- The paper introduces TNT Pruning, a method that employs continuous additive noise during training to determine token relevance.
- The paper casts token pruning as an optimization problem using the Information Bottleneck framework to retain only the most informative tokens.
- The paper demonstrates superior efficiency on ImageNet-1K by preserving critical information while reducing computational overhead with strategic token removal.
Training Noise Token Pruning: An Exploration of Efficient Computation via Token Relevance Estimation
Introduction
The paper discusses "Training Noise Token (TNT) Pruning", a method designed to enhance the efficiency of vision transformers by pruning tokens—a critical element in reducing computational load without significantly impacting model accuracy. This approach leverages continuous additive noise during training, relaxing the conventional discrete token dropping mechanism. This concept is rooted in Information Theory, particularly the Information Bottleneck framework, facilitating a natural progression from a primarily discrete problem to a continuous optimization problem.
Methodology
Token Pruning as Bottleneck Optimization
The token pruning process is cast as an optimization problem where the goal is to minimize the model's loss function subject to constraints on the number of tokens retained. This problem is thoughtfully aligned with the Information Bottleneck framework, asserting that the model should retain only the most informative subset of tokens to maximize accuracy, effectively emulating a compression task where the trade-off between representation and cost is managed.
The approach introduces a novel module, the Noise Allocator, integrated into transformer blocks to predict relevance scores αi for each token. During training, Gaussian noise is conditionally added to tokens based on their relevance. In practical deployment, less relevant tokens are pruned based on these learned importance estimates, balancing accuracy and computational efficiency.
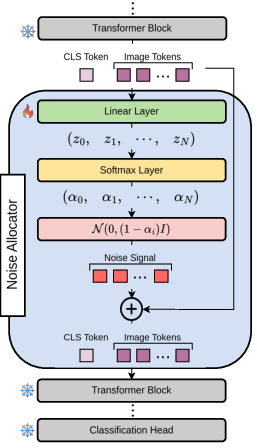
Figure 1: Noise Allocator block architecture: noise signal terms α are computed, determining the level of Gaussian noise added to tokens during training, with tokens subsequently pruned based on relevance.
Approximate Solution and Implementation
The method exploits the simplicity of approximating token relevance without computing high-order interactions. This approximation, surprisingly effective, minimizes computational overhead while maintaining high precision during testing. Each token's relevance is modeled using a linear layer followed by a Softmax function, ensuring a constrained noise allocation—a key factor in pruning decisions.
The TNT model requires insignificant parameter overhead compared to standard architectures (O(D) space complexity), making it deployable in resource-constrained environments. Importantly, redundant tokens sharing excessive mutual information with others are further pruned using similarity-based methods, enhancing the method's effectiveness.
Experimental Results
The empirical evaluation encompasses multiple experiments using the ImageNet-1K dataset, demonstrating the efficacy of TNT compared to several baselines. The results reveal TNT's superiority in achieving a favorable accuracy-computation trade-off, especially in low-token retention scenarios—where preserving critical information is paramount.
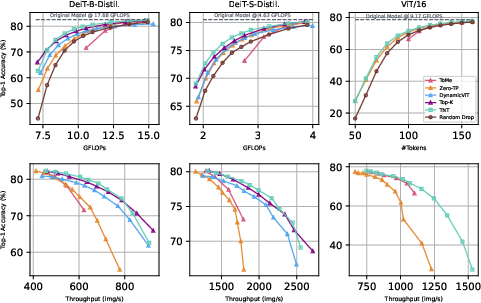
Figure 2: Single Layer Pruning results show superior Top-1 Accuracy metrics across various architectures, primarily in low-token settings, compared to established pruning techniques.
Notably, the method outperforms Top-K and Zero-TP in most configurations, maintaining competitive throughput and GFLOPs. Visual inspections (Figures 3 and 8) further corroborate TNT's ability to retain essential tokens, with pruning maps indicating strategic removal of redundant data while preserving critical semantic content.

Figure 3: Visualization of Token Pruning maps throughout different transformer layers, highlighting the consistency and relevance of kept tokens after pruning.
Limitations and Future Work
The TNT approach does exhibit some limitations. The ignorance of synergistic token information and non-removal of redundant tokens during training are notable shortcomings. Future research can explore advanced methods to accurately capture and incorporate such interactions, potentially leveraging deep mutual information estimation techniques. Additionally, tailoring pruning strategies to specific deployment hardware constraints could yield further efficiency gains.
Conclusion
The introduction of TNT Pruning marks a significant step towards more efficient vision transformer designs, reconciling high computational demands with the requirement for accurate and timely output. Through continuous optimization mechanisms and informed pruning strategies, TNT provides a viable alternative for real-world applications where resources are limited but performance cannot be compromised. The promising results invite future exploration into more nuanced token relevance models and potential real-time implementations.