- The paper introduces SLLMBO, a framework that integrates LLM-based initialization with TPE exploration for efficient hyperparameter tuning.
- It employs zero-shot and few-shot learning techniques alongside cross-validation and intelligent history management to refine search spaces.
- Experimental results on tabular datasets show that the hybrid approach outperforms traditional methods, underscoring its potential for broader applications.
Sequential LLM-Based Hyper-Parameter Optimization
Introduction
The paper "Sequential LLM-Based Hyper-parameter Optimization" (2410.20302) presents a novel framework, SLLMBO, to enhance hyperparameter optimization (HPO) using LLMs. The SLLMBO framework addresses the limitations inherent in both traditional Bayesian Optimization (BO) and fully LLM-based methods by integrating dynamic search spaces and a hybrid LLM-Tree-structured Parzen Estimator (LLM-TPE) sampler. Unlike previous work that focused on models like GPT-3 and GPT-4, this study extends its analysis to include a broader spectrum of LLMs such as Claude-3.5-Sonnet and Gemini-1.5-Flash, offering comprehensive benchmarking across various tasks.
Methodology
The SLLMBO framework comprises several components: Initializer, Optimizer, Evaluator, History Manager, and an LLM-TPE Sampler. Each performs specific roles in the optimization process, ensuring efficient hyperparameter tuning:
- Initializer: Utilizes zero-shot learning to define initial hyperparameter search spaces, setting a robust baseline for further optimization.
- Optimizer: Employs few-shot learning to iteratively update search spaces and refine parameter suggestions, leveraging historical data for informed decision-making.
- Evaluator: Implements 5-fold cross-validation to assess parameter effectiveness, feeding back performance metrics to guide further optimization.
- History Manager: Maintains a comprehensive log of parameter trials, using techniques like intelligent summarization to manage token limits effectively.
- LLM-TPE Sampler: Combines LLM-based parameter initialization with TPE's exploration capabilities, balancing exploration and exploitation for efficient optimization.
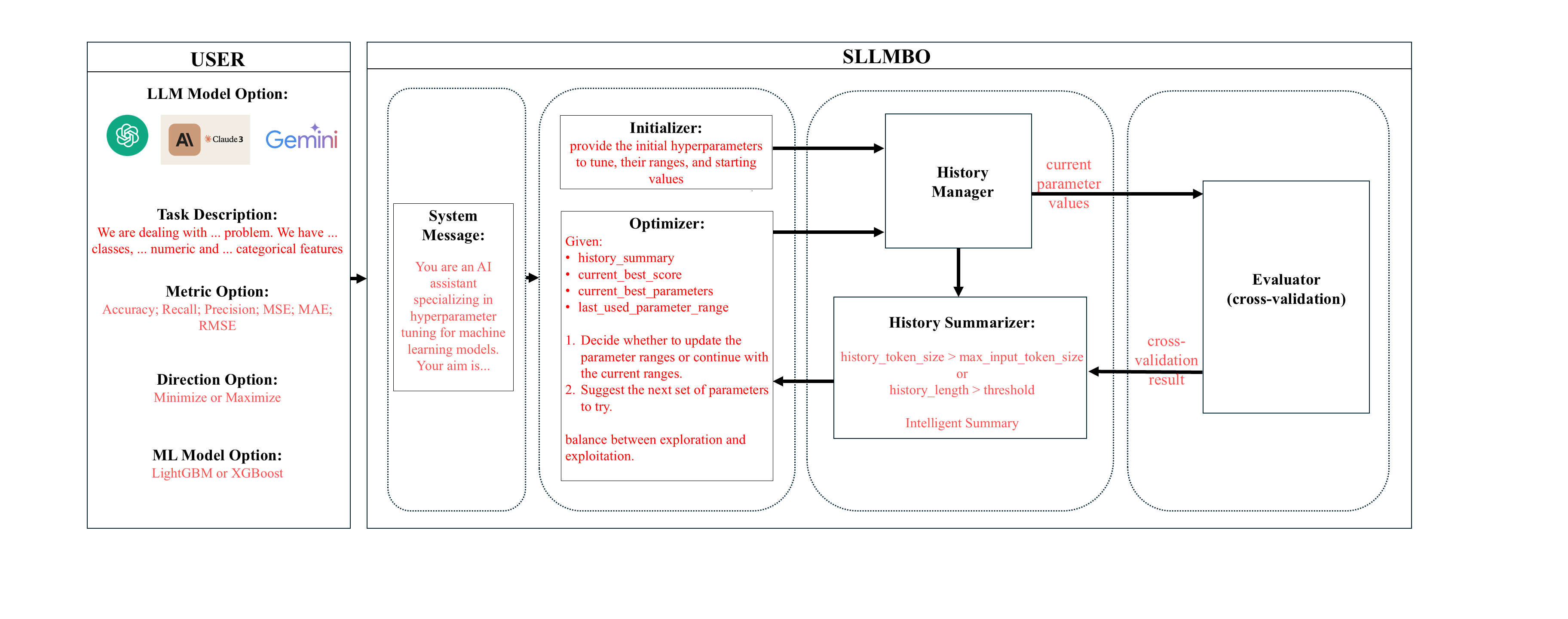
Figure 1: The SLLMBO workflow. The framework consists of the Initializer, Optimizer, Evaluator, History Manager, and LLM-TPE Sampler components, working iteratively to perform efficient hyperparameter optimization.
Experimental Setup
The authors evaluate SLLMBO using six datasets in classification and regression from public repositories like the UCI Machine Learning Repository and OpenML, alongside the complex M5 Forecasting dataset. Models such as LightGBM and XGBoost are chosen due to their effectiveness in dealing with tabular data. The comparison includes baseline methods (Optuna and Hyperopt using TPE) and multiple LLMs within the SLLMBO framework. Various configurations like GPT-4o, GPT-3.5-Turbo, Claude-3.5-Sonnet, and Gemini-1.5-Flash are tested. Each setup encompasses different initialization strategies (LLM-based and random) and sampling techniques (LLM and LLM-TPE hybrid), providing a well-rounded comparison.
Results and Discussion
Fully LLM-powered Methods
Initial experiments using fully LLM-based methods demonstrated significant improvements over traditional random initialization, particularly in regression tasks. The LLM-informed initialization offered noticeably better starting points, resulting in competitive or superior HPO performance in multiple tasks compared to Optuna and Hyperopt.
However, challenges such as limited exploration and premature early stopping emerged. The introduction of LangChain for memory management alleviated some technical constraints, leading to more consistent performance and reducing early stoppings by allowing longer explorations.
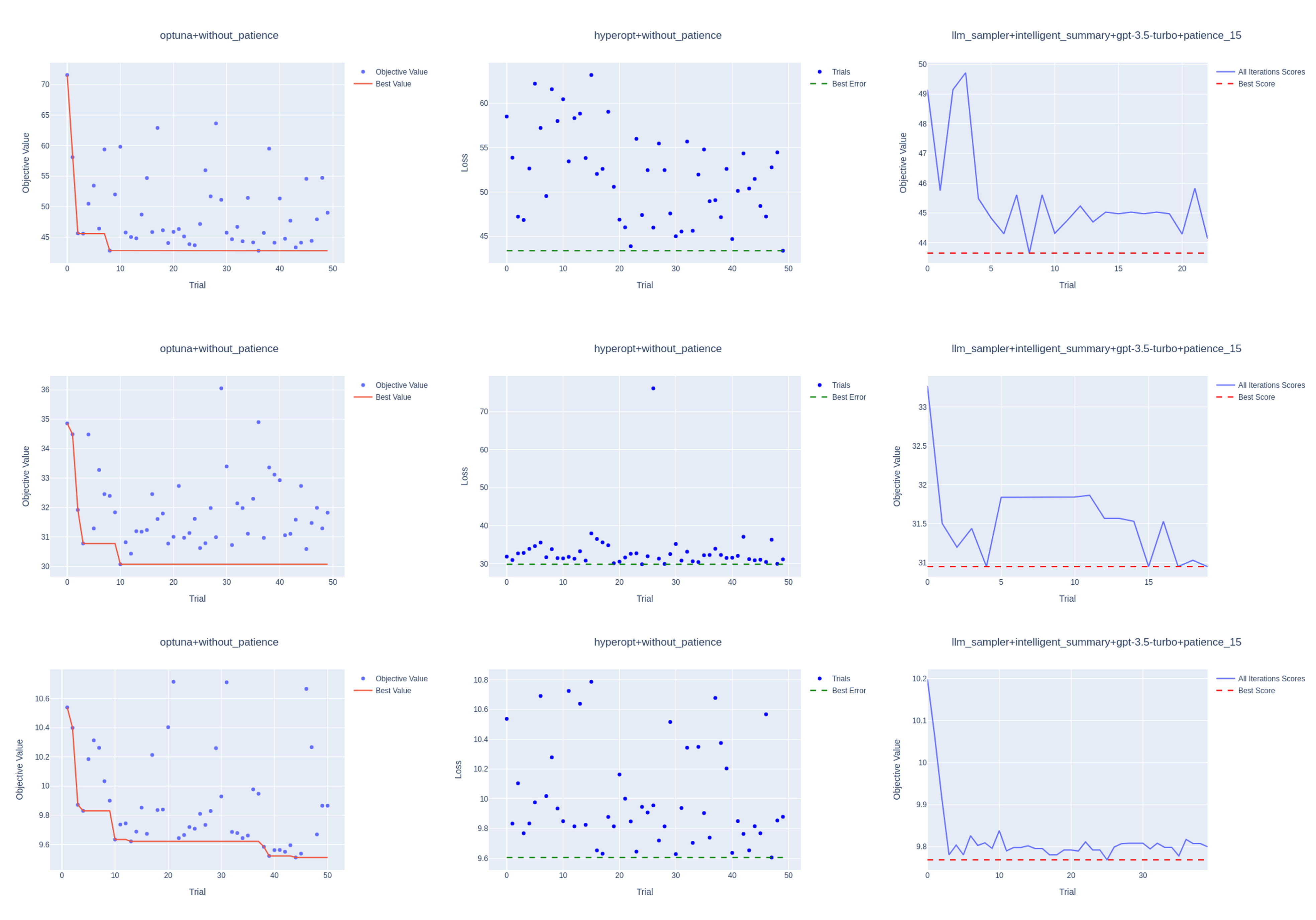
Figure 2: The Figure illustrates the optimization history for initial LLM HPO strategy with GPT-3.5-Turbo and intelligent_summary, Optuna, and Hyperopt strategies and LLM's early stopping. The top panel represents the energy dataset with the XGBoost model, the middle panel bike sharing dataset with LightGBM, and the bottom panel cement strength dataset with LightGBM.
Hybrid LLM-TPE Sampler
The LLM-TPE sampler significantly enhanced the balance between exploration and exploitation. By leveraging both LLMs' initialization strengths and TPE's exploration capacities, this hybrid approach achieved better HPO results across numerous datasets compared to the purely LLM-based and traditional BO methods.
Modifiers such as early stopping with variable patience demonstrated that LLM-powered strategies benefit from additional iterations to fully exploit their sampling strategies.
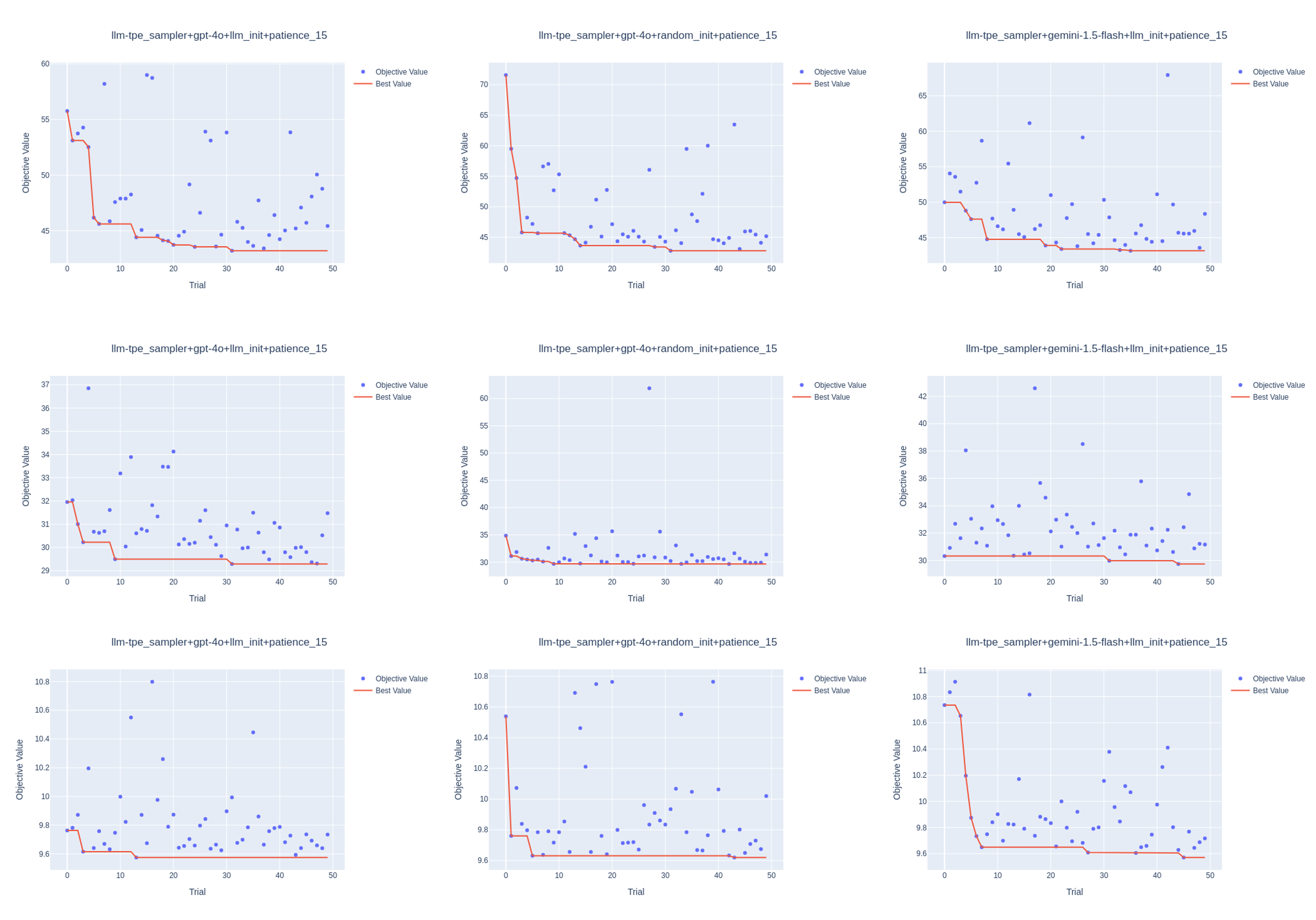
Figure 3: Optimization history plots for LLM-TPE Sampler with LLMs GPT-4o and Gemini-1.5-Flash with LLM-based initialization, also GPT-4o with random initialization. The top panel represents the energy dataset with the XGBoost model, the middle panel bike sharing dataset with LightGBM, and the bottom panel cement strength dataset with LightGBM.
Conclusion
The SLLMBO framework represents a significant advancement in hyperparameter optimization, effectively integrating LLM capabilities with TPE's exploration strategies. The results confirm the potential of LLMs in HPO, emphasizing the importance of combining complementary techniques to address limitations inherent in individual methods.
Future work could explore open-source LLMs for greater accessibility and apply the SLLMBO approach to complex domains like image processing, extending its applicability beyond tabular data. Further studies on handling reproducibility issues with LLMs may also provide valuable insights into consistent optimization results across trials.