Representing Web Applications As Knowledge Graphs
Abstract: Traditional methods for crawling and parsing web applications predominantly rely on extracting hyperlinks from initial pages and recursively following linked resources. This approach constructs a graph where nodes represent unstructured data from web pages, and edges signify transitions between them. However, these techniques are limited in capturing the dynamic and interactive behaviors inherent to modern web applications. In contrast, the proposed method models each node as a structured representation of the application's current state, with edges reflecting user-initiated actions or transitions. This structured representation enables a more comprehensive and functional understanding of web applications, offering valuable insights for downstream tasks such as automated testing and behavior analysis.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored. Each point aims to be actionable for future researchers.
- Formal definition and detection of a “unique state”: criteria, similarity thresholds, and deduplication across URLs, sessions, resolutions, and minor DOM/content changes; how to distinguish meaningful vs. ephemeral changes (ads, timestamps, stock counters).
- Quantitative “meaningful state change” test: exact algorithms for DOM diffing, visual diffing, and metadata comparison; how false positives/negatives are handled when validating state transitions.
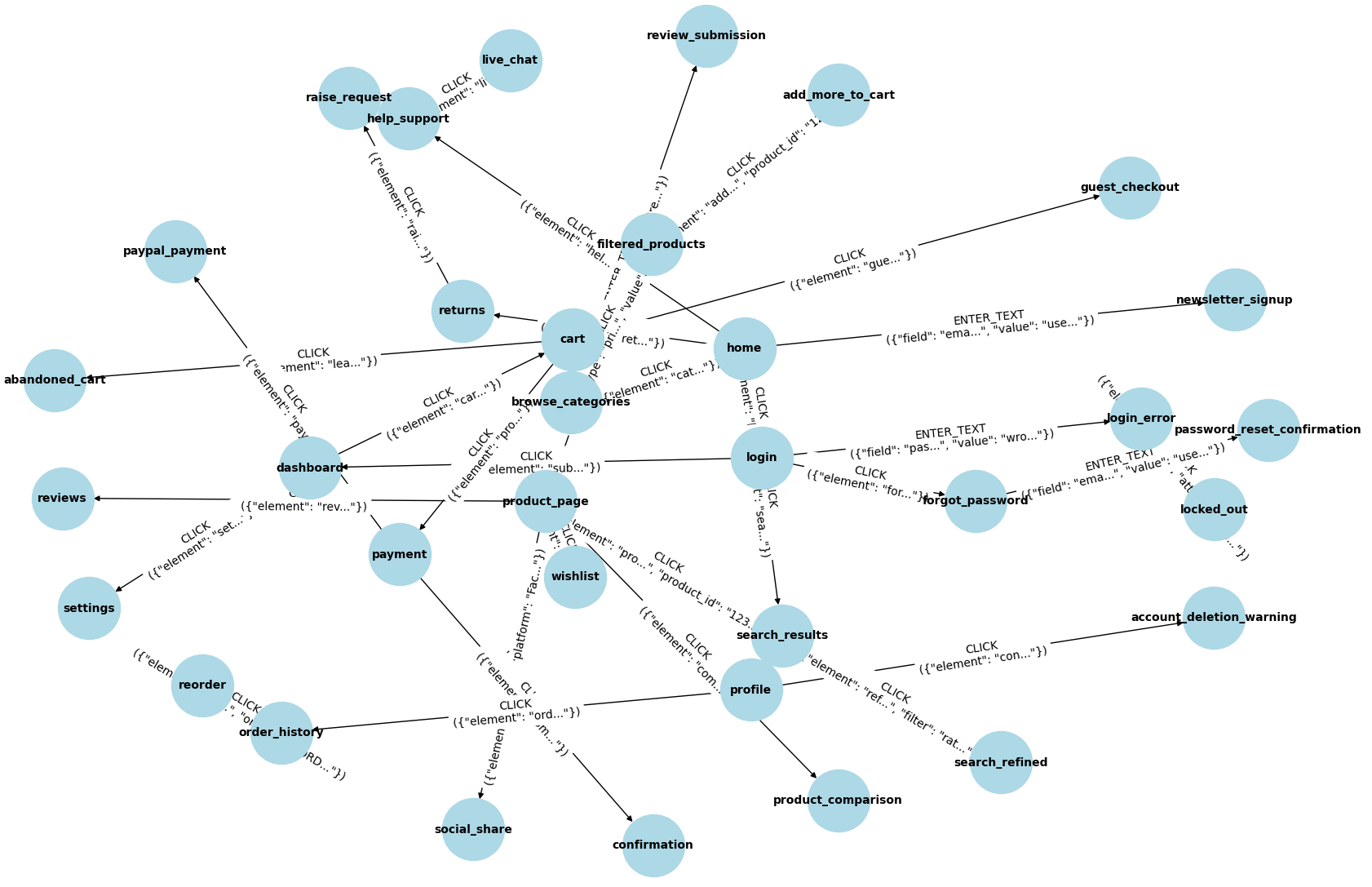
- Action enumeration strategy: how candidate actions are discovered from the DOM (selectors, accessibility tree, event listeners, shadow DOM), how form input domains are sampled, and how combinatorial explosion is controlled.
- Handling continuous and high-cardinality inputs: policies for exploring text fields (search terms), numeric ranges, addresses, dates, file uploads, and multi-selects without overwhelming the state space.
- Cycle detection and loop handling in the graph: explicit methods to identify, collapse, or annotate cycles; justification for targeting edge complexity close to n−1 despite real web apps being highly cyclic.
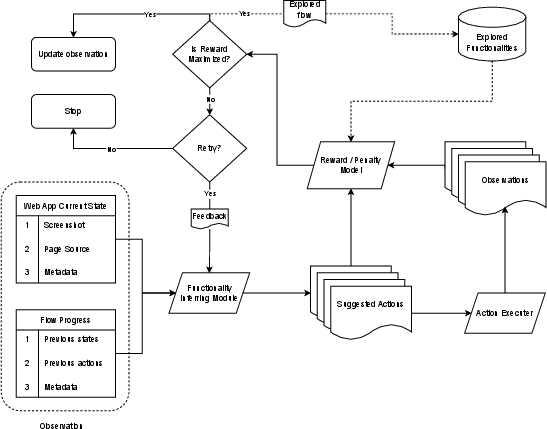
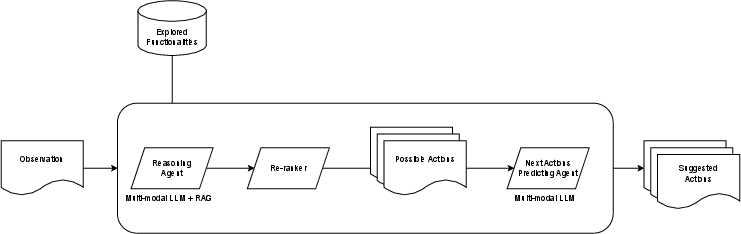
- Precise definitions and formulas for re-ranking metrics: how “entropy” and “expected reward” are computed, calibrated, and combined; feature sets used; ablation results showing their impact.
- Reward/Penalty Model specifics: the exact scoring function (−1 to +1), thresholds, novelty vs. utility trade-offs, and whether reward is adapted online; potential to formulate as a reinforcement learning problem and benchmark RL baselines.
- Next Actions Prediction Agent training: dataset sources, labeling strategy, training objectives, fine-tuning details, architectures for multi-modal fusion (DOM + screenshots + metadata), and generalization to unseen applications.
- LLM determinism and reproducibility: seed control, caching strategies, temperature settings, and variance across runs; how results drift with application updates.
- Robustness to dynamic front-end techniques: handling CSS/JS obfuscation, virtual DOM, canvas rendering, shadow DOM, and micro-frontends; whether network-level instrumentation (XHR/fetch hooks) is used to capture AJAX flows.
- Anti-bot, authentication, and access-control barriers: treatment of CAPTCHAs, CSRF tokens, session expiration, MFA, rate limiting, paywalls, and bot detection; compliance with robots.txt and site ToS.
- Safety and ethics of side-effectful actions: how irreversible operations (e.g., purchases) are prevented (sandbox/staging/mocks), rollback strategies, and ethical guidelines for crawling live e-commerce sites.
- State-space explosion mitigations: pruning criteria, heuristic bounds, adaptive exploration policies, and guarantees/trade-offs between coverage and efficiency.
- Scalability and resource profile: hardware/software environment, concurrency settings, headless vs. headed browsers, memory/storage footprint for screenshot/DOM/metadata archives, and cost of LLM inference; strategies to reduce the 5,500s completion time.
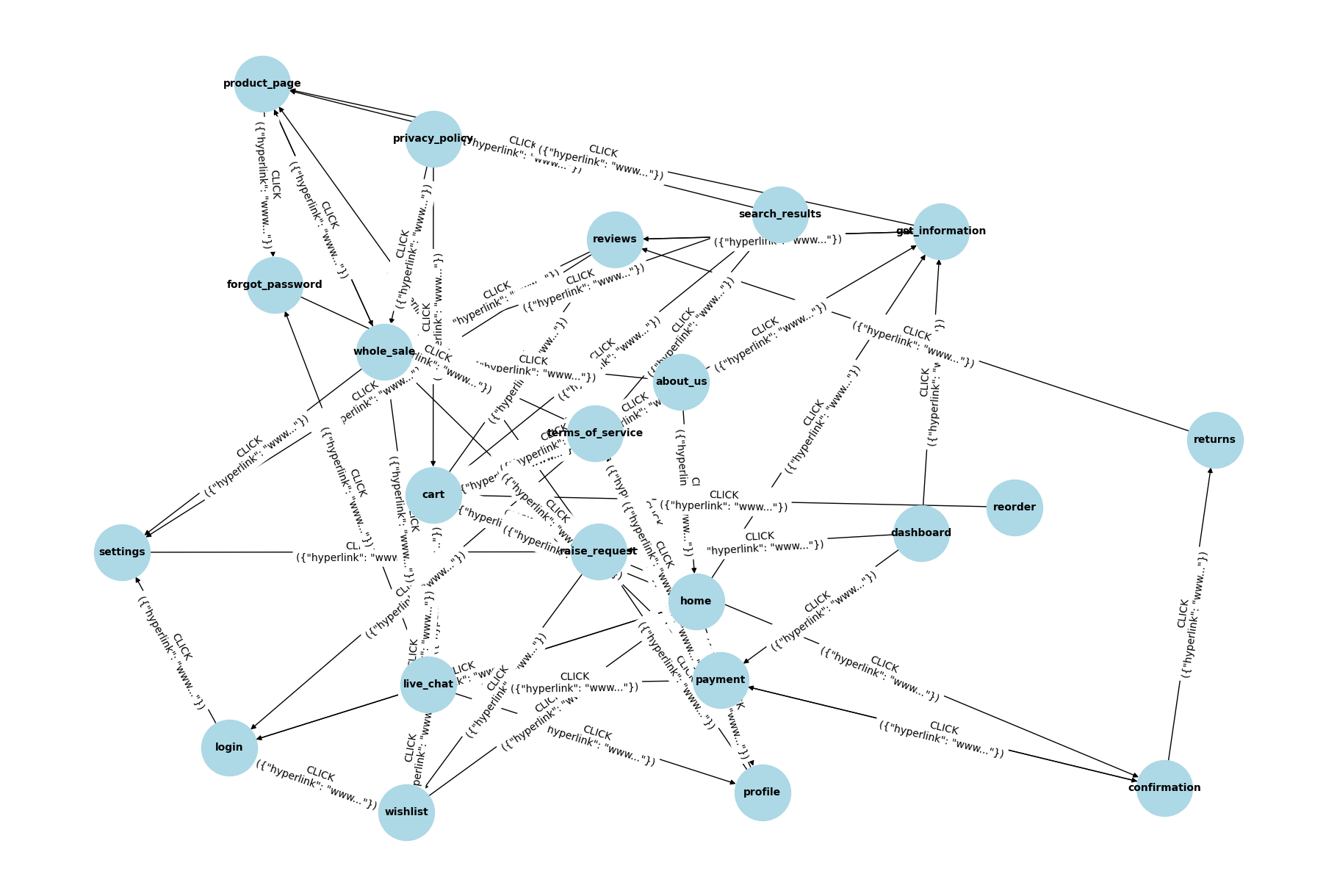
- Graph data model and interoperability: explicit schema/ontology for nodes and edges, typing (e.g., LoginState, CartState), adoption of RDF/OWL standards, use of graph databases, indexing, and query APIs for downstream tasks.
- Evaluation fairness and normalization: the proposed method counts multiple states per URL, whereas the baseline equates unique states to unique URLs; need a normalized notion of “functional state coverage” to enable fair comparisons.
- Baseline breadth: absence of head-to-head comparisons with state-of-the-art event-based crawlers (e.g., Crawljax, jäk); add benchmarks on multiple sites to validate gains beyond a traditional Scrapy baseline.
- Metric validity and interpretation: justification for “lower graph density is better,” and for targeting edge complexity near n−1; alternative task-relevant metrics (functional coverage, unique flow count, action success rate, redundancy ratio) and user-centric measures.
- Failure recovery rate definition: taxonomy of failure types (timeouts, stale elements, server errors), measurement method, sensitivity to max_retries, and comparison against baselines using Selenium-like retries.
- Hyperparameter tuning and sensitivity: rationale for min_reward = 0, max_leaf_branches = 999, max_consecutive_actions = 5; sensitivity analysis, adaptive tuning, and ablations to show their impact.
- Multimodal perception details: methods for screenshot understanding (OCR, UI component detection, visual grounding), DOM serialization/embedding, and robustness to responsive design, dark mode, and accessibility variants.
- Internationalization and accessibility: support for multi-language content, RTL layouts, locales, and leveraging the accessibility tree/ARIA roles to infer functionality more reliably.
- Action semantics verification: procedures to validate that edges correspond to intended functions (e.g., “Add to cart” really adds); ground truth creation, human-in-the-loop audits, and error rates for misclassification.
- Role- and profile-specific exploration: strategies to explore states across different user roles, logged-in vs. guest sessions, varying permissions, and the resulting combinatorial state expansion.
- Test case generation validation: how generated root-to-leaf paths translate into executable tests with assertions, coverage metrics (statement/branch/UI-flow), flakiness analysis, and CI/CD integration.
- Runtime environment reporting: network conditions, browser versions, OS, and concurrency differences between Scrapy and the proposed system to contextualize “time to completion” and ensure fair comparisons.
- Statistical rigor: single-site, single-run results without confidence intervals; need multiple runs, variance reporting, and significance testing across diverse application categories (e-commerce, SaaS dashboards, media, finance).
- Temporal maintenance and drift: mechanisms for incremental re-crawling, graph diffing/versioning, and tracking changes in apps over time (A/B tests, feature flags).
- Ephemeral content filtering: techniques to ignore randomization, rotating banners, ads, or personalized recommendations when defining states, to reduce noisy edges and nodes.
- Storage, compression, and retrieval: strategies for compressing screenshots/DOM, deduplicating metadata, indexing flows, and enabling efficient similarity search and path ranking at scale.
- Legal and privacy considerations: treatment of cookies/session data and potential PII in metadata; GDPR/CCPA compliance and secure storage/access policies.
- Code/data availability: lack of implementation details, datasets, and open-sourced tooling to enable replication and independent validation.
Collections
Sign up for free to add this paper to one or more collections.