- The paper introduces a novel joint training framework that simultaneously optimizes classifiers and deferral policies for improved selective prediction accuracy.
- It employs reinforcement learning with a reward signal specifically designed to balance prediction accuracy and deferral rates in diverse applications.
- Experimental results on STEM assessments highlight enhanced SP accuracy, underlining the method’s potential for robust human-in-the-loop systems.
Joint Training for Selective Prediction
The paper "Joint Training for Selective Prediction" introduces a novel method to train classifiers alongside deferral policies, optimizing both simultaneously for selective prediction (SP) tasks. This approach aims at leveraging machine learning to enhance automated decisions with human oversight, addressing challenges in human-in-the-loop systems. The study illustrates advanced training regimens and novel architectures, demonstrating improved SP accuracy compared to traditional methods. Key topics explored include SP methodologies, joint optimization strategies, and practical applications to student assessments using STEM questions.
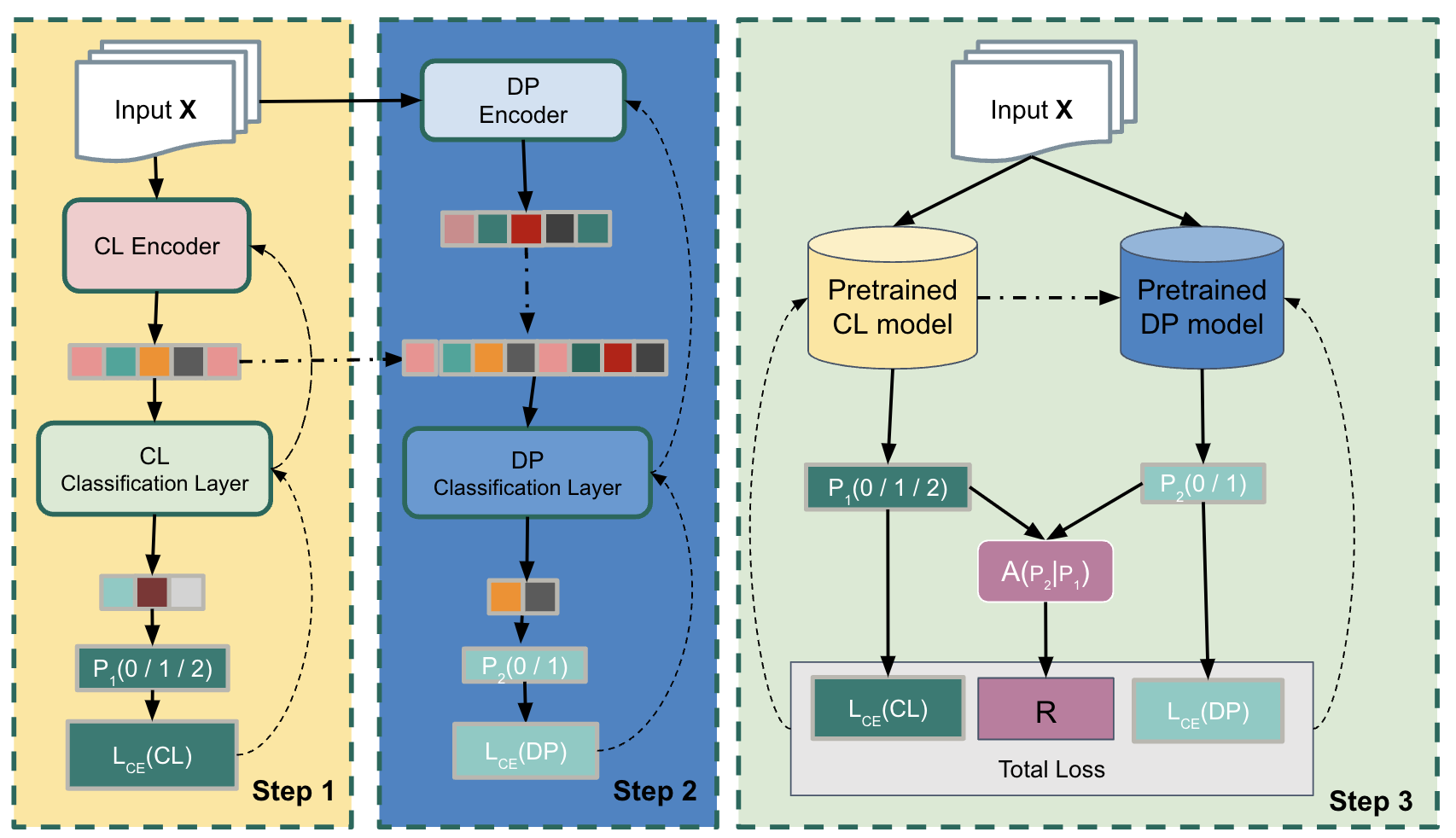
Figure 1: The model architecture with three steps. CL is the classification model of the given task, DP is the Deferral Policy model.
Selective Prediction Methodologies
Selective Prediction involves utilizing model outputs when confidence is sufficient and deferring when uncertain. The paper explores different methodologies for SP improvements, from calibrating classifier confidence using softmax outputs to deploying separate deferral models. Previous SP approaches often used techniques to estimate classifier confidence or focused on improving direct model prediction accuracy through engineered features.
Architecture and Joint Training Approach
The paper introduces Joint Training for Selective Prediction (JTSP), a framework combining classifier models and deferral policies within a unified system. JTSP optimizes both components by learning distinctive representations that cater to their specific roles. This parallel optimization, as opposed to serial or independent training, empowers the classifier to produce more reliable probabilistic outputs which inform the deferral policy's decision-making process.
The architecture of JTSP involves three distinct phases. Initially, classifiers undergo a warm-up period focusing on typical cross-entropy loss. Subsequently, the deferral policy experiences its training epoch, relying on classifiers' outputs and a reinforcement learning component incorporated during joint training.
Training Regimen and Reward Signal
The training regimen of JTSP employs a novel strategy that allows concurrent optimization of classifiers and deferral policies. It incorporates a reward signal, R, from reinforcement learning, evaluating action taken—whether to defer or to predict—against actual outcomes. The signal is devised to enhance SP accuracy while balancing deferral rates, thus tailoring the system for specific applications.
The complexity of training arises from balancing SP accuracy and deferral rates. The paper suggests methods to tune hyperparameters and manage the reward signal's impact through systematic experimentation.
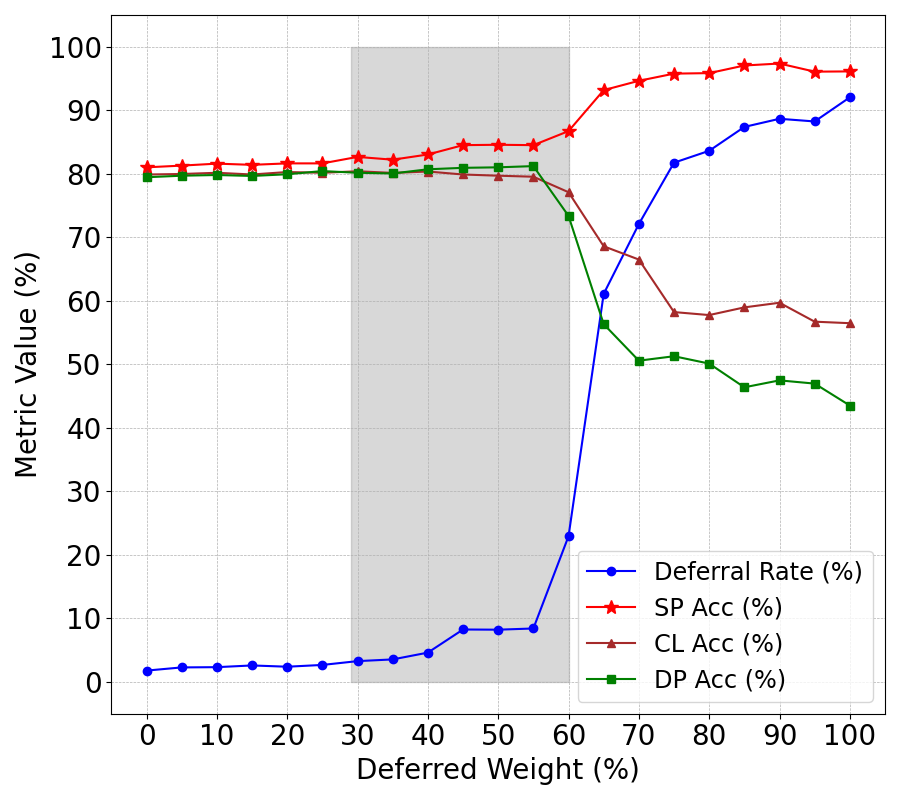
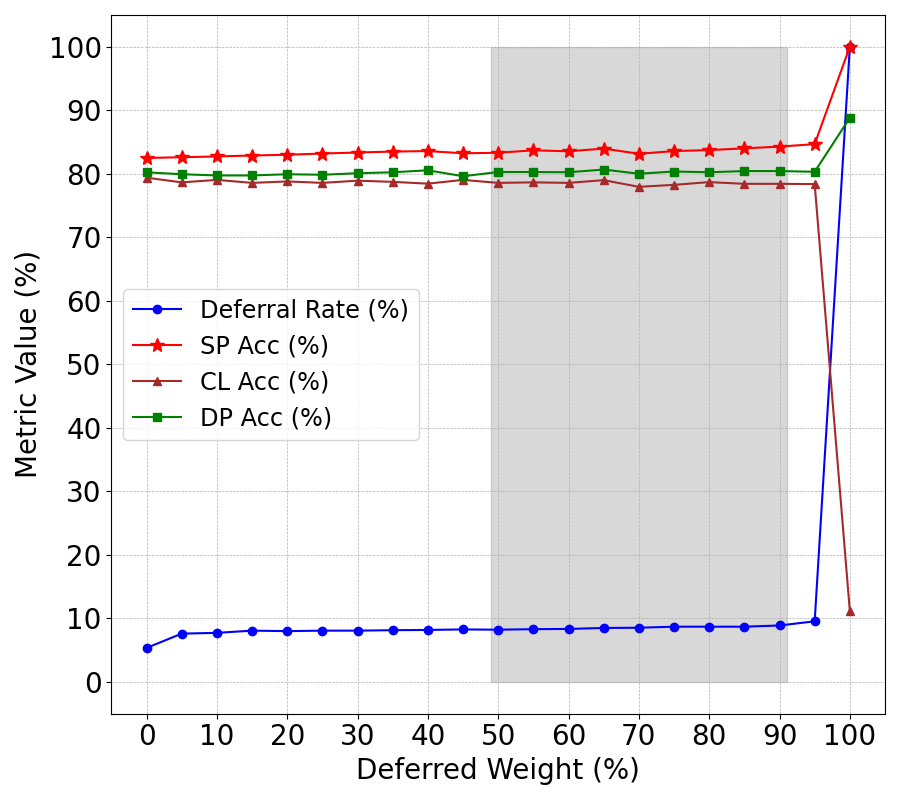
Figure 2: JTSP with SFRN classifier.
Experimental Results and Analysis
Numerical results from four STEM assessment datasets highlight JTSP's superior performance over existing SP approaches. Key metrics include classifier accuracy, deferral policy accuracy, selective prediction accuracy, and deferral rates. SFRN classifiers, specifically designed for short-answer assessments, exhibited the best performance within the JTSP framework, indicating the importance of architectural compatibility within SP systems.
The sensitivity analysis of reward signal weights revealed significant dependencies between deferral rates, SP accuracy, and other metrics, emphasizing JTSP's nuanced dynamics in optimizing deferral decisions.
Discussion and Implications
JTSP demonstrates considerable advancements in SP systems by improving classifier outputs and optimizing deferral policies. Despite apparent challenges in reward signal design and system tuning, the methodology holds promise for broader classification tasks and applications. Further exploration into model selection and adaptive training paradigms could drive future developments, enabling more robust, flexible SP systems.
Conclusion
The exploration of Joint Training for Selective Prediction uncovers significant enhancements to SP processes, through parallel optimization and enhanced representation learning. This comprehensively addresses the challenge of integrating machine learning models into human-in-the-loop systems, proving effective in assessments and potentially numerous other tasks. Future work could enhance reward mechanisms and broaden applicability across diverse domains.