- The paper presents a scalable, long-form multi-speaker speech synthesis framework that integrates next-token diffusion with ultra-low frame rate tokenization.
- It employs a dual-branch tokenizer and LLM integration to enable efficient autoregressive generation, achieving state-of-the-art subjective and objective performance.
- Results indicate significant improvements in audio fidelity and natural conversational dynamics, with potential applications in podcasting, audiobooks, and interactive agents.
Introduction
The VibeVoice Technical Report presents a unified framework for synthesizing long-form, multi-speaker conversational speech using next-token diffusion modeling. The system is designed to address the limitations of prior TTS architectures, which struggle with natural turn-taking, content-aware generation, and scalability in multi-speaker, extended audio scenarios. VibeVoice integrates a novel continuous speech tokenizer with a LLM and a token-level diffusion head, enabling efficient, high-fidelity generation of up to 90 minutes of audio with up to four speakers. The model demonstrates strong performance across both subjective and objective metrics, outperforming leading open-source and proprietary systems.
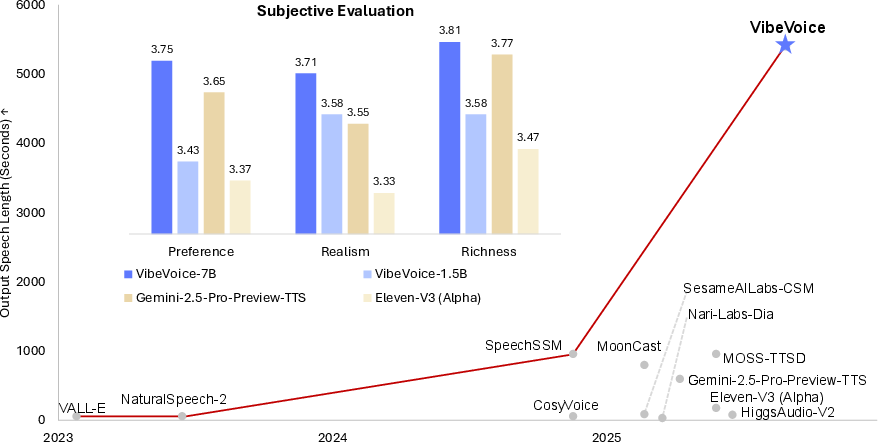
Figure 1: VibeVoice is capable of synthesizing 5,000+ seconds of audio while consistently outperforming strong open/closed-source systems in subjective evaluations of preference, realism, and richness.
System Architecture
VibeVoice's architecture consists of three principal components: a continuous speech tokenizer, a core LLM, and a token-level diffusion head. The speech tokenizer is split into acoustic and semantic branches. The acoustic tokenizer is a VAE-based encoder-decoder with hierarchical, convolutional transformer blocks, achieving a 3200× compression rate (7.5 Hz frame rate) and maintaining a speech-to-text token ratio of approximately 2:1. This design enables efficient streaming and long-context modeling, with each encoder/decoder containing ~340M parameters.
The semantic tokenizer mirrors the acoustic encoder's architecture but omits the VAE, focusing on deterministic, content-centric feature extraction via ASR proxy training. The output representations are aligned with textual semantics and used for hybrid context modeling.
The LLM (Qwen2.5, 1.5B/7B parameters) ingests concatenated voice font features, text scripts, and speaker role identifiers, producing hidden states that condition the diffusion head. The diffusion head, implemented as a lightweight 4-layer module, predicts continuous VAE features for each token via a denoising process, leveraging Classifier-Free Guidance and accelerated by DPM-Solver++ for efficient sampling.
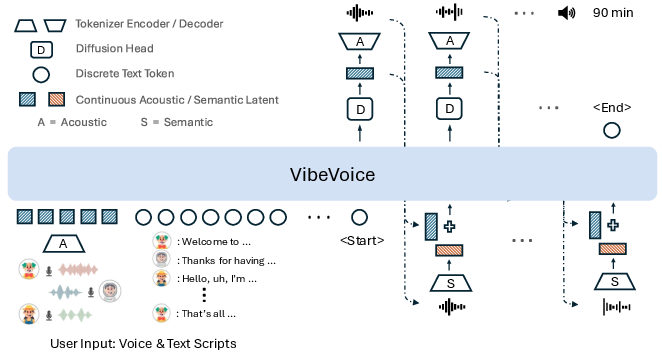
Figure 2: VibeVoice employs next token diffusion framework as in LatentLM to synthesize long-form and multi-speaker audios.
Training and Inference
During training, the acoustic and semantic tokenizers are frozen, and only the LLM and diffusion head are updated. A curriculum learning strategy is employed for input sequence length, scaling from 4,096 to 65,536 tokens. The guidance scale is set to 1.3, and the denoising process uses 10 iterative steps. The model is capable of streaming synthesis, supporting up to 64K context windows and 90-minute audio generation.
The input representation is constructed as a concatenation of speaker-specific acoustic latents and text scripts, interleaved with role identifiers. For each generated segment, the hybrid speech representation is encoded and modeled autoregressively.
Speech Tokenizer Design and Evaluation
The acoustic tokenizer achieves an ultra-low frame rate (7.5 Hz) and a 3200× compression rate, substantially outperforming prior models such as Encodec, DAC, and WavTokenizer in both compression and reconstruction fidelity. Objective metrics on LibriTTS test-clean and test-other subsets show leading PESQ (3.068/2.848) and UTMOS (4.181/3.724) scores, indicating high perceptual quality despite aggressive compression.
The semantic tokenizer, trained via ASR proxy, ensures robust alignment between speech and text, facilitating content-aware generation and improved intelligibility.
Empirical Results
VibeVoice is evaluated on both long-form conversational and short-utterance benchmarks. In subjective tests (Mean Opinion Scores for realism, richness, and preference), VibeVoice-7B achieves the highest scores among all compared systems, including Gemini 2.5 Pro TTS, Elevenlabs v3 alpha, and Higgs Audio V2. Objective metrics (WER, SIM) further confirm its superiority, with WER as low as 1.11 (Whisper) and speaker similarity (SIM) up to 0.692.
On the SEED test sets (short utterances), VibeVoice generalizes well, maintaining competitive WER and SIM despite being optimized for long-form synthesis. The low frame rate reduces decoding steps per second, improving computational efficiency.
Methodological Innovations
- Next-Token Diffusion: VibeVoice leverages next-token diffusion, as in LatentLM, for autoregressive latent vector generation, enabling stable, scalable synthesis over long contexts.
- Ultra-Low Frame Rate Tokenizer: The acoustic tokenizer's 7.5 Hz frame rate and 3200× compression rate are unprecedented, allowing efficient modeling of extended audio sequences without sacrificing fidelity.
- Hybrid Context Modeling: By combining acoustic and semantic representations, VibeVoice achieves robust content-aware generation, supporting natural conversational dynamics and multi-speaker scenarios.
- LLM Integration: The use of a large, pre-trained LLM for context interpretation and conditioning enables flexible role assignment, cross-lingual transfer, and improved expressiveness.
Limitations and Risks
VibeVoice is currently limited to English and Chinese transcripts; other languages may yield unpredictable outputs. The model does not handle non-speech audio (background noise, music) or overlapping speech segments. The high fidelity of synthetic speech poses risks for deepfake generation and disinformation, necessitating responsible use and further safeguards before commercial deployment.
Implications and Future Directions
VibeVoice advances the state-of-the-art in long-form, multi-speaker TTS synthesis, demonstrating that next-token diffusion and ultra-low frame rate tokenization can scale to extended conversational audio. The architectural simplification—removing explicit prior designs and relying on LLM-driven context modeling—suggests a promising direction for unified, scalable generative audio models.
Future work may focus on extending language coverage, modeling overlapping speech, integrating non-speech audio, and developing robust safeguards against misuse. The demonstrated scalability and efficiency open avenues for real-time, interactive applications in podcasting, audiobooks, and conversational agents.
Conclusion
VibeVoice introduces a unified framework for scalable, high-fidelity long-form speech synthesis, integrating efficient tokenization, LLM-based context modeling, and next-token diffusion. The model achieves state-of-the-art performance in both subjective and objective evaluations, supporting multi-speaker, extended audio generation with significant computational efficiency. The methodological innovations and empirical results position VibeVoice as a reference architecture for future research in generative speech modeling, with clear implications for both practical deployment and theoretical development in AI-driven audio synthesis.