- The paper demonstrates that packet header-based features, rigorously selected through cross-dataset validation and genetic search, vastly improve generalization compared to flow-based statistical features (e.g., achieving ~0.78 F1 vs. <0.50 F1).
- The methodology employs a multi-stage evaluation pipeline that mitigates overestimated performance from cross-validation by using session and dataset splits, highlighting the risk of information leakage.
- The resulting Random Forest model is deployable for real-time IoT device identification, offering enhanced security and operational scalability in diverse network settings.
GeMID: Advancing Generalizable IoT Device Identification Models
Problem Statement and Motivation
The increasing proliferation of IoT devices has substantially elevated the attack surface in residential and enterprise networks, rendering device identification (DI) a critical capability for enforcing network segmentation, access control, and vulnerability management. Traditional ML-based DI approaches—often leveraging flow or window-based statistical features—fail to generalize robustly across distinct network environments, leading to unreliable performance under domain shift. This paper introduces GeMID, a comprehensive methodology and empirical study aimed at addressing the core challenge of building generalizable DI models, and explicitly demonstrates the failure of conventional flow/statistical features to transfer across diverse IoT network conditions.
Data Foundation and Preprocessing
GeMID employs two major dataset families for rigorous evaluation:
- UNSW-DI/UNSW-AD: Used for feature/model selection, these datasets provide consistent device overlap, but are sourced from different sites/times, ensuring environmental variation.
- MonIoTr (UK/USA): Used exclusively for out-of-domain testing, with shared devices deployed in geographically and topologically distinct environments.
The device coverage and intersection of these datasets are central to the strict cross-domain experimental design:

Figure 1: Device intersections between the UNSW-DI and UNSW-AD datasets, highlighting the evaluation’s dependence on shared device classes.

Figure 2: Device overlap in MonIoTr datasets collected from UK and USA labs, enabling robust cross-site evaluation.
Packet capture preprocessing is conducted with a focus on extracting features exclusively from protocol headers (excluding all address/string identifiers and payload data) across a comprehensive set of protocols (DNS, TCP, UDP, ICMP, etc.), yielding a highly granular, protocol-centric initial feature pool (>300 attributes). This deliberate avoidance of flow/time-based statistics is foundational to GeMID's hypothesis of generalizability.
Feature Selection Pipeline and Critique of Statistical Features
The paper provides a multi-stage, cross-dataset feature selection architecture. Initially, each individual header feature is assessed for predictive strength using: (i) intra-session cross-validation (CV), (ii) session-versus-session (SS), and (iii) dataset-versus-dataset (DD) splits.
A critical analytic finding is that CV vastly overestimates feature utility, revealing severe information leakage even in standard 5-fold cross-validation.
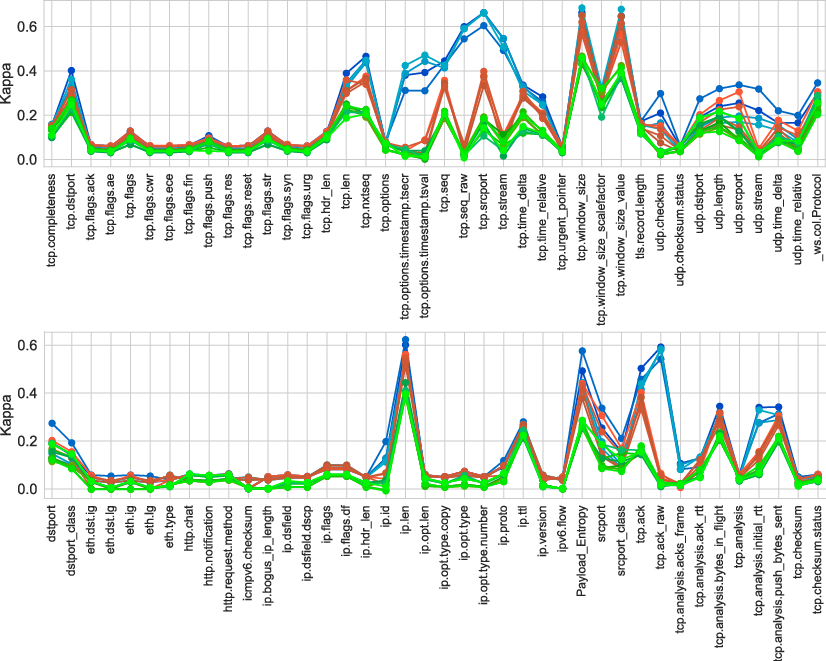
Figure 3: Overestimated feature utility (CV, blue) vs. more realistic evaluations (SS, red; DD, green) for header- and statistical features—demonstrating the leakage risk of CV in DI.
The authors employ a voting mechanism over 16 evaluation contexts, using positive kappa scores to downselect the most robust features. Only features with consistent predictive power under the strictest DD splits are retained. Subsequently, feature interactions are explored using a wrapper-based genetic algorithm, with fitness driven by F1 aggregated over multiple DD contexts—crucially, external feedback from independent datasets is used to avoid selection bias.
Intersecting features from all GA sweeps are then aggregated by frequency, and grouped Vote+k feature sets (with k denoting minimal cross-context recurrence) are empirically evaluated.
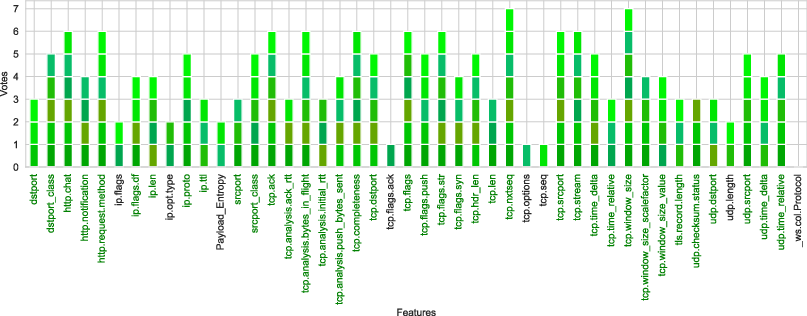
Figure 4: Features repeatedly selected as robust through GA-driven feature selection, with dark green markers denoting features ultimately incorporated in the final model.
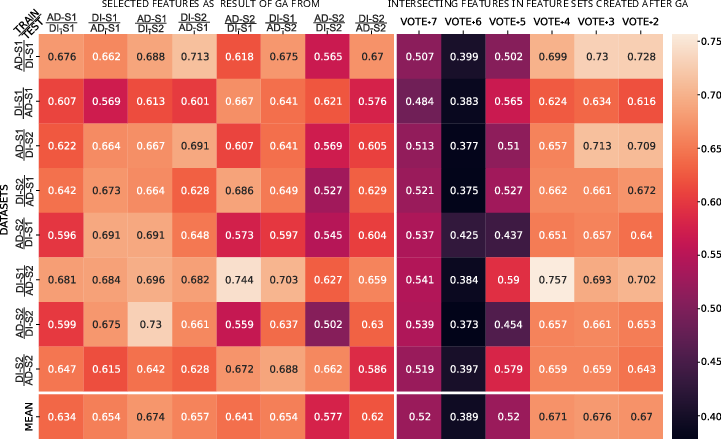
Figure 5: Performance heatmap evaluating each selected feature set's generalizability across all DD cases (left) and frequency-aggregated feature groupings (right), identifying the Vote+3 group as optimal.
Key empirical result: Packet header features with frequent selection across DD contexts drive the best generalization; flow and window statistics are consistently fragile, corroborating theoretical intuitions about their environment-specific dependence.
Model Selection, Evaluation, and Quantitative Findings
A comprehensive ML algorithm comparison is performed, with Random Forest (RF) and XGBoost (XGB) emerging as Pareto-optimal in the accuracy/inference-time tradeoff space. The optimal feature set feeds a compact RF classifier that is fast enough for real-time operations.
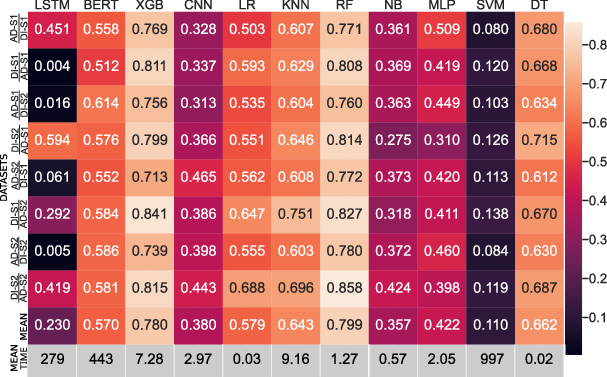
Figure 6: RF and XGB provide top generalization accuracy, with RF preferred for its markedly reduced inference latency.
A pivotal section is the comparative evaluation against alternatives:
- GeMID (header-based): ~0.78 mean F1 (DD context).
- IoTDevID (prior header-based): ~0.70 mean F1 (DD context).
- CICFlowmeter/Kitsune (statistical baselines): <0.50 mean F1 (DD context).
The generalization gap (ΔF1) between cross-validation (CV) and cross-dataset (DD) is only 0.19 for GeMID, versus up to 0.46 for Kitsune (statistical). Thus, statistical methods lose more than double the predictive power when transferred across networks compared to packet-based approaches.
Large macro-F1 is consistently retained for the majority of tested devices; residual error is explained by structural device similarity within product families (e.g., Amazon Echo variants) or by severe data imbalance.
Visualization of Methodological Impact
The domain shift impact is further underscored with confusion matrices reflecting inter-site transfers on the MonIoTr dataset:
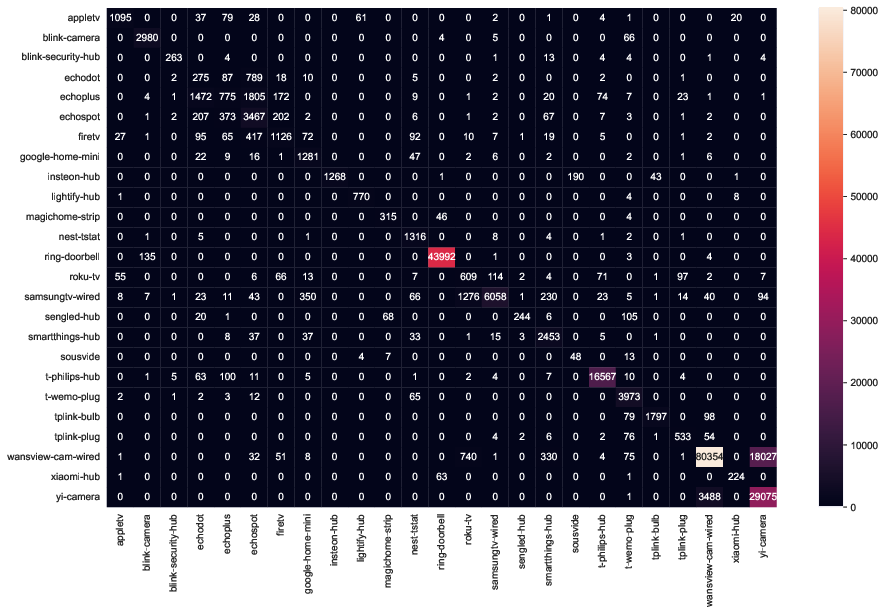
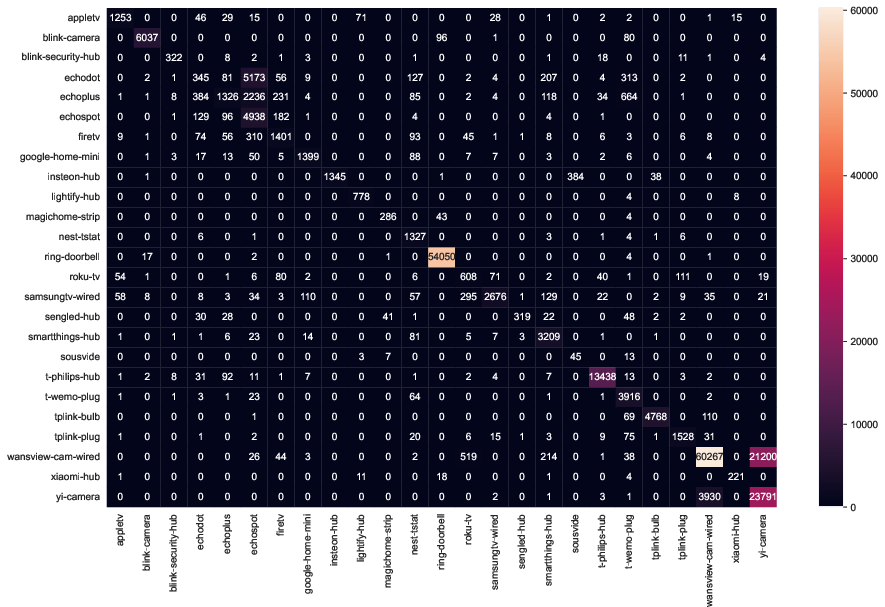
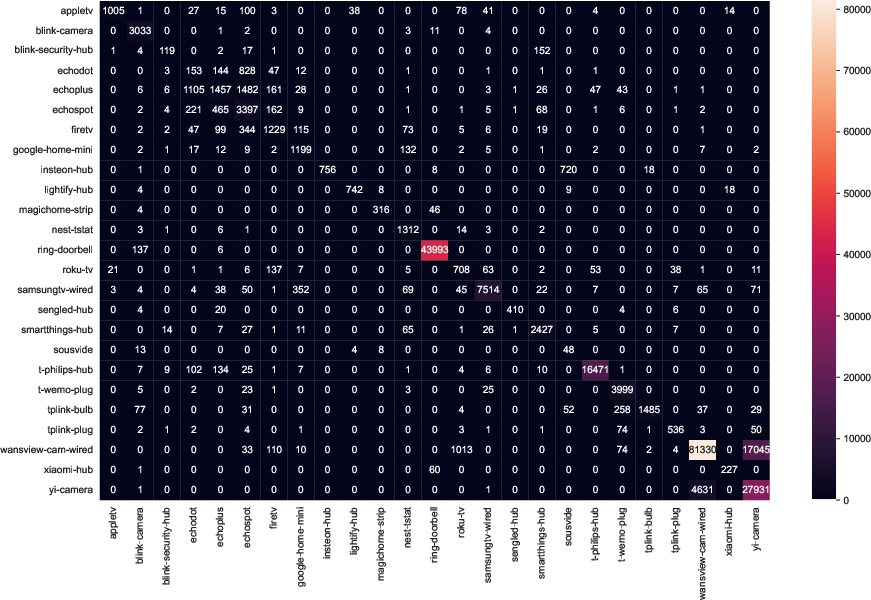
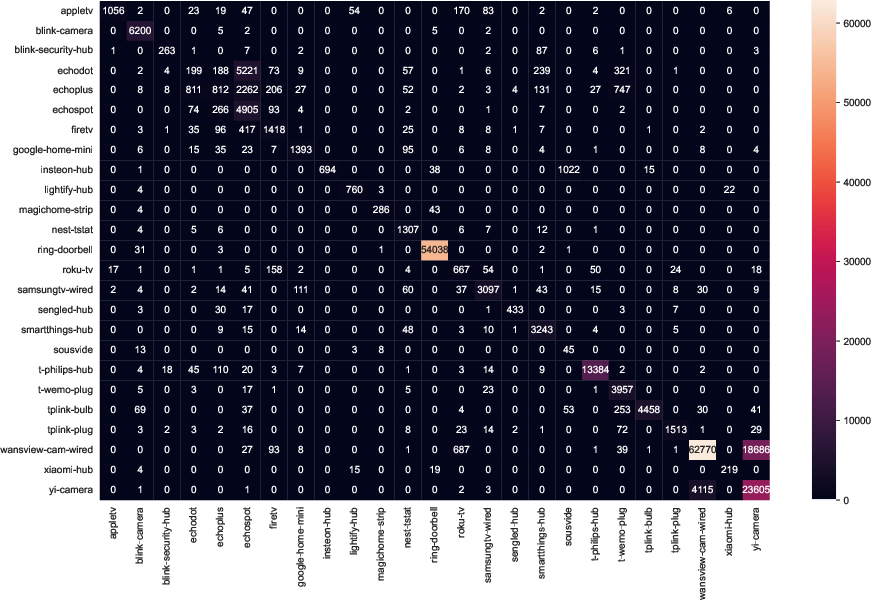
Figure 7: Confusion matrices for MonIoTr (UK-to-USA), exposing mainly within-family misclassifications and demonstrating the top-line generalizability of the approach.
Practical and Theoretical Implications
Practical Dimensions
- Deployment Feasibility: The final RF with optimized packet features is suitable for router/gateway edge deployment—high-speed inference, compact feature set, and minimal privacy risk.
- Lifecycle Management: Binary, one-vs-all submodels enable device addition/removal without multi-class retraining. Model distribution via SDN-compatible repositories is posited.
- Robustness: Because training leverages only header features, the models are largely resilient to payload encryption trends, but dependency on cleartext headers may limit future efficacy as encrypted protocols (such as QUIC) proliferate.
Theoretical/Methodological Insights
- Overturning Conventional DI Practice: The demonstration that flow/window statistics are not only suboptimal but actively harmful for generalizability is a strong claim, fundamentally challenging the basis of a large body of DI research.
- Rigorous Feature Selection: The methodology—cross-dataset validation, explicit avoidance of environment leakage, and genetic search with external feedback—should be considered best practice for any ML application intended to generalize across real-world environments.
Future Prospects
- Larger, More Heterogeneous Datasets: Robustness to wider device/function classes and future protocol shifts (e.g., encrypted transport headers) remains an open challenge.
- Incorporation of Malicious/Anomalous Data: Current and prior art focus exclusively on benign contexts; evaluation on compromised device traffic is essential for operational relevance.
- Non-IP Protocol Generalization: Extension to ZigBee/Z-Wave remains unexplored and critical for broader IoT security applications.
Conclusion
GeMID substantiates, with compelling quantitative and structural evidence, that packet header-based features are uniquely suited to constructing generalizable IoT device identification models. The paper decisively demonstrates that cross-validation—ubiquitous in the literature—substantially overstates real-world DI efficacy, and that feature selection must be driven by robust, out-of-domain validation. The generalized, attacker-resilient, and deployable nature of the GeMID pipeline advances the state of practice for ML-based IoT security, calling into question any device identification study that lacks cross-environment experimental rigor and inviting the re-examination of prior statistics-based approaches.
The resultant insights are directly relevant to practitioners seeking scalable, trustworthy DI systems for real-world, heterogeneous, and adversarial IoT deployments, and to researchers designing next-generation ML pipelines under stringent environmental shift conditions.