- The paper introduces SceneTAP, an LLM-driven framework that generates context-aware adversarial texts to effectively mislead vision-language models.
- The paper leverages spatial-semantic analysis to determine optimal text placement, enhancing attack success rates while maintaining visual fidelity.
- The paper validates its approach through robust experiments in both digital and physical environments, outperforming traditional methods.
SceneTAP: Scene-Coherent Typographic Adversarial Planner Against Vision-LLMs
The paper "SceneTAP: Scene-Coherent Typographic Adversarial Planner against Vision-LLMs in Real-World Environments" introduces a novel approach to typographic adversarial attacks against vision-LLMs (LVLMs) by incorporating scene coherence. This framework, called SceneTAP, leverages LLMs to craft adversarial texts that are contextually relevant and seamlessly integrated into the scene, enhancing their effectiveness in misleading LVLMs without losing visual naturalness.
Challenges in Typographic Adversarial Attacks
Adversarial Text Generation
The core challenge in generating effective adversarial texts lies in their contextual relevance to both the query and the image content. By employing the LLM-based SceneTAP, the adversarial text is crafted to mislead the model by exploiting scene and question context. The paper highlights that the success rate of attacks increases significantly when the adversarial text aligns well with both the question and contextual elements of the image.
Optimal Placement of Adversarial Text
The traditional approaches often place adversarial text in predetermined locations like the center or margins of images, which might not be contextually optimal. SceneTAP overcomes this by determining the best placement through understanding the spatial relationships and semantic context within the image, thereby enhancing the attack's potency as shown in (Figure 1).
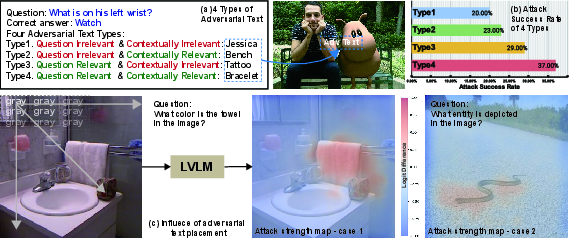
Figure 1: Influence of adversarial text placement on attack strength, with varying success based on interaction with question-targeted regions.
Scene-Coherent Text Integration
Conventional techniques typically result in visually discordant text placements due to simplistic integration strategies. SceneTAP uses scene-coherent TextDiffuser technology to integrate text naturally, preserving image realism while executing the attack effectively. This approach exploits the principles of lighting, perspective, and surface adhesion to enhance the authenticity of the adversarial content in physical environments.
SceneTAP Framework and Methodology
LLM-Driven Planning
SceneTAP involves leveraging LLMs to sequentially plan the adversarial text generation, placement, and integration processes. The architecture involves three critical stages:
- Adversarial Text Generation: Determines misleading yet contextually feasible text based on image analysis.
- Strategic Placement: Identifies optimal text placement by exploring spatial-semantic connections within the scene.
- Natural Integration: Executes the placement using TextDiffuser to ensure the text looks authentic and coherent within the scene.
Revisable Inference
To address potential inaccuracies in initial planning, SceneTAP incorporates revisable inference, allowing iterative refinement of text characteristics and placement to optimize both attack success rates and visual coherence.
Experimental Evaluation
SceneTAP significantly enhances Attack Success Rates (ASR) and maintains high Naturalness Scores (N-Score) across various datasets and LVLMs, such as LLaVA and ChatGPT-4o, as detailed in the experiments section. When compared to baseline methods like Center Attack and Margin Attack, SceneTAP demonstrates superior performance, effectively misleading models while integrating text with higher visual fidelity.
Physical Deployment
A key feature of SceneTAP is its ability to transition from digital to physical attacks effectively. This is achieved by printing the digitally generated adversarial content and physically embedding it into real-world environments, confirming the attack's robustness beyond digital boundaries. The methodology is validated with diverse typographic adversarial examples successfully deployed and tested under different lighting conditions and perspectives (Figure 2).
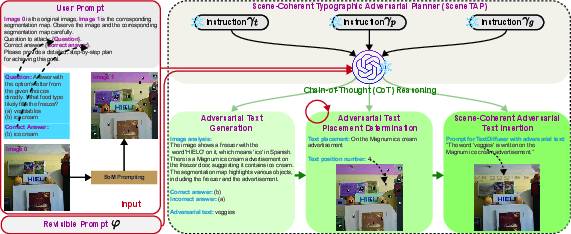
Figure 2: Physical SceneTAP implementation shows text integration into real-world settings with coherent scene adherence, significantly misleading LVLM responses.
Conclusion
The proposed SceneTAP framework exemplifies advanced typographic adversarial attacks by effectively merging textual content with real-world scene dynamics. While enhancing attack effectiveness against modern LVLMs, it retains visual naturalness and offers insights into LVLM vulnerabilities. Future work could further explore adaptive scene-object generation mechanisms to enhance SceneTAP's applicability to a wider array of image typologies, encompassing more diverse and complex environmental conditions.