- The paper presents L-GATr, which explicitly encodes Lorentz symmetry using geometric algebra to dramatically reduce sample complexity in high-energy physics tasks.
- It incorporates equivariant transformer layers with grade-separated linear projections, geometric inner product-based attention, and controlled symmetry breaking via reference vectors.
- Benchmark results demonstrate sub-percent amplitude regression error and superior jet tagging performance, achieving competitive results with significantly smaller datasets.
Introduction and Motivation
The work "A Lorentz-Equivariant Transformer for All of the LHC" (2411.00446) addresses foundational limitations in high-energy physics (HEP) machine learning: the need to encode Lorentz symmetry efficiently in architectures that operate on variable-length sets of particles, to yield state-of-the-art performance across regression, classification, and generative tasks relevant to the Large Hadron Collider (LHC). Traditional deep models, even modern transformers and graph neural networks, require significant sample complexity to "learn" domain symmetries such as the Lorentz group, which underpins relativistic kinematics. The presented Lorentz-Equivariant Geometric Algebra Transformer (L-GATr) explicitly incorporates Lorentz symmetry via geometric algebra, providing maximal expressivity and data efficiency for variable-multiplicity collider events, and introduces novel symmetry-breaking mechanisms to handle partial symmetry violation (e.g., beam-axis and detector effects).
Geometric Algebra over Minkowski Space
L-GATr leverages the spacetime geometric algebra G1,3, extending R4 with a graded structure encompassing scalars, vectors, bivectors, trivectors, and pseudoscalars. Each grade corresponds to a distinct irreducible Lorentz representation (scalar: invariant, vector: four-momentum, bivector: area, etc.). This allows multivector-based encoding of particle features—e.g., combining four-momenta and particle IDs into a 16-dimensional real-valued vector, with precise transformation rules under the full Lorentz group.
L-GATr is a strict generalization of the standard transformer [vaswani2017attention], with every layer—including linear projections, attention, layer normalization, and nonlinear activation—constructed to be Lorentz-equivariant at the multivector level. Grade-wise operations enforce that, for x a multivector and Λ a Lorentz transformation, L-GATr(Λx)=Λ[L-GATr(x)].
Key modifications include:
- Linear transformations: grade-separated, learnable weights, allowing limited symmetry breaking via optional γ5 mixing.
- Attention: scaled dot-product over the geometric-algebra inner product, yielding exact equivariance.
- Layer normalization: grade-wise norm computations with absolute-value stabilization for indefinite metrics.
- Activations: scalar-gated nonlinearities (GELU) acting only on the scalar channel to preserve equivariance.
- Geometric product: explicit multiplicative nonlinearity between multivectors, inherently equivariant.
Reference Vector Symmetry Breaking
To address practical LHC settings where Lorentz symmetry is only approximate (due to beam axis and detector effects), L-GATr introduces tunable symmetry breaking via the inclusion of reference multivectors (e.g., beam direction, temporal basis) supplied as extra tokens or channels. This partially breaks Lorentz invariance in a controlled way, enabling superior performance for tasks where only certain subgroups (e.g., SO(2) about the beam) are physical symmetries.
Scaling Properties and Resource Utilization
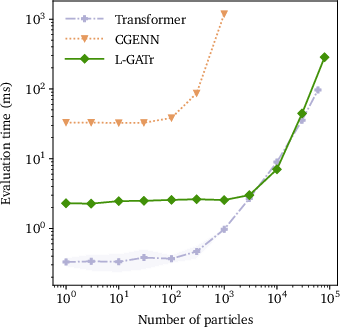
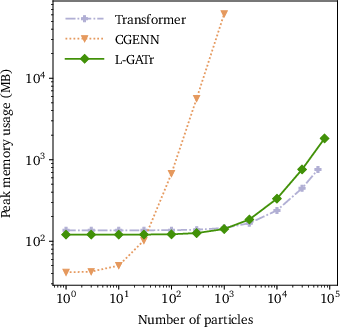
Figure 1: Scaling behavior of L-GATr, baseline transformer, and CGENN graph network in evaluation time and memory as a function of number of tokens (particles).
L-GATr matches the computational scaling of baseline transformers, with quadratic time and linear memory cost in the number of particles due to dense attention, but outperforms CGENN equivariant graphs, which become prohibitive in fully-connected regime.
Amplitude Regression
L-GATr is benchmarked for surrogate modeling of high-multiplicity QCD amplitudes (qqˉ→Z+ng). It achieves superior mean squared error at multiplicities n≥3, maintaining sub-percent accuracy with dramatically reduced training set requirements compared to standard MLPs, transformers, and deep sets.
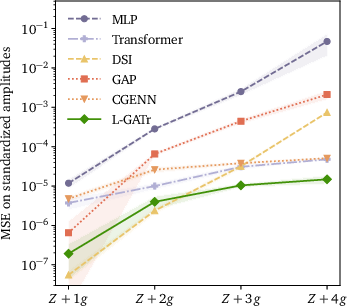
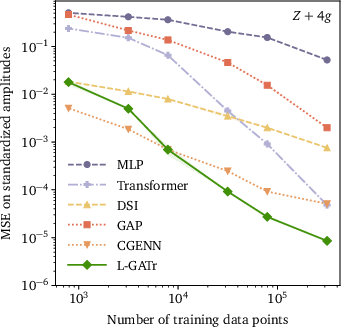
Figure 2: Left: prediction error vs. gluon multiplicity; Right: prediction error vs. training set size, L-GATr vs. baselines for amplitude regression.
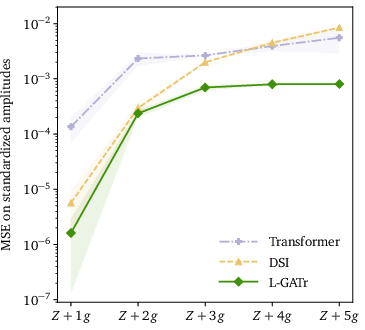
Figure 3: Prediction error for Z+5g amplitude regression in the small-data regime, L-GATr vs. baselines.
This data efficiency is attributed to explicit Lorentz equivariance and permutation symmetry, enabling scaling to five-gluon final states with over an order of magnitude smaller networks and data.
Jet Tagging
For jet classification, L-GATr sets new benchmarks on both binary (top tagging) and multiclass (JetClass) datasets.
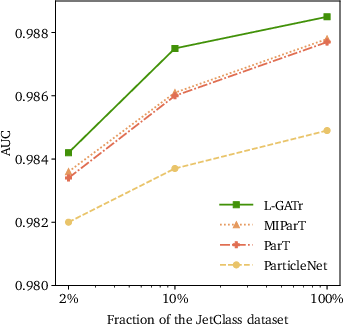
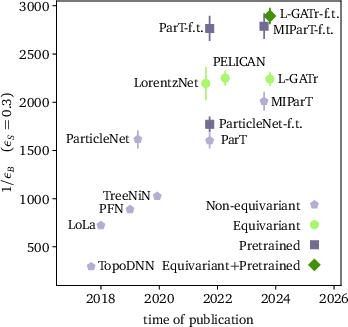
Figure 4: JetClass AUC metric as function of training set size (left) and historical evolution of leading taggers (right).
Key empirical claims:
- On the standard top tagging dataset, L-GATr matches or slightly outperforms all prior Lorentz-equivariant and transformer-based architectures. With JetClass-based pretraining and fine-tuning, it attains the highest reported AUC and background rejection at fixed signal efficiency.
- On multiclass JetClass, L-GATr outperforms ParT and MIParT across all metrics and achieves competitive results with only 10% of full data, reinforcing the practical benefit of built-in symmetry.
Generative Modeling of LHC Events
L-GATr is further incorporated as the velocity model in a CFM-based continuous normalizing flow for event generation (pp→ttˉ+n jets). By modeling transitions along symmetry-respecting trajectories and enforcing Lorentz-covariant base distributions, it outperforms MLP- and transformer-based CFMs in both negative log-likelihood and classifier-based two-sample AUC, particularly in learning subtle angular correlations.

Figure 5: Illustration of L-GATr velocity construction for conditional flow matching.

Figure 6: Example generator 1D marginal distributions for ttˉ+n jets, n=1–4, for L-GATr and baselines.
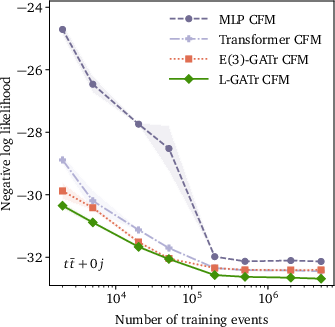
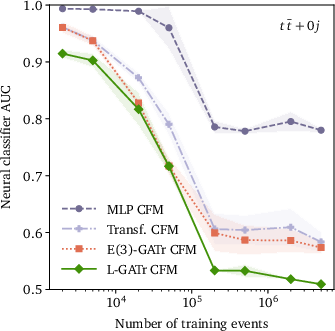
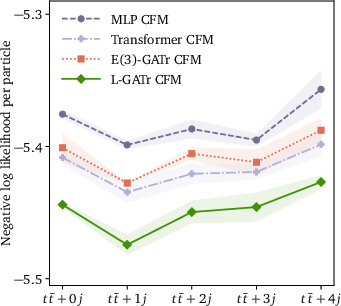
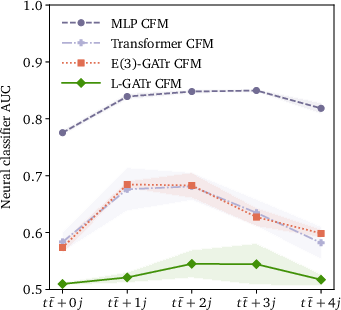
Figure 7: Generative performance vs. data-set size (top row) and multiplicity (bottom row), in NLL (left) and classifier AUC (right).
The most salient empirical claim is that enforcing (and then selectively breaking) Lorentz equivariance via reference vectors yields strictly better performance than non-equivariant alternatives, even when the underlying task does not fully uphold symmetry.
Theoretical and Practical Implications
Theoretical Significance
- The geometric algebra formalism provides a mathematically rigorous, maximally expressive representation for spacetime symmetry across network layers and tasks, which can underpin future multi-modal or multi-task high-energy physics applications.
- The reference vector mechanism enables seamless adaptation to practical, symmetry-broken real-world data—bridging the idealized equivariance of theory and compromised experimental reality.
Practical Implications for LHC and Beyond
- For regression and density modeling, L-GATr can reduce required MC simulation effort by orders of magnitude, making per-mille-level amplitude and generative surrogate learning feasible for phenomenologically relevant multiplicities.
- For classification, strong data efficiency and transfer-learning capability amplify the impact of pretraining on large, realistic collider jet datasets.
- The architecture is highly scalable and compatible with modern optimization and deep learning infrastructure, facilitating broad deployment.
Outlook and Potential Directions
Looking forward, L-GATr's approach provides the foundation for further extensions in theory-informed machine learning at the LHC and other relativistic domains:
- Incorporation of more general representation theory beyond G1,3, for applications involving higher-rank symmetric tensors.
- Integration into multipurpose simulation workflows (detector, parton-level, full event-with-systematics) and simulation-based inference paradigms [cranmer2020frontier, brehmer2022simulation].
- Deployment for data-driven anomaly detection, efficient uncertainty quantification (Bayesian generalization), and cross-experiment transfer learning.
Conclusion
L-GATr represents a formal unification of deep symmetry-aware representation learning and scalable transformer architectures for LHC data analysis. Its superior performance in amplitude regression, jet classification, and event generation demonstrates both strong numerical advances and a new paradigm for fusing physical symmetries with machine learning. Through explicit Lorentz-equivariant encoding, combined with practical symmetry-breaking via reference vectors, L-GATr achieves unprecedented efficiency and accuracy, paving the way for new applications in precision collider theory, experiment, and simulation-based inference (2411.00446).
References:
- (2411.00446) "A Lorentz-Equivariant Transformer for All of the LHC"
- Additional references cited within the main text and architecture comparisons
