- The paper establishes a comprehensive framework for deploying LLM-as-a-Judge systems by detailing robust evaluation pipelines and methodologies.
- It details methodologies such as in-context learning, model selection, and post-processing to ensure scalable, consistent, and accurate evaluations.
- The study highlights challenges like bias, reliability, and robustness, and discusses strategies for mitigating these issues in practical applications.
A Survey on LLM-as-a-Judge
Introduction
The paper "A Survey on LLM-as-a-Judge" (2411.15594) provides an exhaustive analysis of the emerging paradigm of using LLMs as evaluators, a concept termed "LLM-as-a-Judge". This concept leverages the advanced capabilities of LLMs in decision-making and evaluation tasks across various domains, presenting a scalable and consistent alternative to traditional human evaluations.
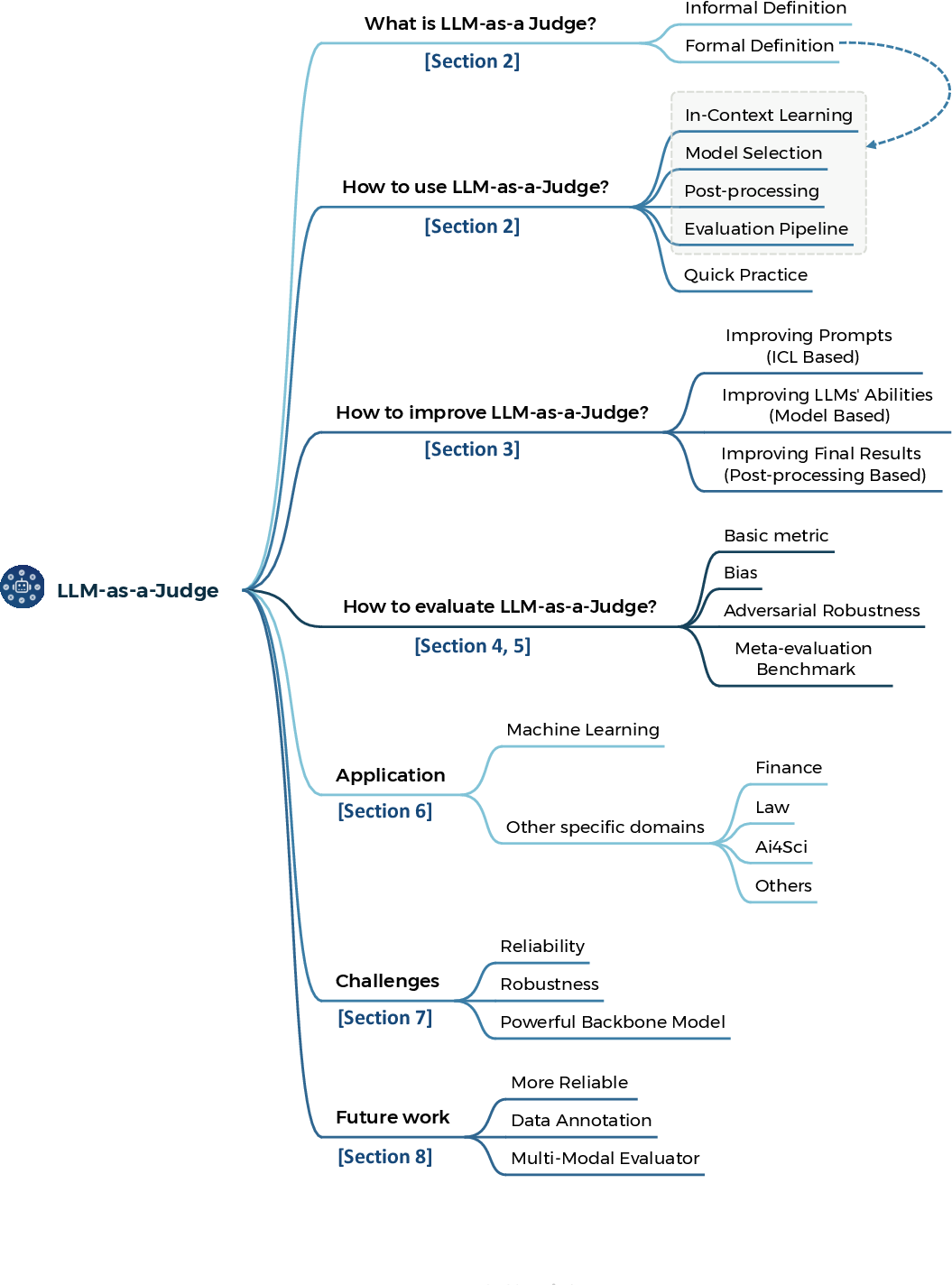
Figure 1: Paper Structure.
The paper systematically reviews strategies for constructing reliable LLM-as-a-Judge systems and proposes methodologies for their evaluation. By addressing key challenges such as consistency, bias, and adaptability, the authors aim to establish a foundational framework for deploying LLM-as-a-Judge in practical applications.
Evaluation Pipelines
The core of LLM-as-a-Judge lies in its evaluation pipelines, which transform the generic capabilities of LLMs into task-specific evaluative tools. The evaluation pipeline consists of several critical stages: In-Context Learning, Model Selection, Post-Processing, and overall Evaluation Framework.
In-Context Learning
LLMs harness their in-context learning abilities to understand and perform evaluation tasks based on provided examples or instructions. This process involves designing evaluation prompts that guide the LLM to provide accurate assessments. Strategies include prompt decomposition, few-shot learning, and criteria refinement to ensure the LLM garners a comprehensive understanding of evaluation tasks.
Model Selection
Choosing the right model is crucial for LLM-as-a-Judge. The paper emphasizes the importance of selecting models with strong reasoning and instruction-following abilities. It explores the impact of general versus fine-tuned LLMs and highlights the significance of selecting models that can effectively handle domain-specific nuances.
Post-Processing
Post-processing techniques refine the outputs generated by LLMs, ensuring they align with expected evaluation formats. Techniques include extracting specific tokens or phrases, normalizing output probabilities, and employing methods like score smoothing to enhance evaluation reliability.
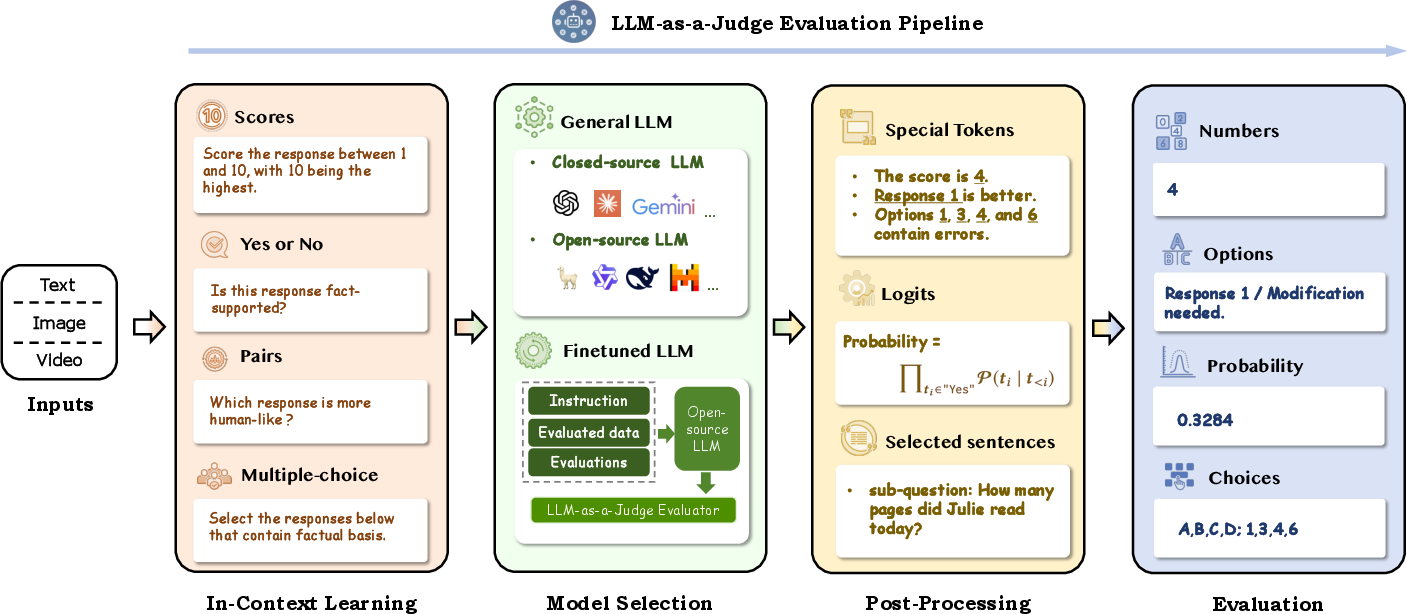
Figure 2: LLM-as-a-Judge Evaluation Pipelines.
Evaluation Framework
The framework for assessing LLM-as-a-Judge systems involves integrating multiple evaluation results and directly optimizing the output. This includes orchestrating evaluations from multiple rounds or diverse LLMs to mitigate bias and variability in assessments. Direct output optimization is applied to ensure evaluation results are comprehensive and accurate.
Challenges in Implementation
The paper identifies several challenges faced when implementing LLM-as-a-Judge, including biases, reliability, and robustness.
Bias
LLMs can inherently possess biases such as position and length biases, self-enhancement tendencies, and sentiment biases. The paper underscores the importance of systematically detecting and mitigating these biases to ensure evaluations are objective and fair across diverse scenarios.
Reliability
Reliability is another cornerstone concern, given LLMs are probabilistic models. Their overconfidence and the complexity in standardizing evaluations necessitate thoughtful strategies like cross-evaluator consensus and iterative refinement.
Robustness
Robustness against adversarial perturbations and misleading inputs is critical. The evaluation methods and the LLMs themselves must be resilient against manipulative tactics that seek to exploit model vulnerabilities.
Applications
The practical application of LLM-as-a-Judge spans various domains, including finance, law, science, and educational evaluations. In these areas, LLMs facilitate the assessment of complex, qualitative information, providing a scalable solution to traditional, labor-intensive methods.
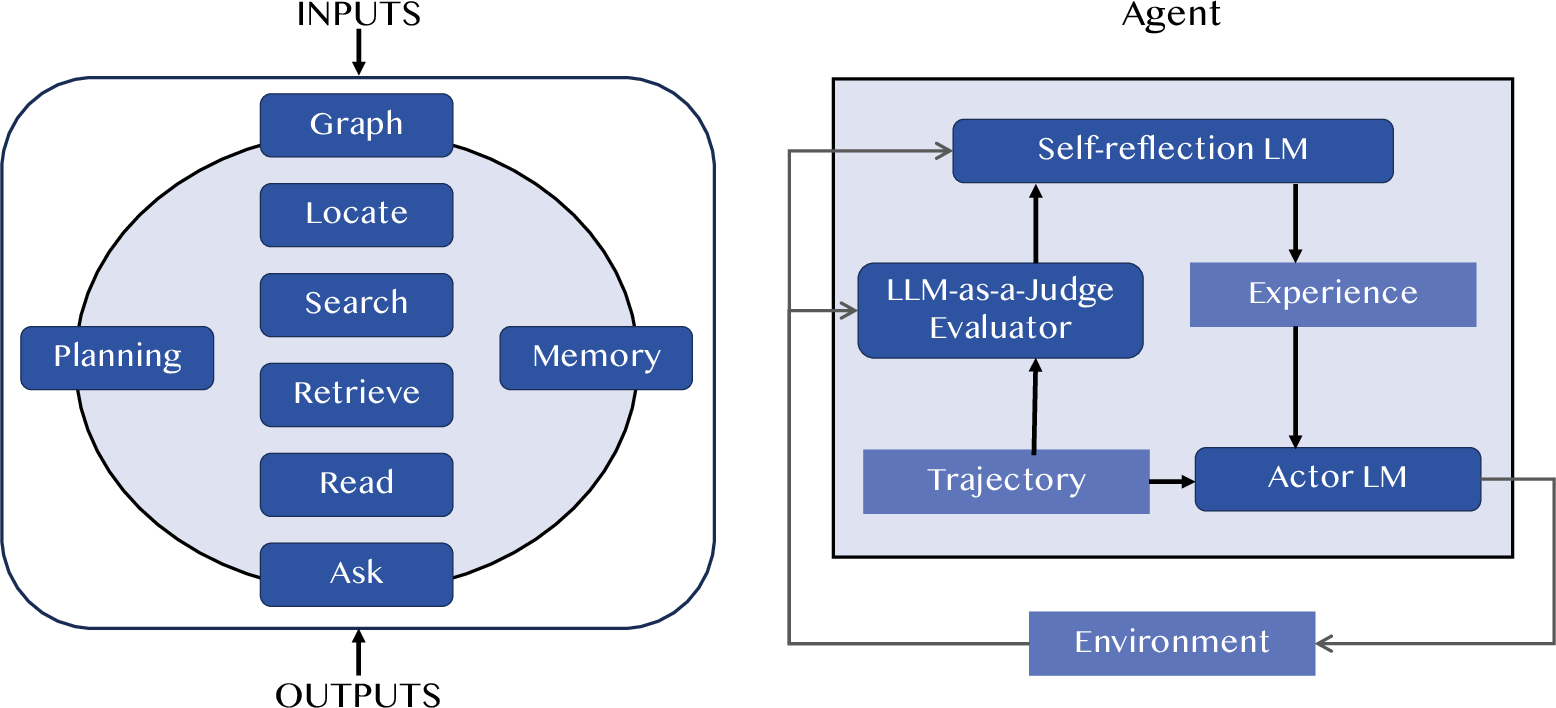
Figure 3: LLM-as-a-Judge appears in two common forms in the agent. The left diagram is Agent-as-a-Juge, designing a complete agent to serve as an evaluator. The right diagram shows using LLM-as-a-Judge in the process of an Agent.
Conclusions
The paper establishes a comprehensive groundwork for understanding and implementing LLM-as-a-Judge systems. By addressing the challenges and proposing foundational strategies and frameworks, it paves the path for future research in expanding the capabilities and reliability of LLM evaluators across various application areas. Looking forward, the paper suggests that continual advancements in LLM capabilities and methodologies will foster more robust, versatile, and trustworthy LLM-as-a-Judge systems.