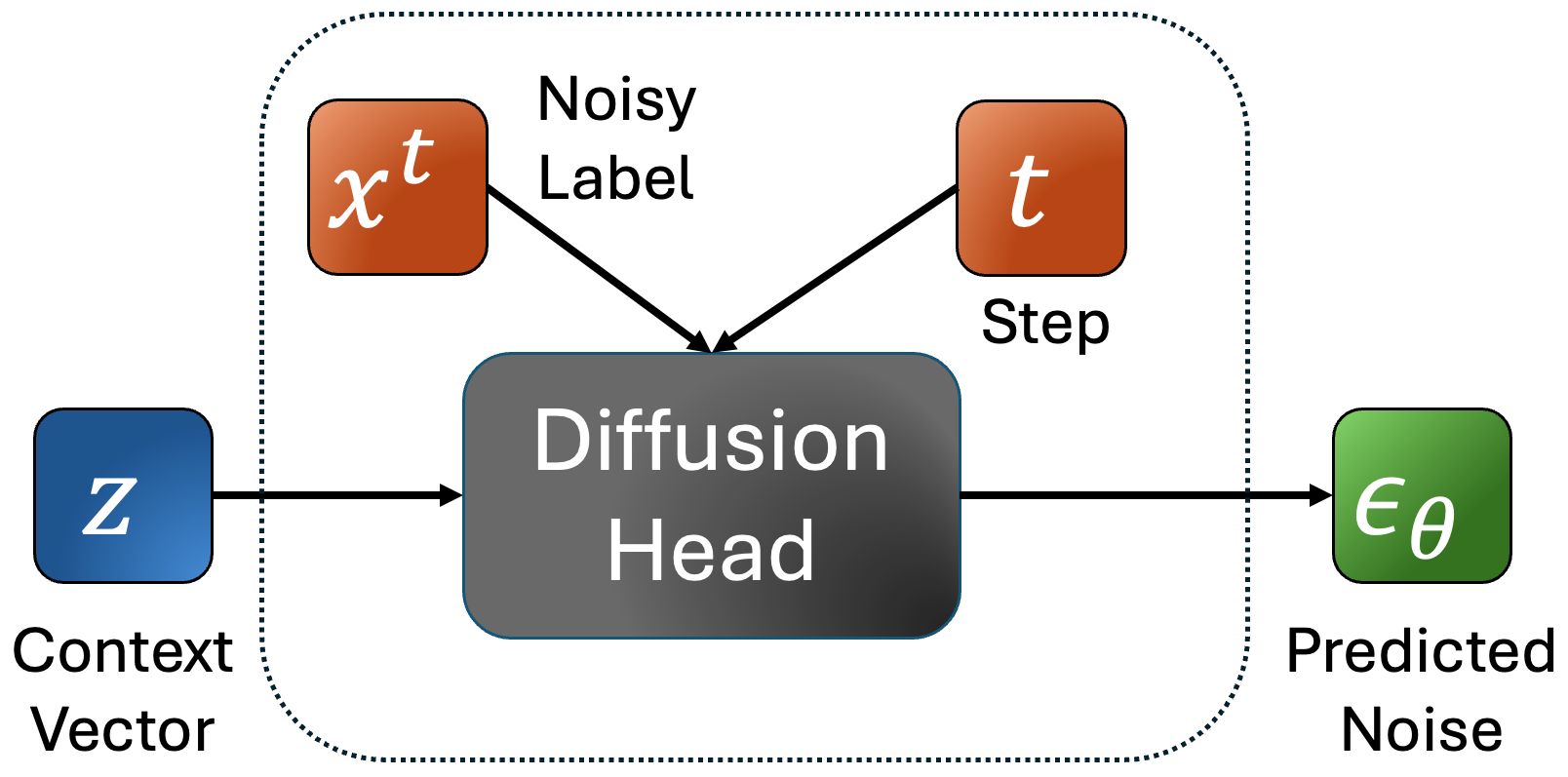
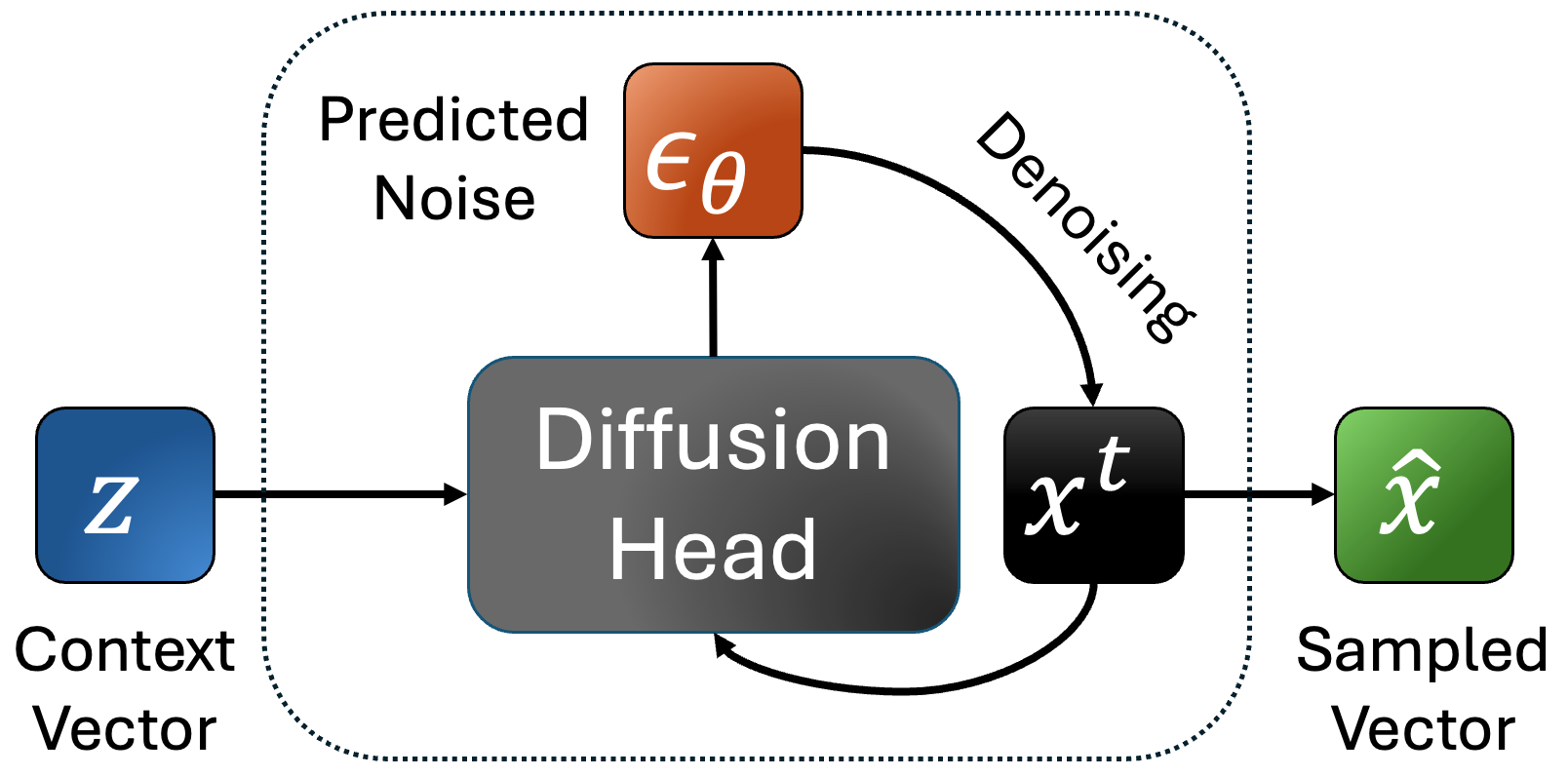
Figure 2: Training process of the diffusion head.
SALAD Variants
- Semantic to Acoustic (S2A): Operates through two sub-models: a text-to-semantic (T2S) and a semantic-to-acoustic (S2A) model. The T2S model predicts semantic tokens from text, which guides the S2A model to predict acoustic tokens, employing either AR or non-AR techniques powered by MaskGIT.
- Text to Acoustic (T2A): An end-to-end model bypassing separate semantic predictions, integrating semantic tokens as an auxiliary for contextual relevance and an inferred stopping condition.

Figure 3: Synthesis using Semantic-to-Acoustic models.
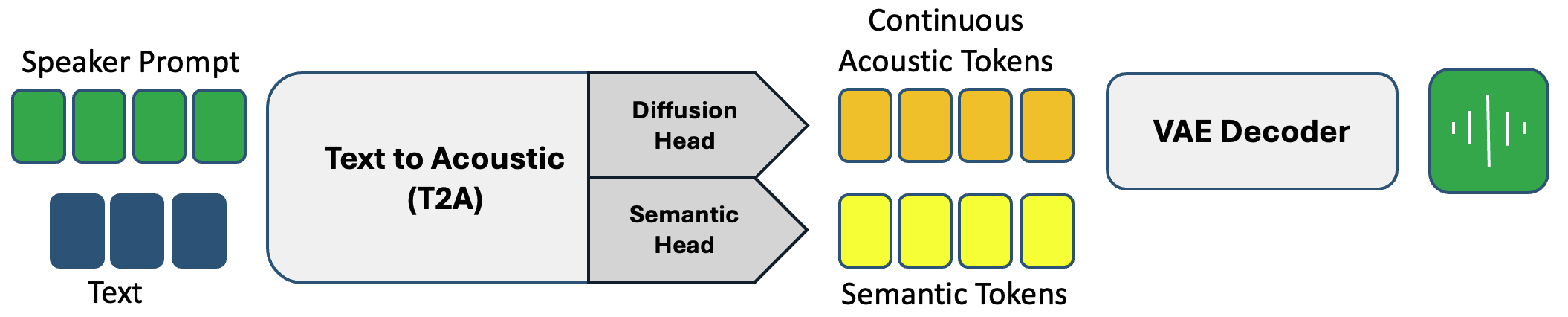
Figure 4: Synthesis using Text-to-Acoustic models.
Experimental Evaluation
Objective Metrics
Evaluations on the LibriSpeech test-clean dataset highlight that SALAD's continuous approaches significantly enhance intelligibility scores while maintaining competitive audio quality. Particularly, the T2A model achieves top intelligibility scores with speaker similarity marginally behind its discrete counterparts.
Subjective Listening Tests
Subjective assessments reveal parity between continuous T2A and high-quality audio outputs, suggesting SALAD's ability to replicate natural speech qualities effectively. The speaker similarity tests reaffirm the model's capability to convincingly mimic target speaker prompts.
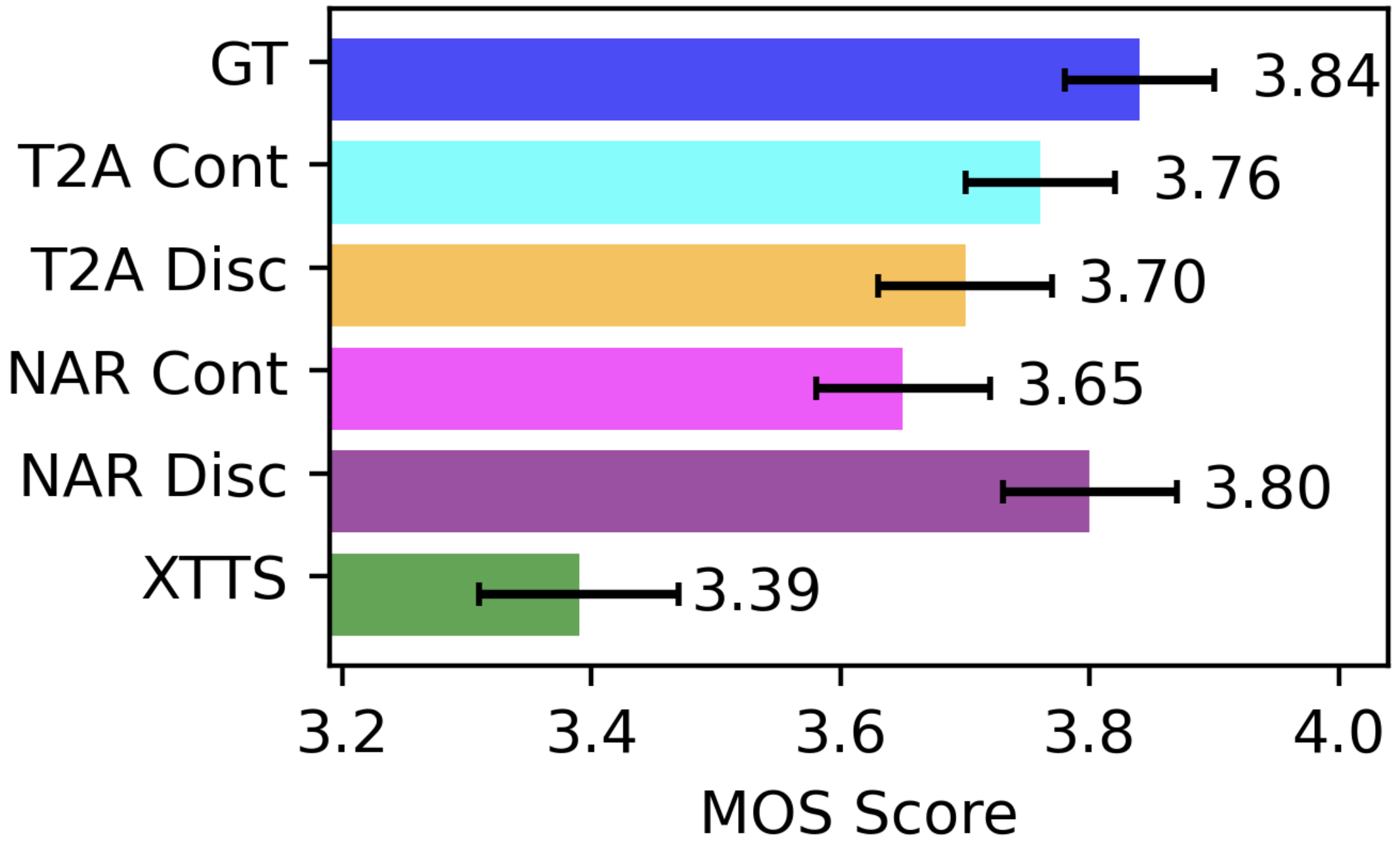
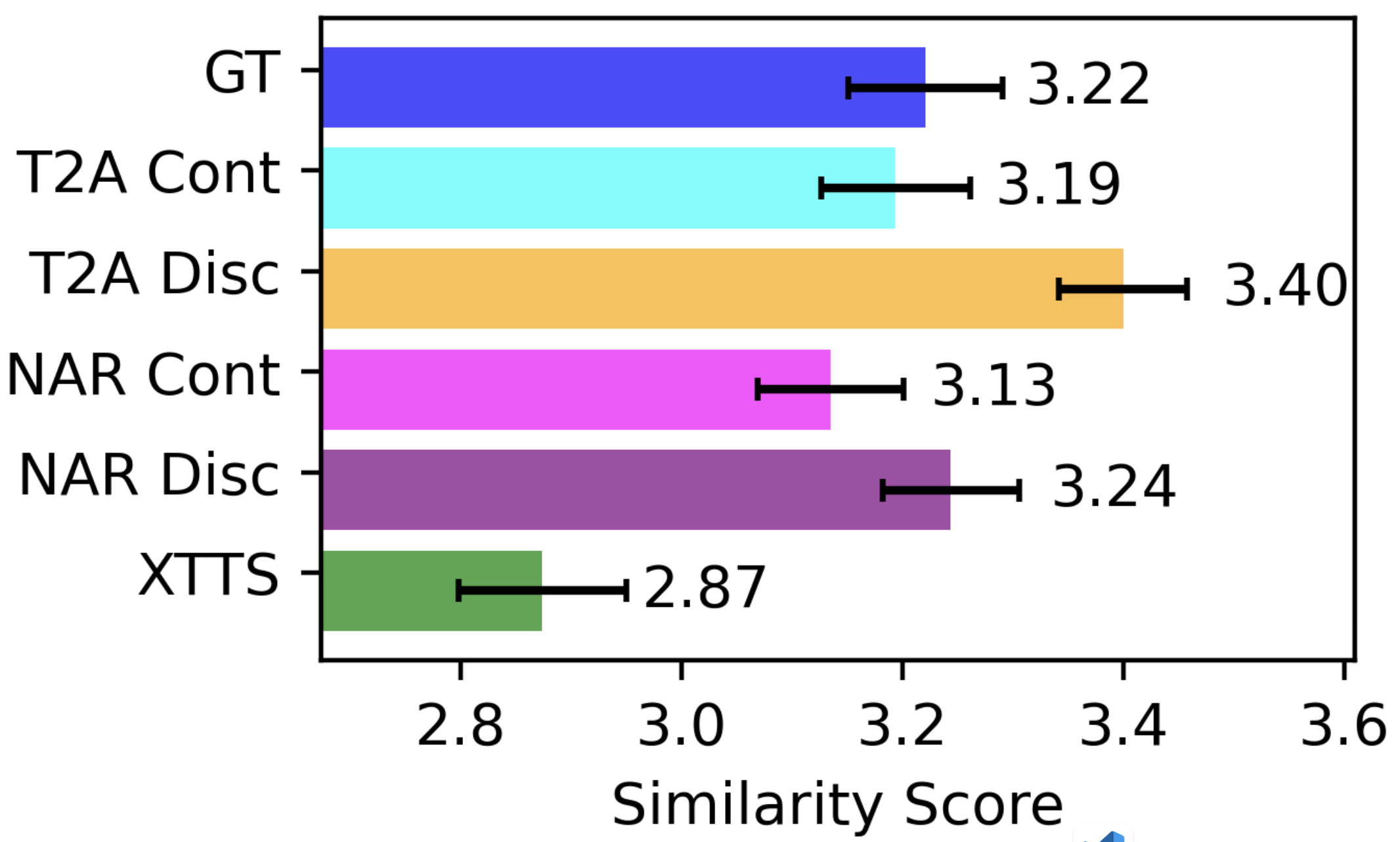
Figure 5: MOS Listening Test (1-5 scale).
Discussion and Future Prospects
The study underscores the effectiveness of continuous latent diffusion in overcoming limitations posed by discrete token quantization, specifically in preserving reconstruction fidelity. Future advances should explore refined multimodal models that harmoniously blend perceptual tasks with generative capabilities without extensive compression, potentially through further optimization of continuous tokens and adaptive diffusion strategies.
Conclusion
The paper provides compelling evidence for continuous per-token diffusion's potential in advancing speech synthesis. By bridging semantic tokens with a diffusion-based approach, SALAD not only enhances traditional speech synthesis metrics but also sets a foundational methodology for subsequent multimodal and TTS advancements. Future work could extend these findings into comprehensive frameworks that integrate more nuanced perceptual insights within speech models.
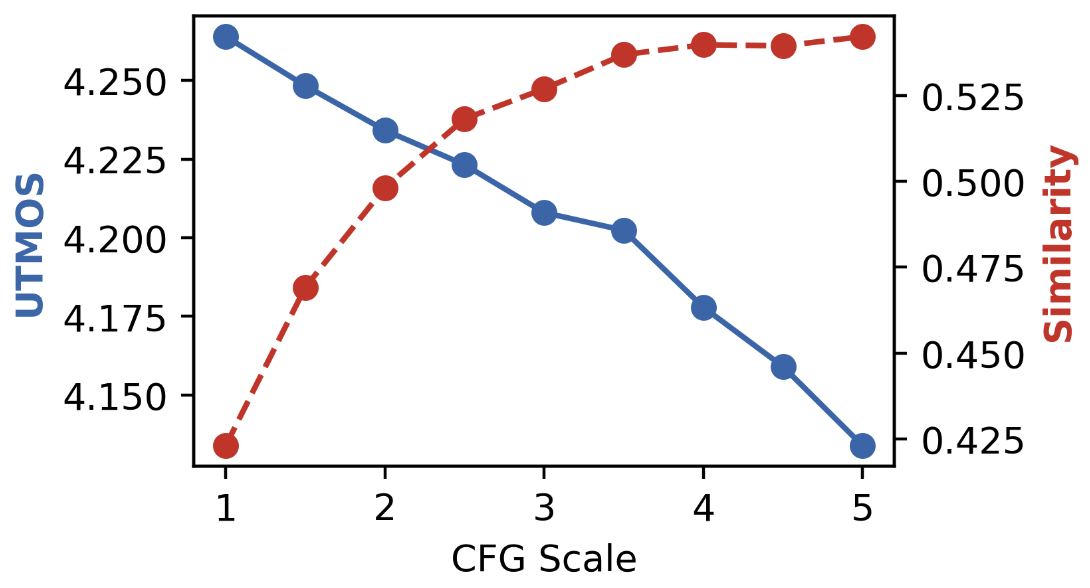
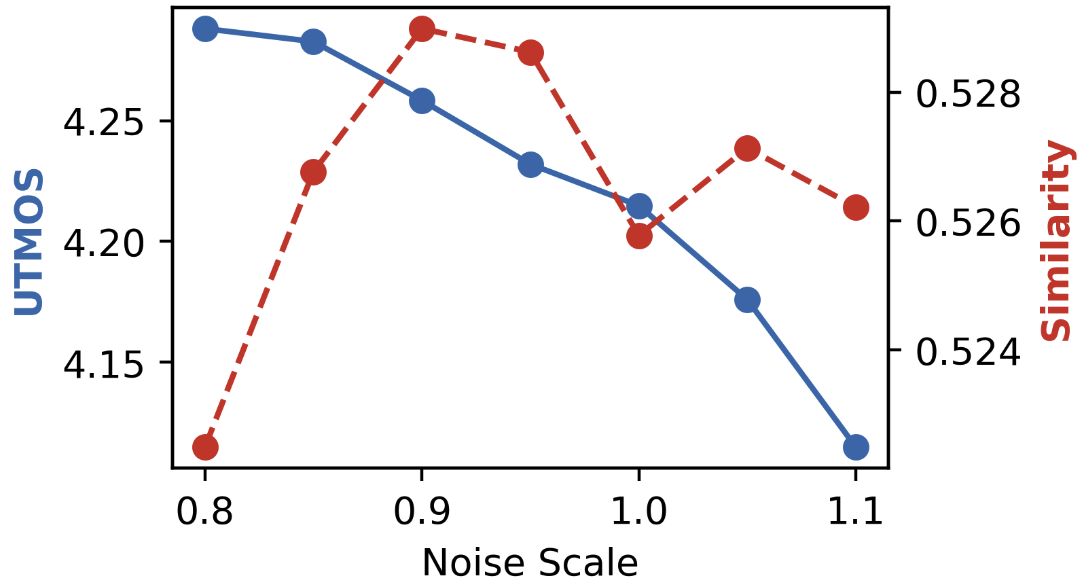
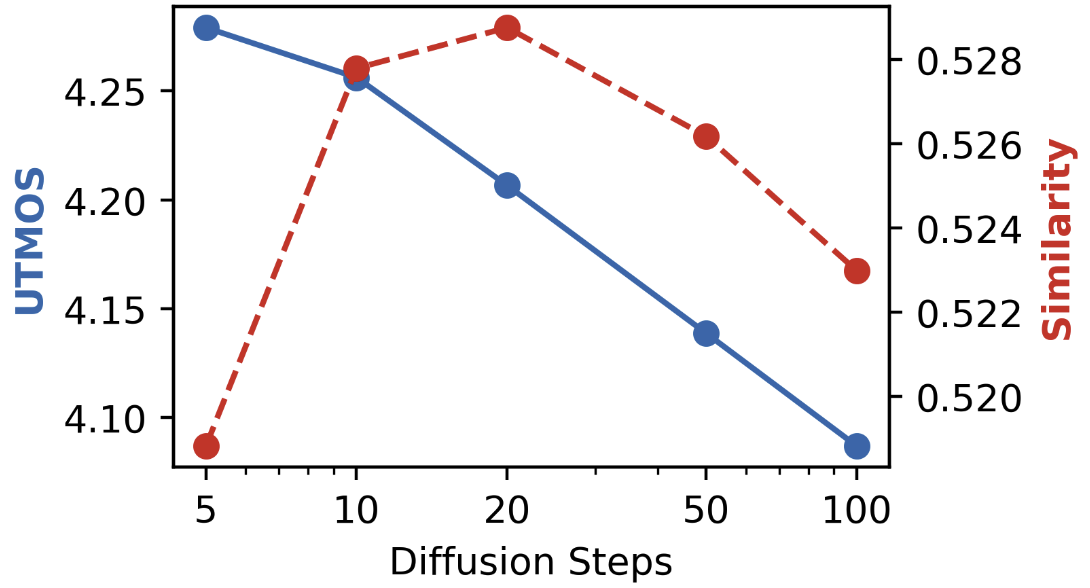
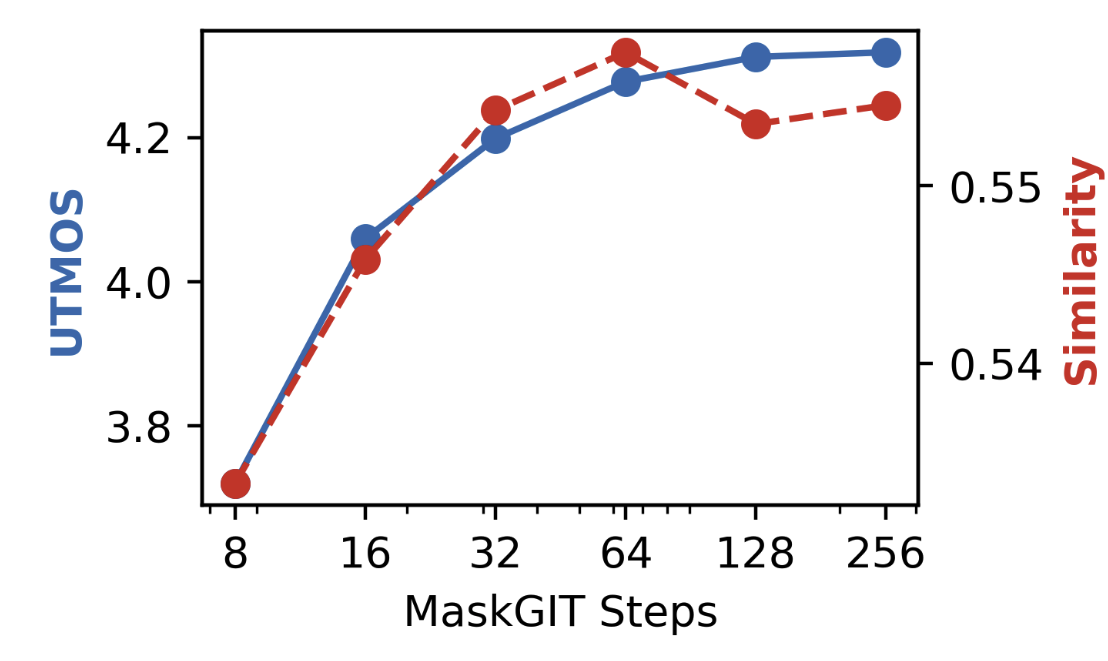
Figure 6: CFG scale.
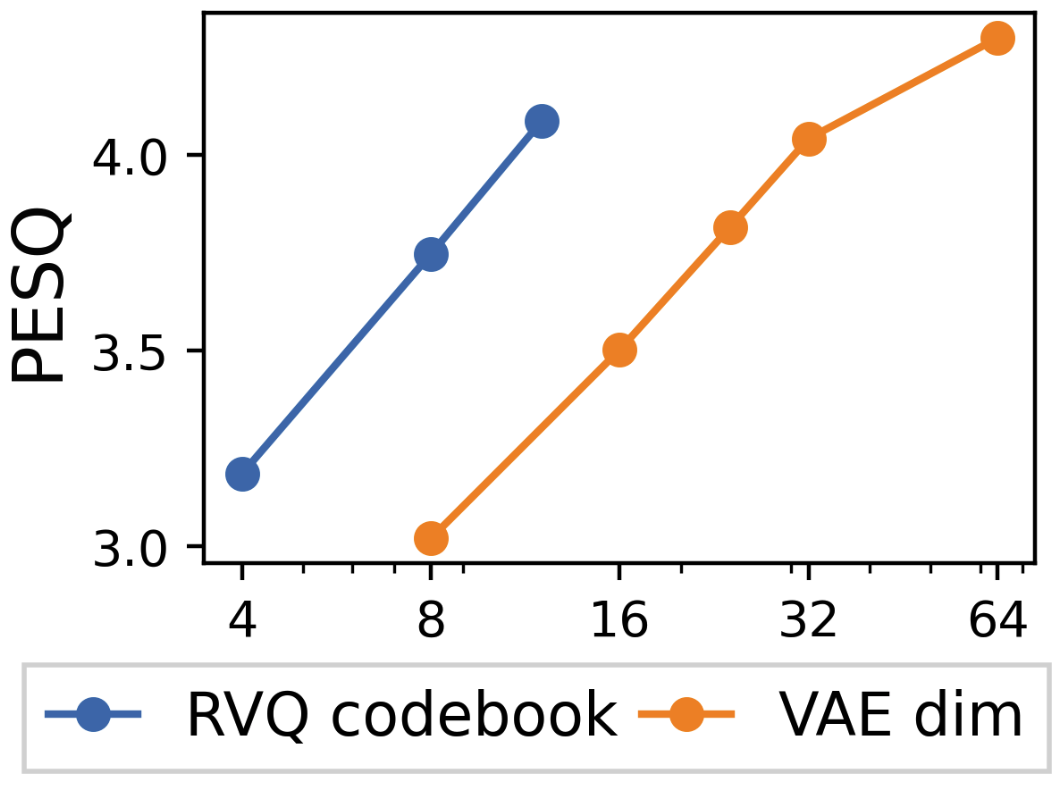
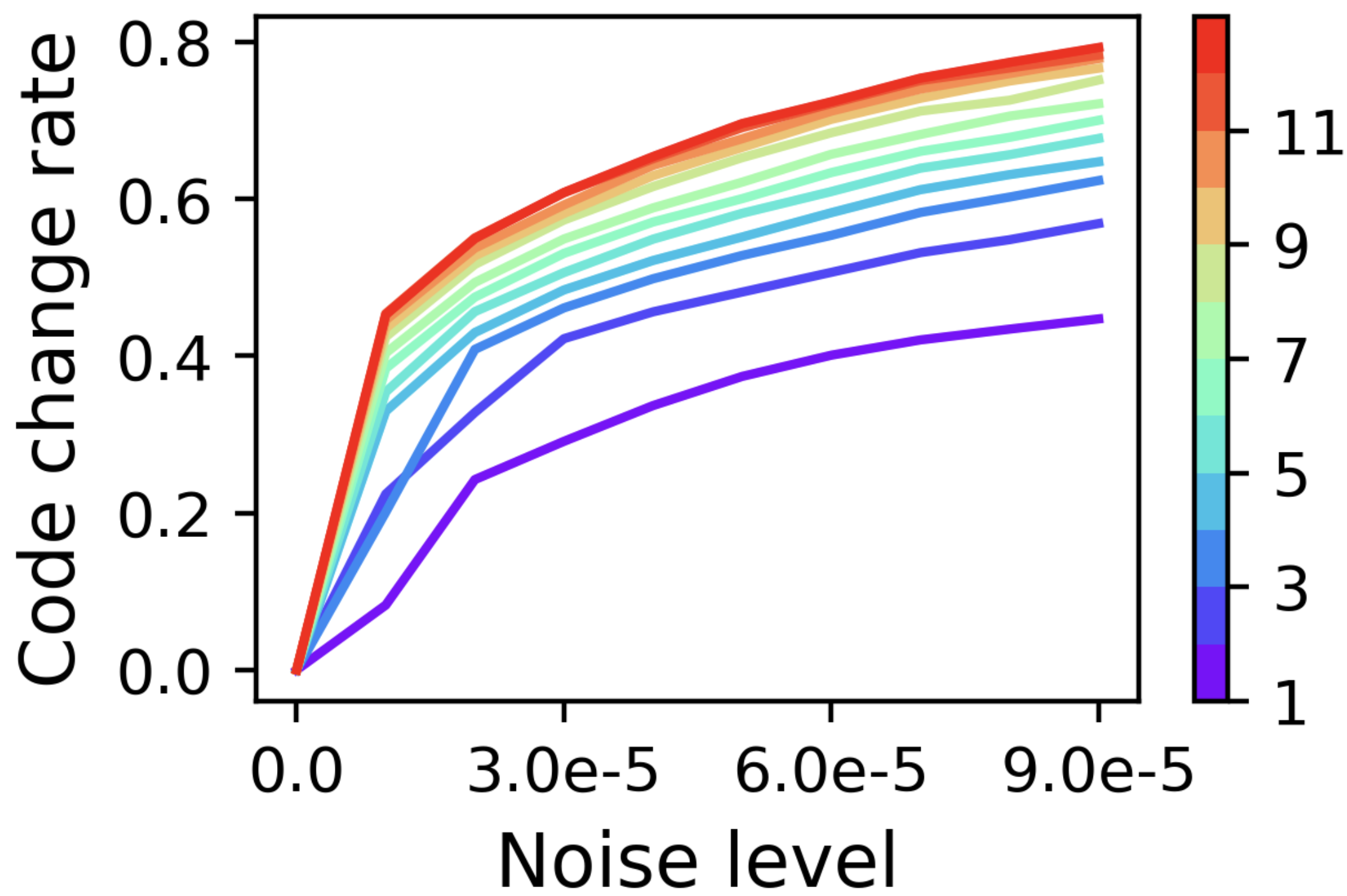
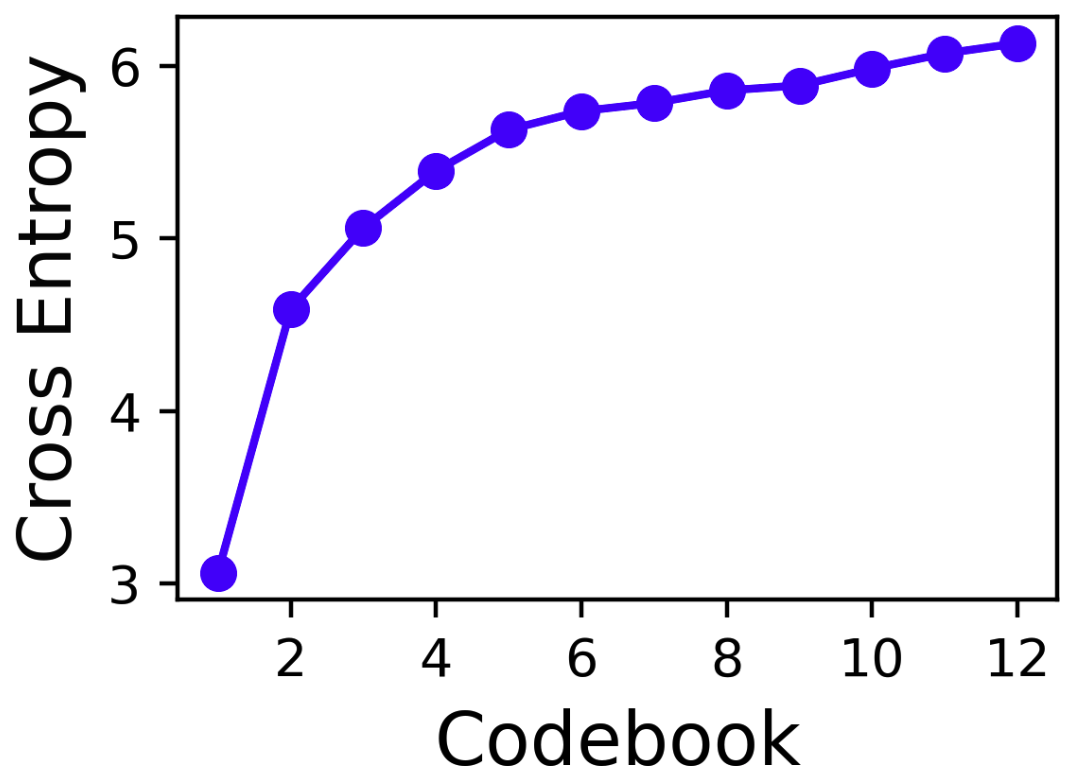
Figure 7: VQ/VAE reconstruction.
This analysis conveys detailed insights into the research and its practical implications, emphasizing continuous token diffusion's benefits in speech synthesis and laying the groundwork for further AI advancements in multimodal systems.