- The paper introduces a reconfigurable FPGA accelerator that uses dataflow optimizations for FEM-based Navier-Stokes simulations, achieving a 7.9× speedup over optimized baselines.
- It employs a dual-kernel CPU-FPGA heterogeneous model with task-level pipelining and memory parallelization to address bottlenecks in diffusion and convection computations.
- Empirical evaluations demonstrate a 45% latency reduction and 3.64× lower power consumption compared to CPU solutions, promising efficient, large-scale CFD workflows.
Dataflow-Optimized Reconfigurable Architecture for FEM-Based CFD Acceleration
Introduction
The paper "Dataflow Optimized Reconfigurable Acceleration for FEM-based CFD Simulations" (2411.16245) introduces a high-performance, reconfigurable hardware accelerator for Computational Fluid Dynamics (CFD) simulations targeting the Finite Element Method (FEM) discretization of the Navier-Stokes equations. The motivation stems from the escalating computational demands and memory requirements of traditional CFD methods, particularly for applications involving complex geometries and large node counts, where the adaptability and parallelism of field-programmable gate arrays (FPGAs) are leveraged to improve performance and energy efficiency over conventional CPU and GPU platforms.
CFD simulations are fundamentally defined by numerically approximating the solution to the compressible 3D Navier-Stokes PDEs, which encapsulate mass, momentum, and energy conservation laws in fluid dynamics. The FEM was selected over Finite Difference Methods due to its adaptability to unstructured meshes required for accurate resolution of nontrivial geometries. A fourth-order Runge-Kutta (RK4) method temporally advances the solution. Profiling analysis revealed that the RK4 loop, predominantly its diffusion and convection term computations, dominates the execution profile—accounting for 76.5% of the total execution time, with diffusion and convection consuming 39.2% and 21.04% respectively.
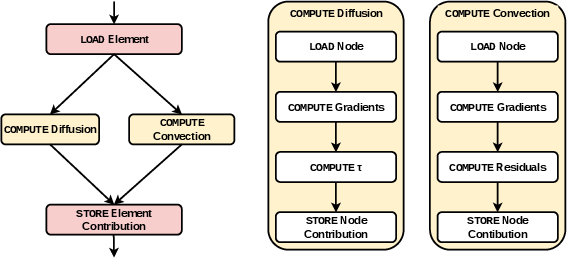
Figure 1: Dataflow graph capturing the core computational steps for FEM-based Navier-Stokes solution using RK4.
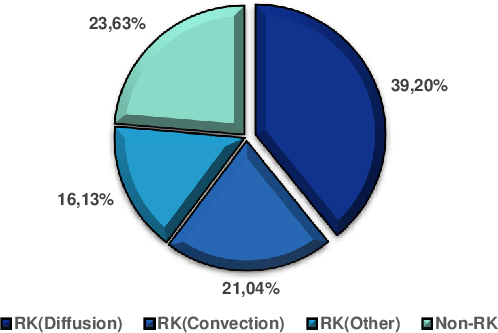
Figure 2: Average execution time breakdown, highlighting the predominance of the RK4 and associated diffusion/convection computations.
Accelerator Architecture and Dataflow Optimizations
The accelerator, implemented via High-Level Synthesis (HLS) on an AMD Alveo U200 FPGA, features a CPU-FPGA heterogeneous execution model. The FPGA fabric is partitioned into two distinct kernels, each mapped to a separate Super Logic Region (SLR): the RKL kernel orchestrates the high-intensity diffusion and convection operations (RK compute), while the RKU kernel manages per-time-step state updates. Key optimizations include a Load-Compute-Store restructuring, maximizing Task Level Pipelining (TLP) efficiency, and memory parallelization.
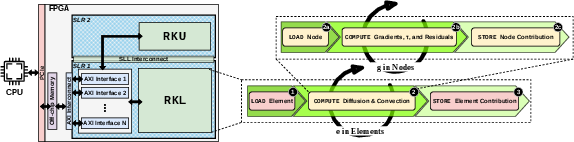
Figure 3: Architectural overview of the proposed FEM-based Navier-Stokes accelerator, illustrating SLR partitioning and core data paths.
Coarse-grained TLP decomposes computation into data movement and kernel execution, pipelined across the accelerator. Aggressive mapping of memory arrays onto independent AXI interfaces, and the decoupling of read/write channels for frequently updated arrays, alleviates memory bottlenecks and enables deep pipeline operation. Microarchitectural optimization is applied selectively to latency-critical inner loops and BRAM/URAM-resident matrix accesses, leveraging loop pipelining, targeted unrolling, and array partitioning without violating resource constraints or inducing timing closure failures.
Empirical Evaluation
Performance scalability is analyzed as a function of mesh node count, with execution time scaling linearly. The proposed accelerator achieves a 7.9× speedup over the best Vitis-HLS optimized baseline, attributable to architectural restructuring, TLP, and memory optimizations—where the baseline is limited by congestion-induced frequency ceilings and less effective resource utilization.
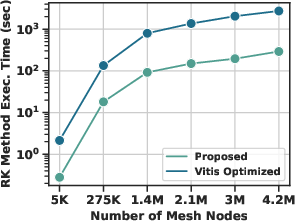
Figure 4: Execution time scaling across different mesh node counts for both optimized and baseline FPGA implementations.
The architecture incurs only a moderate increase in FPGA resource usage compared to the Vitis baseline (1.5× in FF%/LUT%, 1.9× in BRAM/DSP%, and 16.8× in URAM%), which is justified by the substantial throughput gain. When benchmarked against a high-end Intel Xeon Silver 4210 CPU, the accelerator provides a 45% latency reduction and 3.64× lower average power consumption, an especially significant result for large-scale, real-time, or energy-constrained CFD applications.
Implications and Future Directions
The reported results demonstrate that methodical dataflow-oriented and resource-aware design for FPGA-based acceleration of FEM-based Navier-Stokes solvers can dramatically outpace both software implementations and generic HLS-optimized hardware kernels. The separation of tasks onto dedicated SLRs, minimization of initiation intervals via targeted pipelining/unrolling, and explicit management of off-chip bandwidth constitute concrete, replicable design strategies for future scientific computing accelerators.
Practically, this architecture provides a blueprint for enabling large-scale, high-fidelity CFD studies within practical time and energy budgets for domains such as aerodynamic shape optimization, urban wind modeling, or reactive flows. The flexibility offered by FPGA reconfiguration is particularly salient for workflows demanding frequent variation in boundary conditions or mesh topology.
Theoretically, the correspondence between algorithmic hotspots and architectural partitioning presents a scalable template for multi-kernel acceleration strategies in broader PDE-constrained simulation domains. Further advances could incorporate mixed-precision arithmetic, adaptive mesh refinement on-the-fly, or hardware/software co-design for multiscale multiphysics coupling.
Conclusion
This work substantiates the efficacy of dataflow-optimized, reconfigurable FPGA architectures for FEM-based Navier-Stokes solvers, offering substantial improvements in speed and energy over both CPU and state-of-the-art HLS-optimized baselines. These advances enable complex, industrial-grade CFD workloads to scale efficiently and flexibly, with clear implications for next-generation high-performance scientific computing architectures.