- The paper introduces LongPPL, a metric that focuses on key tokens influenced by extended context to overcome standard perplexity limitations.
- It shows that LongPPL correlates strongly with task performance (Pearson -0.96), offering superior evaluation in long-context benchmarks.
- The proposed LongCE fine-tuning strategy further enhances model performance on long-context tasks, achieving improvements up to 22%.
Analysis of "What is Wrong with Perplexity for Long-context Language Modeling?"
Introduction
This paper demonstrates the inadequacies of traditional Perplexity (PPL) as a metric for evaluating the long-context capabilities of LLMs. The authors identify that PPL, due to its averaging nature across all tokens, fails to highlight the model's performance on long-context tasks. To address this, they introduce LongPPL, a novel metric that emphasizes key tokens derived from long-short context differences. They provide extensive empirical evidence showcasing the superior performance of LongPPL and a newly proposed fine-tuning method, LongCE, in capturing long-context capabilities.
Limitations of Perplexity for Long-context Modeling
While perplexity has been a standard metric for assessing LLMs, it fails to reflect the nuanced capabilities required for long-context tasks. The authors demonstrate that PPL's tendency to average probability scores across all tokens dilutes the emphasis on those tokens most influenced by extended context.

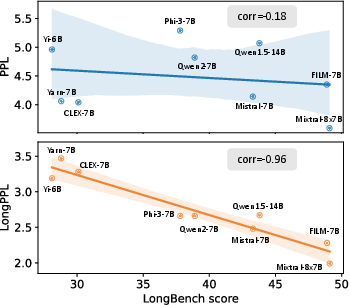
Figure 1: A constructed example to illustrate how LongPPL is calculated.
Perplexity predominantly measures token prediction based on immediate preceding tokens, thus missing out on capturing dependencies that stretch over longer contexts. This limitation implies a retained focus on frequently appearing but less contextually significant tokens while eclipsing those critical for evaluating long-context understanding.
Proposal of LongPPL
LongPPL is introduced as an advanced metric tailored for long-context scenarios. Unlike standard PPL, which considers token predictions over an entire sequence, LongPPL restricts its focus to "key tokens" affected by long-range dependencies. This approach ensures that the evaluation metric directly correlates with the LLM’s competency in utilizing extended context.
The methodology involves calculating the Long-Short Difference (LSD) for each token—the variance between its generation probability in long versus truncated contexts. A high LSD denotes a token highly impacted by long-term dependencies, earmarking it as a key token to be weighted more in LongPPL calculations.
Key Contributions and Results
The paper presents several key findings and contributions:
- Identification of Key Tokens: By isolating tokens that significantly benefit from long-context inputs, the authors redefine the criteria for evaluating LLM performance on tasks like document summarization and extended dialogues.
- LongPPL's Strong Correlation with Task Performance: Empirical evaluations show that LongPPL correlates strongly with model performance across various benchmarks. For instance, it reports a Pearson correlation of -0.96 with long-context task accuracy, significantly outperforming traditional PPL.

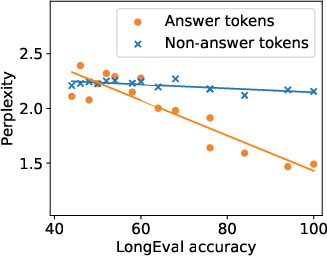
Figure 2: The correlation between accuracy and perplexity on different token types in the LongEval task.
- LongCE Loss Function: Leveraging the insights from LongPPL, the authors introduce LongCE, a fine-tuning strategy that prioritizes key tokens during training. This approach leads to improvements in long-context comprehension without sacrificing performance on shorter inputs.
- Evaluation Benchmarks: The experiments conducted across multiple LLMs demonstrate that LongCE consistently enhances model accuracy, with improvements reaching up to 22% in some long-context benchmarks.
Conclusion
The analysis underscores the inefficacy of standard PPL in capturing the intricacies of long-context tasks. By introducing LongPPL and LongCE, the authors provide robust tools for both evaluating and training LLMs in scenarios requiring the processing of extensive contextual information. This work lays foundational insights into the intricacies of modeling long-range dependencies and provides practical metrics and methods for advancing LLM capabilities.
These contributions offer novel insights into adapting existing models for specialized tasks requiring a comprehensive handling of extended context, crucial for applications in complex text generation, in-depth conversational AI, and holistic document understanding. Future directions may explore finer granularity in token significance assessment and the integration of these metrics into more dynamic adaptive learning frameworks.