- The paper introduces a novel metric to quantify self-preference bias by comparing LLM evaluators' tendencies to favor their own outputs over others.
- It demonstrates that lower output perplexity significantly increases bias, with models such as GPT-4 exhibiting pronounced self-favoritism compared to human judgments.
- The study suggests that ensemble evaluations could mitigate these biases, paving the way for fairer and more balanced automated assessment systems.
Self-Preference Bias in LLM-as-a-Judge
Introduction
The study of automated evaluation mechanisms using LLMs, known as LLM evaluators or LLM-as-a-judge, has been gaining traction due to their ability to provide scalable and consistent assessments in dialogue systems. However, a significant limitation of this approach is the self-preference bias, where LLMs tend to favor their own outputs over those generated by others. This paper introduces a novel quantitative metric to assess this bias and investigate its causes, emphasizing the pivotal role of output perplexity in this phenomenon.
Quantifying Self-Preference Bias
The study proposes a metric grounded in algorithmic fairness concepts to measure self-preference bias in LLMs during pairwise evaluations. The metric compares the likelihood that an LLM gives preference to its own output over others, aligning this with human preferences. Specifically, the bias is represented as the difference in the probability of an evaluator favoring its own response versus another response, when both are rated favorably by humans.
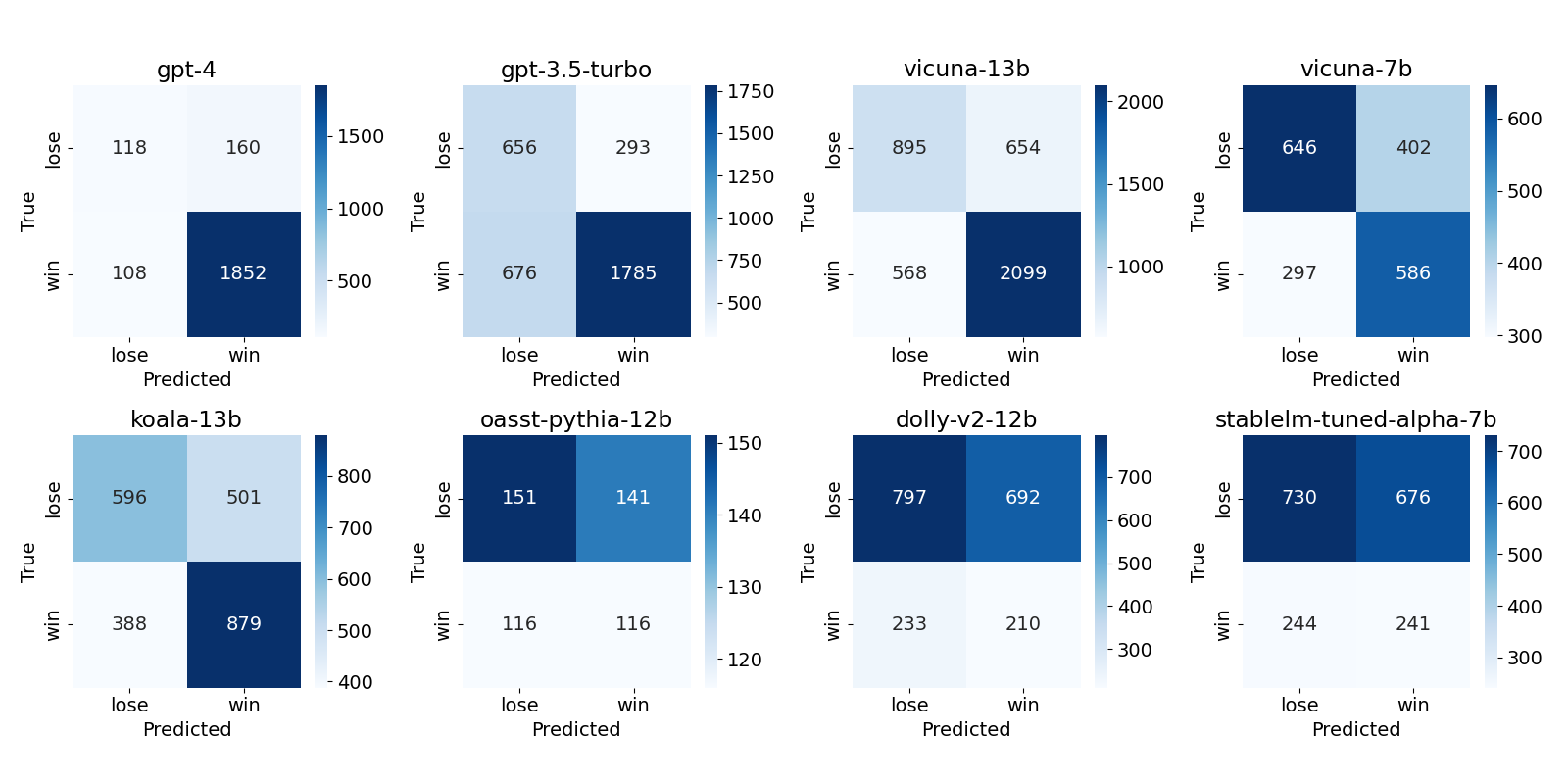
Figure 1: Confusion matrix for each LLM evaluator's assessment of pairs including its own output. It suggests that some LLMs, including GPT-4, have relatively high true positive rates compared to true negative rates, indicating self-preference bias.
The experimental setup involves using a dataset from Chatbot Arena with LLMs such as GPT-3.5-Turbo, GPT-4, Vicuna-13b, and others. The primary task is to evaluate two responses to a user query, analyzing evaluation scores to determine the degree of bias.
Results
Empirical analysis reveals that GPT-4 exhibits a pronounced self-preference bias. When evaluated against human judgments, GPT-4 favored responses it generated significantly more than human evaluators did. A notable finding is that other models like Vicuna-13b and Koala-13b also display this bias, whereas some models like oasst-pythia-12b and dolly-v2-12b exhibit reverse bias, underestimating their own outputs.
Impact of Perplexity on Bias
A major hypothesis explored in this research is the impact of text familiarity, measured through perplexity, on self-preference bias. LLM evaluators are found to assign higher scores to responses with lower perplexity, which are more familiar or predictable to them. This behavior was consistent across most LLMs evaluated, suggesting a systemic bias rooted in training data familiarity rather than response quality alone.
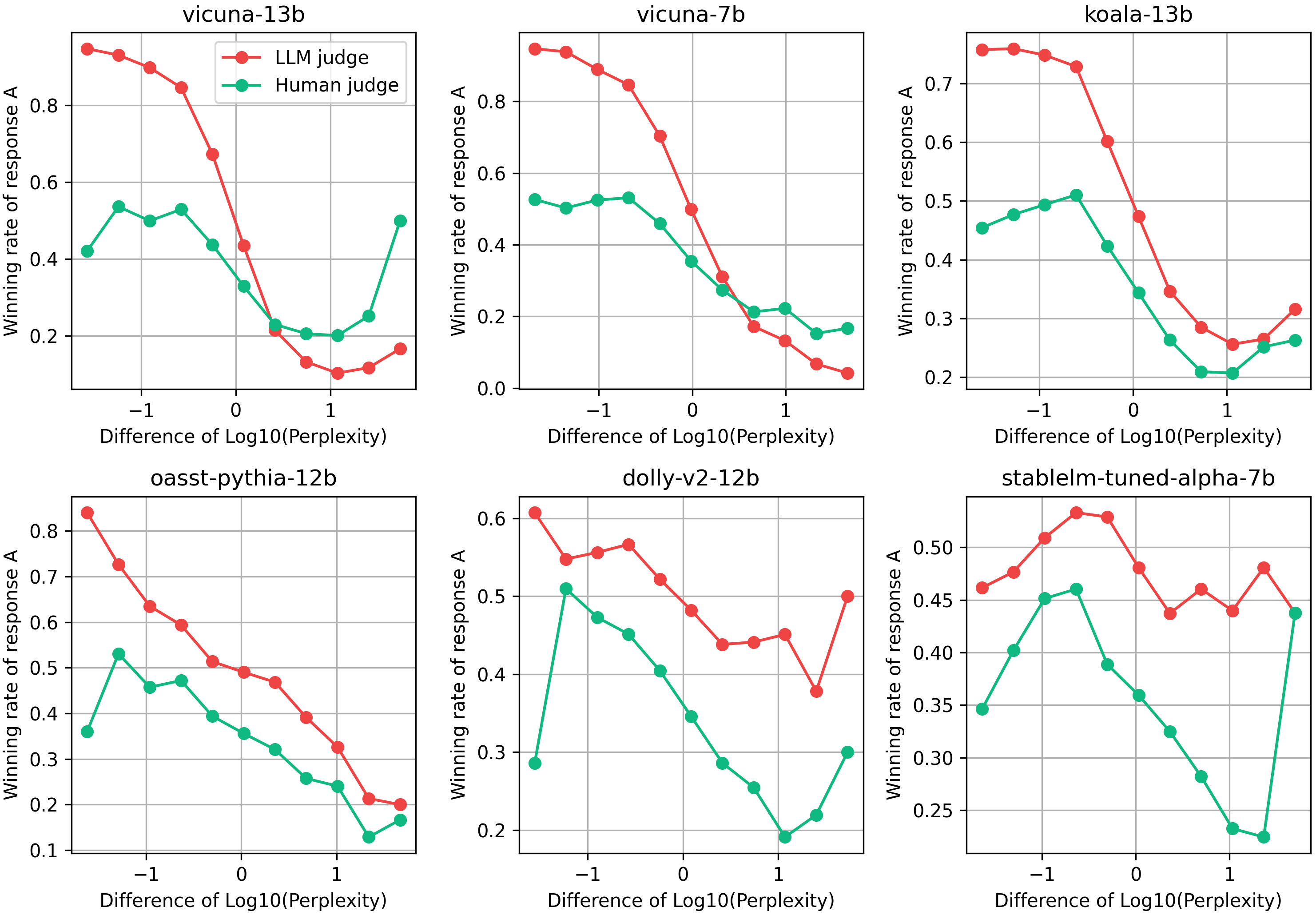
Figure 2: LLMs vs human conditioned on perplexity. Winning judgment rates by LLMs conditioned on perplexity with human winning judgment rates are plotted. All models except dolly-v2-12b and stablelm-tuned-alpha-7b demonstrated a clear tendency to assign higher evaluations to responses with lower perplexity.
The perplexity-based bias was observed irrespective of whether the response was self-generated or produced by other models, revealing this as a broader issue not confined to merely recognizing one's own outputs.
Discussion
The findings illuminate potential avenues to mitigate self-preference bias, such as employing ensemble evaluations across multiple models to prevent any single model's peculiarities from unduly influencing overall judgments. Additionally, these results underscore the necessity to account for model familiarity bias when designing LLM evaluators, to avoid perpetuating inherent model biases in automated assessments.
Conclusion
This research presents a comprehensive approach to quantifying and understanding self-preference bias in LLM evaluators. By linking this bias to perplexity, it opens pathways for addressing such biases in future LLM development and deployment. The proposed metric provides a foundation for further exploration and potential rectification of biases in LLM-as-a-judge scenarios, ensuring fairer and more balanced automated evaluation systems.