- The paper introduces SimRAG as a two-stage fine-tuning framework that uses general instruction data followed by domain-specific self-training.
- It generates pseudo-labeled QA pairs via synthetic question generation and round-trip consistency filtering to ensure high domain relevance.
- Experiments reveal performance gains of 1.2% to 8.6% across biomedical, scientific, and computer science tasks, underscoring its practical impact.
SimRAG: Self-Improving Retrieval-Augmented Generation for Domain-Specific Adaptation
The paper introduces SimRAG, an innovative self-training approach designed to seamlessly adapt LLMs to domain-specific retrieval-augmented generation (RAG) tasks, with a focus on enhancing performance in specialized fields such as science and medicine.
Methodology
SimRAG's methodology centers on a two-stage fine-tuning process. Initially, LLMs are fine-tuned on general instruction-following and question-answering datasets. This step establishes a foundation for handling general-domain tasks by equipping models with basic instruction-following skills. The second stage involves generating synthetic, domain-specific QA pairs from unlabeled corpora through self-training. This is accomplished by prompting LLMs to generate domain-relevant questions and employing a filtering strategy to ensure high-quality synthetic examples.
Stage-I: Retrieval-Oriented Fine-Tuning
In the first stage, LLMs are enhanced by leveraging a combination of general instruction fine-tuning data and retrieval-related datasets. This includes a variety of QA tasks specifically chosen to reinforce context utilization skills. By integrating these diverse datasets, the models improve their grounding abilities, enabling them to effectively navigate knowledge-intensive scenarios.
Stage-II: Domain Adaptive Fine-Tuning with Self-Training
Stage-II capitalizes on self-training by generating pseudo-labeled training samples from domain-specific corpora. Candidate QA pairs are synthesized by first extracting potential answers and then generating questions conditioned on those answers and context. This process is refined using round-trip consistency filtering to retain only those pairs with robust domain relevance. The addition of tasks such as short-span QA, multiple-choice, and claim verification ensures the diverse nature of synthetic data, preventing overfitting and enhancing generalization across different tasks.
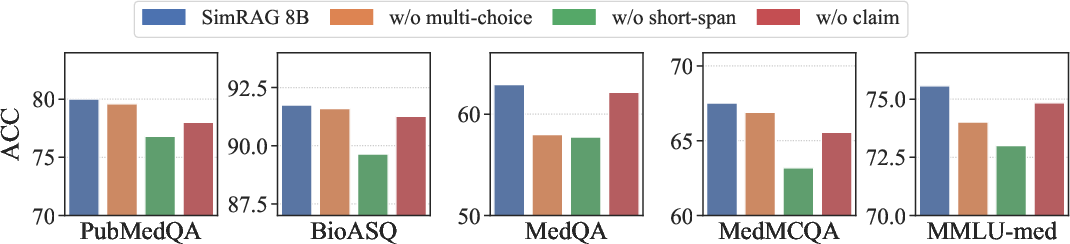
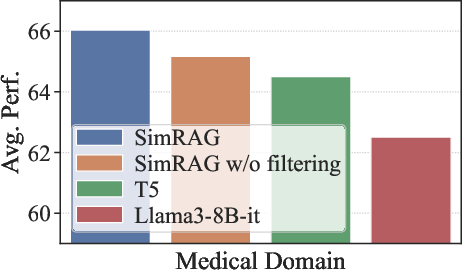
Figure 1: Effect of diverse types of generated QA pairs.
Experimental Results
The performance of SimRAG is evaluated across multiple datasets in the biomedical, scientific, and computer science domains. SimRAG consistently outperforms competing models by margins of 1.2% to 8.6%, illustrating its effectiveness in adapting LLMs to specific domains. The empirical studies underscore the advantages of joint training for question answering and generation, as well as the importance of employing diverse, tailored QA pairs.
Advantages and Limitations
SimRAG's framework offers substantial benefits by utilizing self-generated pseudo-labeled data, reducing the dependency on costly high-quality annotated data and offering a scalable solution for domain adaptation. However, the approach is constrained by its reliance on single-round query generation, potentially limiting the refinement of pseudo-label quality. Additionally, the method introduces additional computational overhead during pre-training phases, though inference complexity remains consistent with traditional RAG models.
Conclusion
SimRAG emerges as a compelling strategy for leveraging self-improvement within LLMs to tackle domain-specific RAG challenges. By enhancing models through joint capabilities in question answering and generation, SimRAG effectively navigates the complexities of domain specialization, ensuring robust performances across varied specialized tasks. Future work could explore iterative pseudo-label generation and the application of stronger query-generation models to further elevate its efficacy.