- The paper introduces LLINBO, a hybrid framework combining LLMs with Gaussian Processes to improve reliability in black-box optimization tasks.
- It presents three methods—LLINBO-Transient, LLINBO-Justify, and LLINBO-Constrained—that balance exploration and exploitation using LLM insights and GP evaluations.
- The framework ensures robust performance with theoretical guarantees on cumulative regret, broadening its applicability in areas like drug discovery and hyperparameter tuning.
LLINBO: Trustworthy LLM-in-the-Loop Bayesian Optimization
Introduction
Bayesian Optimization (BO) is an effective tool for optimizing expensive black-box functions. It balances exploration and exploitation using a surrogate model and an acquisition function (AF) that evaluates the potential benefit of new query points. Traditional BO methods rely on Gaussian Processes (GPs) as surrogates, which offer uncertainty quantification, essential for a principled exploration-exploitation trade-off. Recent advances in LLMs have shown potential for optimization tasks due to their strong few-shot learning capabilities, which allow them to propose high-quality query points in black-box optimization (BBO) scenarios. Nonetheless, LLMs typically lack explicit surrogate modeling and calibrated uncertainty estimates, posing challenges in maintaining theoretical reliability and tractability.
To address these limitations, LLINBO (LLM-in-the-Loop Bayesian Optimization) is introduced as a hybrid framework combining the contextual reasoning strengths of LLMs with the principled uncertainty quantification offered by GPs. By employing LLMs for early exploration and relying on statistical models for guided exploitation, this framework aims to achieve more reliable optimization outcomes.
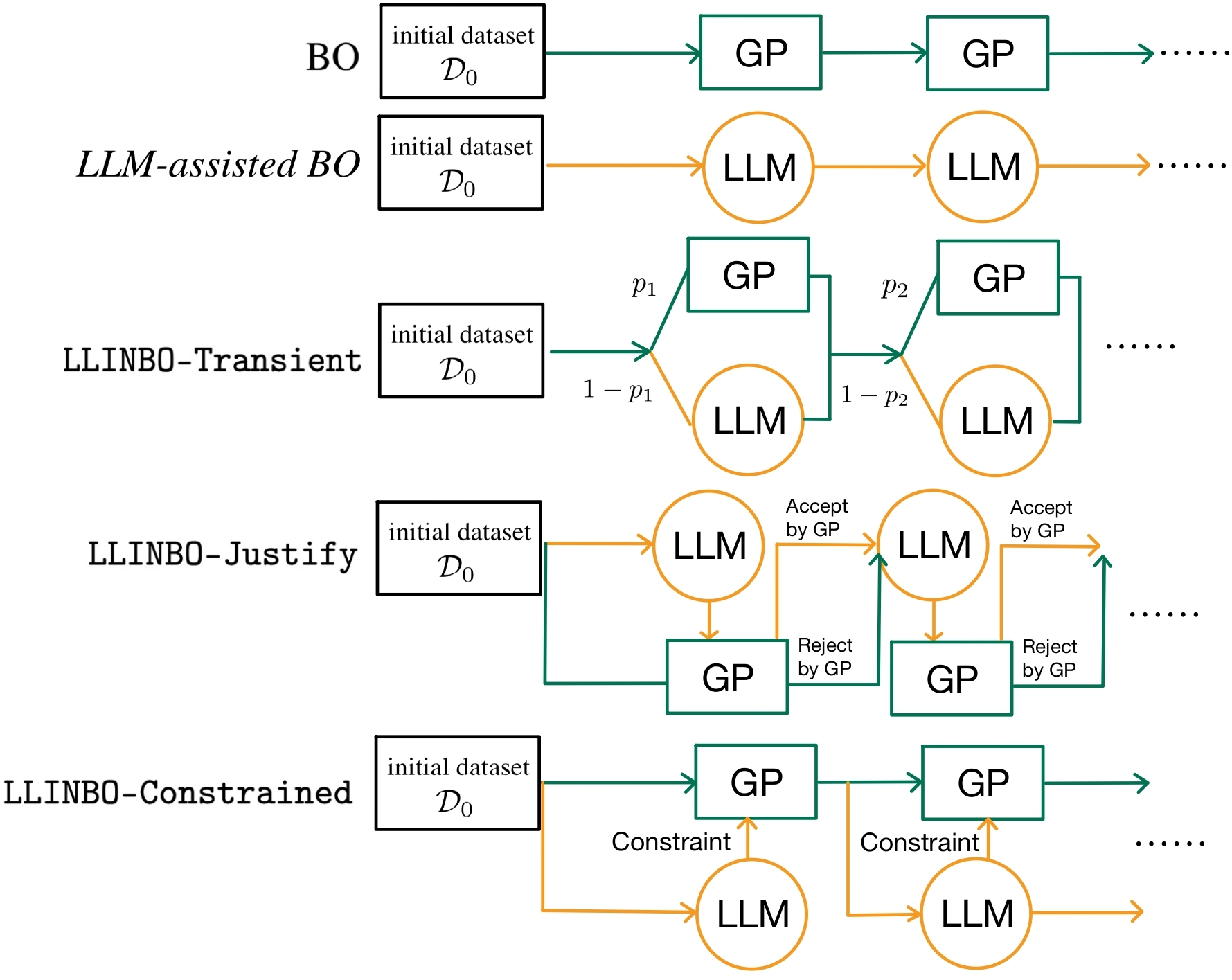
Figure 1: Diagrams of existing methods and the proposed algorithms: LLINBO-Transient, LLINBO-Justify, and LLINBO-Constrained.
LLINBO Framework
LLINBO consists of the following three approaches, each facilitating collaboration between LLMs and GPs in distinct ways:
- LLINBO-Transient:
- Approach: Combines exploration by LLMs with subsequent exploitation by GPs as more data accrues.
- Mechanism: At each iteration, a design is selected based on a probability, initially favoring LLM proposals and gradually transitioning to GP suggestions.
- LLINBO-Justify:
- Approach: Uses GPs to evaluate and selectively reject LLM-suggested designs that appear suboptimal.
- Mechanism: If the LLM's proposal does not meet a predefined threshold when assessed by the GP, it is replaced by the GP's design.
- LLINBO-Constrained:
- Approach: Directly incorporates LLM-generated designs into GPs as constraints, guiding subsequent model updates.
- Mechanism: Treats LLM suggestions as potentially optimal, updating posterior beliefs using constrained Gaussian Processes (CGPs).
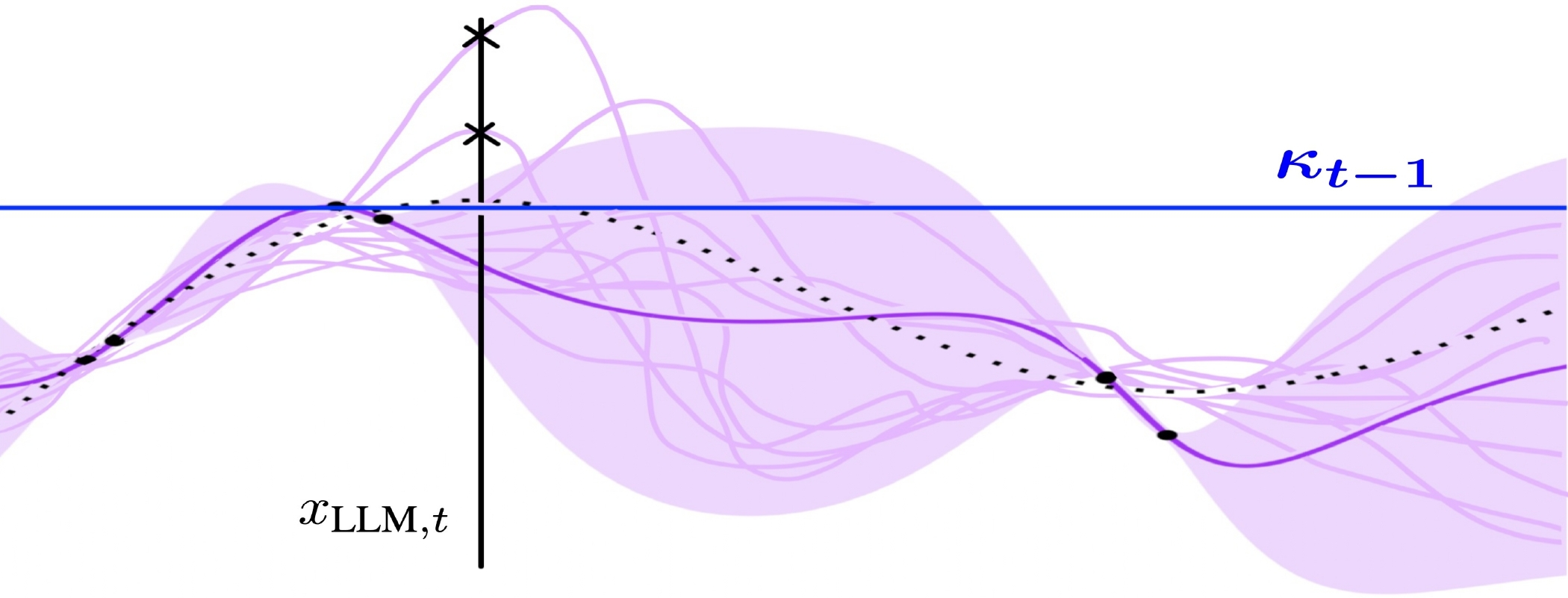
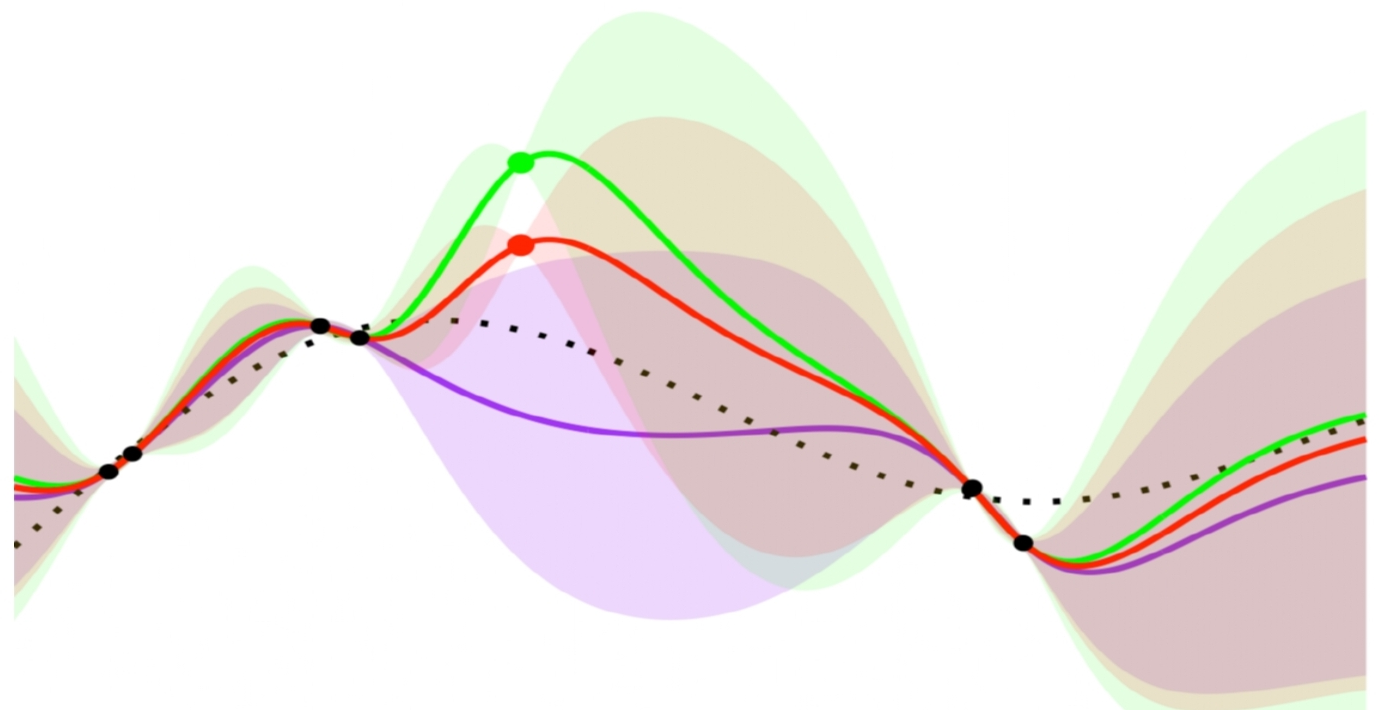
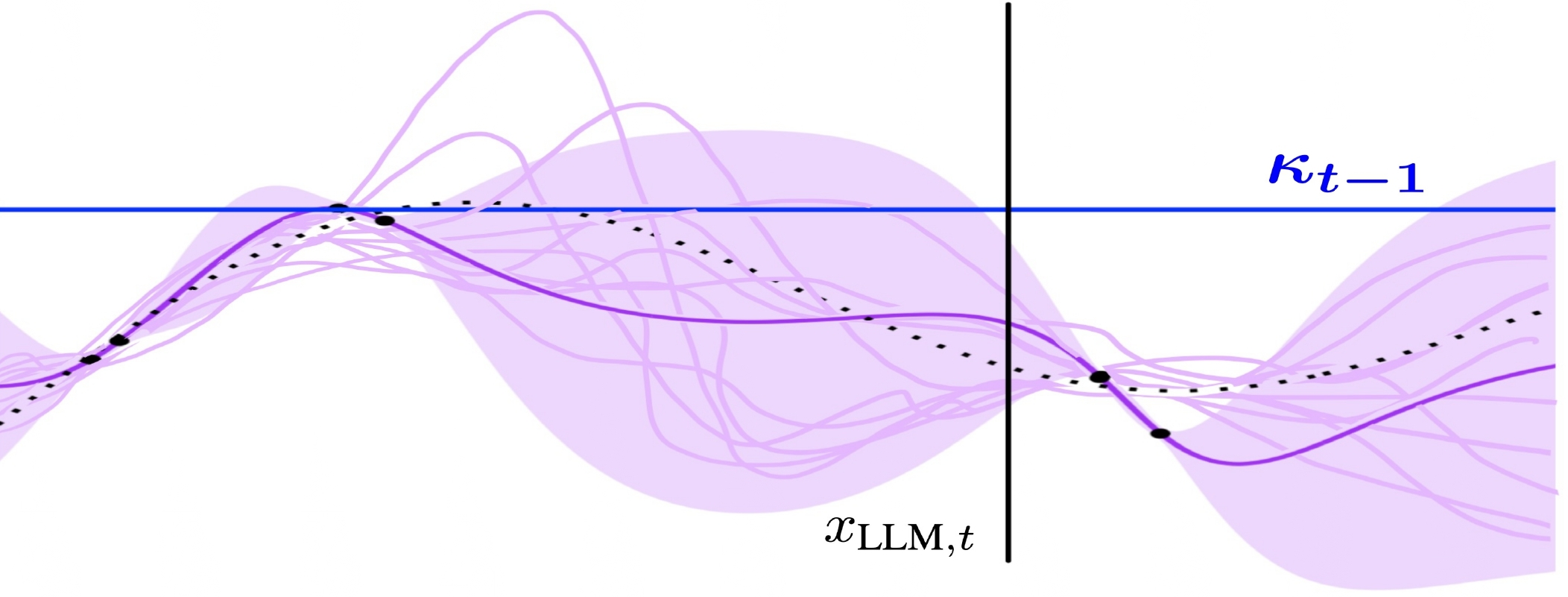
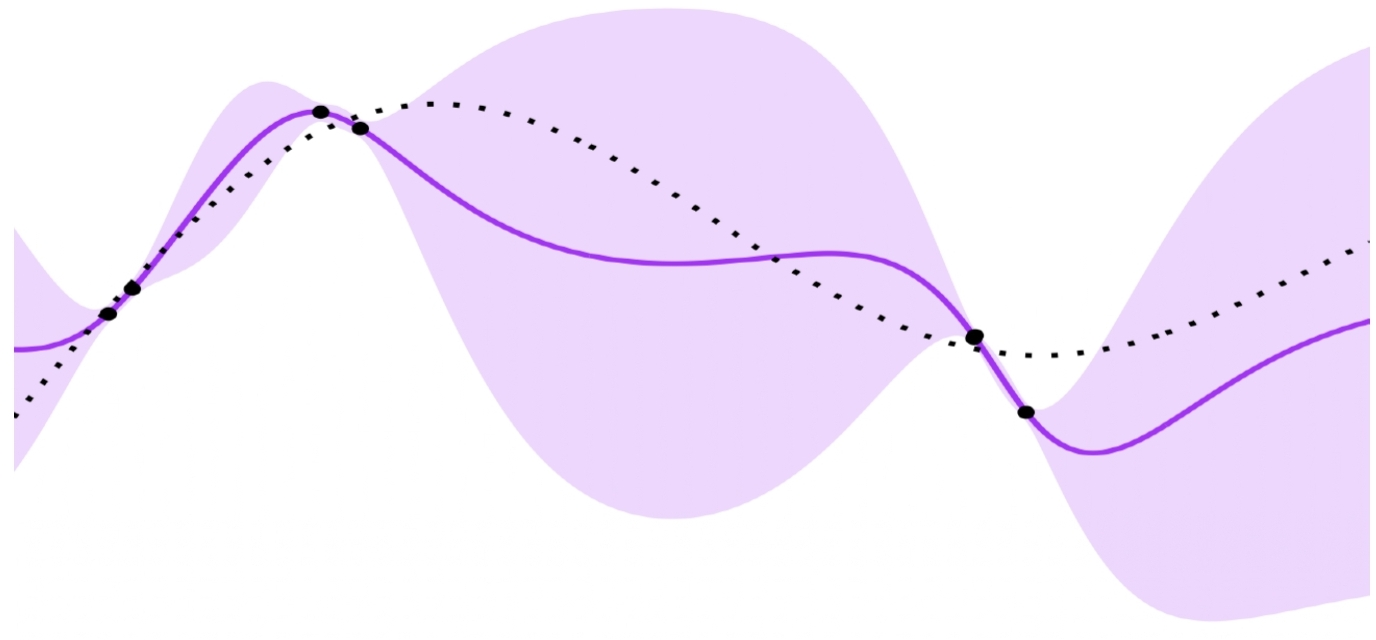
Figure 2: 10 realizations are sampled from Ft−1 and evaluated in LLINBO-Constrained.
Theoretical Guarantees
Each LLINBO approach provides theoretical guarantees regarding cumulative regret. For instance, LLINBO-Transient probabilistically reduces reliance on LLMs over time, effectively controlling the long-term regret through a decaying probability schedule. The framework ensures robust decision-making by integrating LLM's contextual insights with the statistical rigor of GP-based models.
Implications and Future Directions
The proposed LLINBO framework leverages the strengths of both LLMs and GPs, maintaining adaptability and reliability in optimization tasks. This strategic integration broadens the applicability of BO in scenarios involving costly evaluations or complex problem spaces, such as drug discovery or hyperparameter tuning.
Potential future work involves refining the interaction protocols between LLMs and GPs, developing adaptive mechanisms that more dynamically weigh the contributions of LLMs versus statistical surrogates, and further expanding the role of LLMs in more complex decision-making tasks beyond current applications.
Conclusion
The integration of LLMs with Bayesian optimization through LLINBO offers a promising pathway to enhance the robustness and efficiency of black-box optimization tasks. By systematically leveraging LLMs for initial exploration and GPs for guided exploitation, LLINBO addresses existing limitations of LLM-based optimization and introduces a reliable, hybrid approach to tackling complex problems across various domains.