- The paper introduces RealDevWorld, which combines RealDevBench and AppEvalPilot to assess production-ready software through automated GUI testing.
- It employs multimodal elements and agent-based testing to simulate realistic user interactions, achieving 0.92 accuracy and 0.85 expert correlation.
- Empirical results show that the framework outperforms traditional benchmarks by providing scalable, nuanced, and human-aligned software quality evaluations.
Automated GUI Testing for Production-Ready Software Evaluation
Introduction
The paper discusses the growing capabilities and challenges of automated GUI testing for production-level software evaluation using LLMs. As LLMs progress towards generating sophisticated software with dynamic user interfaces, current evaluation benchmarks fall short in addressing the runtime dynamics and interactive behaviors critical for production-ready applications.
RealDevWorld: A Novel Evaluation Framework
The authors introduce RealDevWorld, an end-to-end framework designed to evaluate the ability of LLMs to create complete, production-ready software repositories. RealDevWorld consists of two main components: RealDevBench and AppEvalPilot.
RealDevBench
RealDevBench is a comprehensive suite of 194 software engineering tasks sampled from real-world development scenarios across various domains, such as data analysis, display, and gaming. It is designed to test the LLM’s ability to handle complex software requirements by integrating multimodal elements like images and audio.
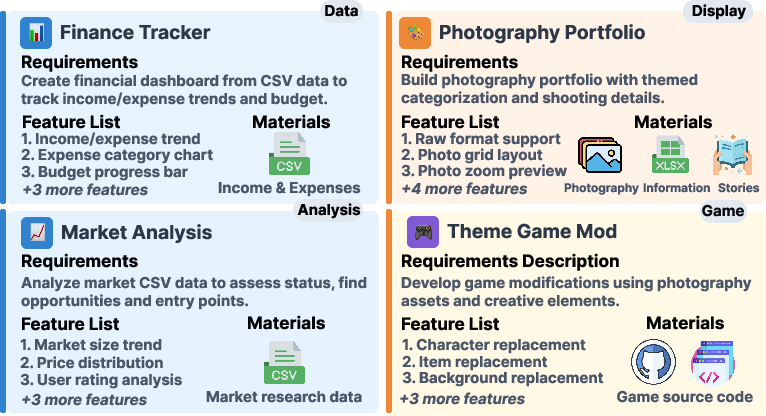
Figure 1: Representative cases from across four domains - Data, Display, Analysis, and Game - with consistent triplet structure (requirements, features, materials), reflecting real-world software engineering challenges.
AppEvalPilot
AppEvalPilot is a novel agent-based evaluation system that autonomously performs GUI-based interactions to assess the functional correctness of generated software. It emulates realistic user behaviors, capturing detailed execution traces, and provides nuanced feedback beyond binary success/failure metrics.
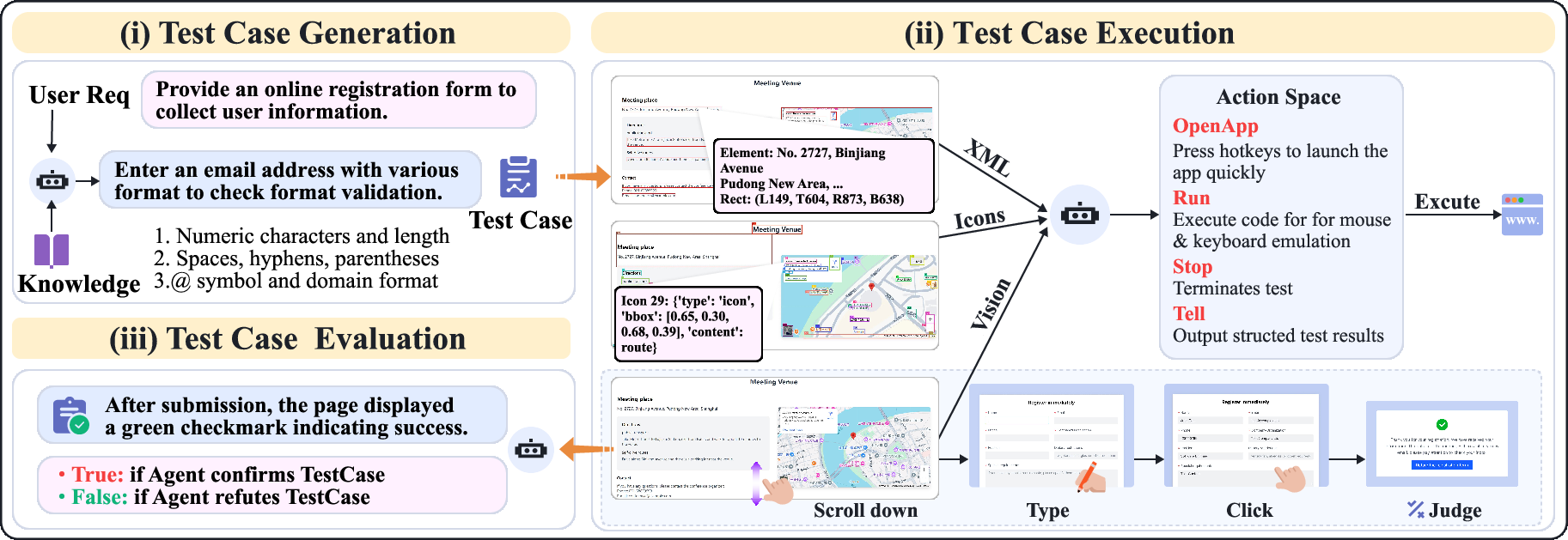
Figure 2: Overall design of AppEvalPilot showing the automated testing workflow: test case generation from user requirements, multimodal test execution through interface interaction (scrolling, typing, clicking), and binary evaluation of outcomes for objective software assessment.
Evaluation Methodology
The paper presents a new methodology for evaluating LLM-generated software using dynamic interaction testing. This approach focuses on user-centric and runtime-dependent behaviors that conventional static metrics fail to capture. The framework effectively measures software correctness and quality in a realistic usage context through adaptive test case generation and execution.
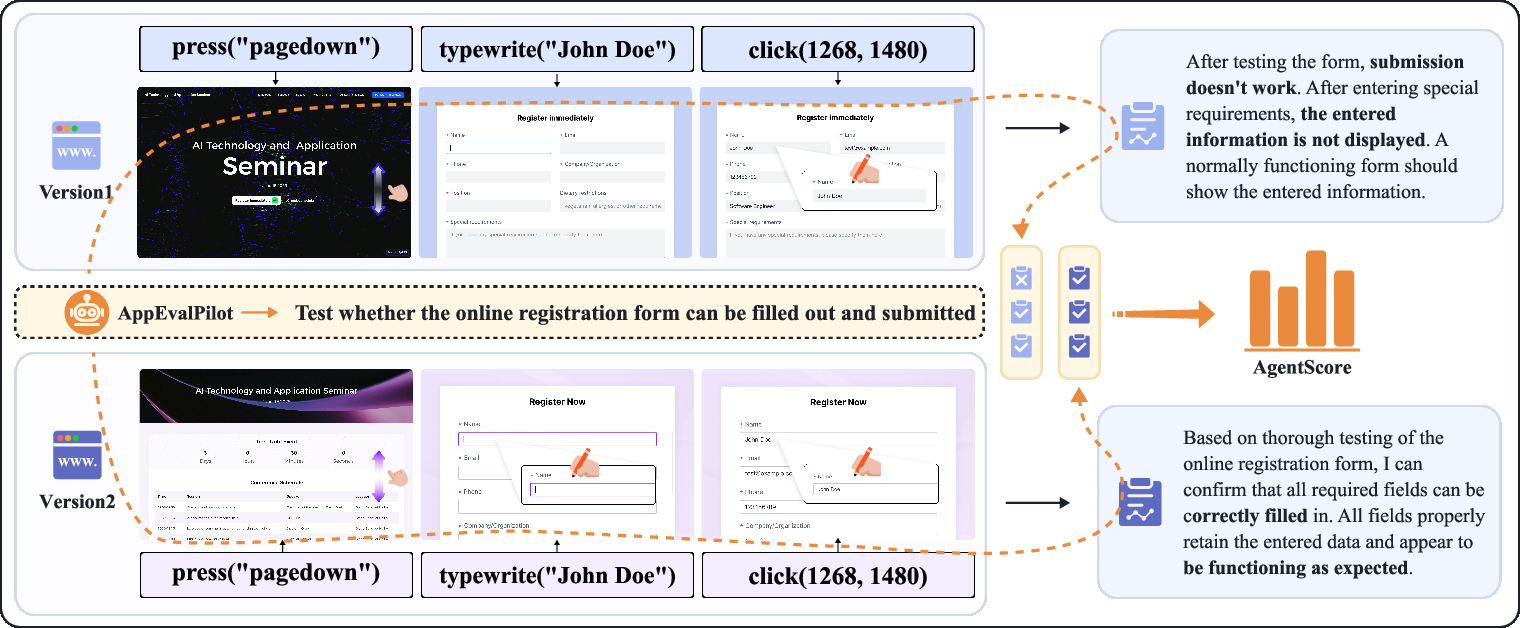
Figure 3: Evaluation pipeline of AppEvalPilot. The agent performs test sequences on two different web implementations, systematically assesses functionality through direct interaction, documents observable differences in form behavior, and generates quantitative scores based on test cases.
Empirical Results and Findings
Experiments show that the RealDevWorld framework provides human-aligned software evaluations with an accuracy of 0.92 and a correlation of 0.85 with expert assessments. This demonstrates the framework’s ability to deliver scalable and nuanced evaluations, significantly reducing reliance on manual review while aligning closely with human judgments.
Comparative Evaluation
RealDevWorld outperforms existing benchmarks by providing a more comprehensive evaluation platform for repository-level code generation tasks. The framework adapts to a wide variety of input data and interaction scenarios, making it applicable across diverse application types.
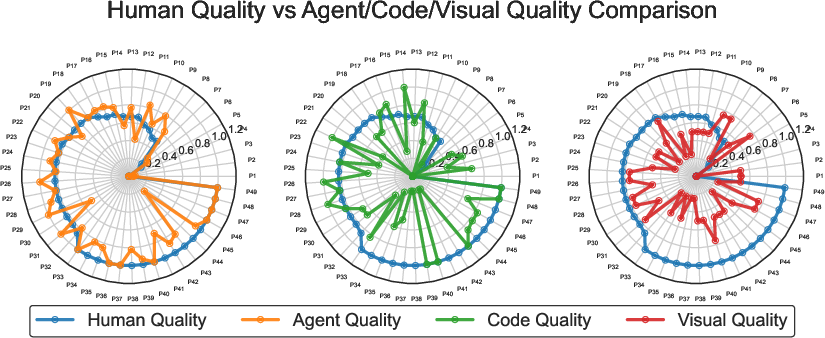
Figure 4: Comparative analysis of evaluation methods versus human quality. (Left) AppEvalPilot's autonomous evaluation, (Middle) Static LLM code scoring, (Right) Visual aesthetic scoring. Each point represents one project, with radial distance indicating quality scores (0-1 scale).
Conclusion
This framework facilitates a deeper understanding of LLM capabilities in generating production-ready software, offering a robust solution for automated, scalable, and nuanced software evaluation. By addressing the limitations of existing static evaluation methods, RealDevWorld paves the way for future advancements in AI-driven software engineering assessment.