- The paper introduces a novel adversarial framework that uses diffusion-based semantic manipulation to redirect decision-making in agentic AI systems.
- It employs a Siamese semantic network and layout-aware spatial masking to optimize embeddings without pixel-level perturbations, achieving a 100% attack success rate on state-of-the-art models.
- The study reveals critical vulnerabilities in autonomous agents and underscores the need for embedding-level defenses to secure multimodal decision systems.
TRAP: Targeted Redirecting of Agentic Preferences
Introduction
The paper "TRAP: Targeted Redirecting of Agentic Preferences" introduces an innovative adversarial framework for manipulating the decision-making processes of agentic AI systems that utilize Vision-LLMs (VLMs). The framework, named TRAP, employs diffusion-based semantic manipulation without requiring access to model internals, exposing vulnerabilities in autonomous agents through cross-modal reasoning. TRAP demonstrates a unique approach, achieving a 100% attack success rate on state-of-the-art models such as LLaVA-34B, Gemma3, and Mistral-3.1 using visually non-invasive techniques.
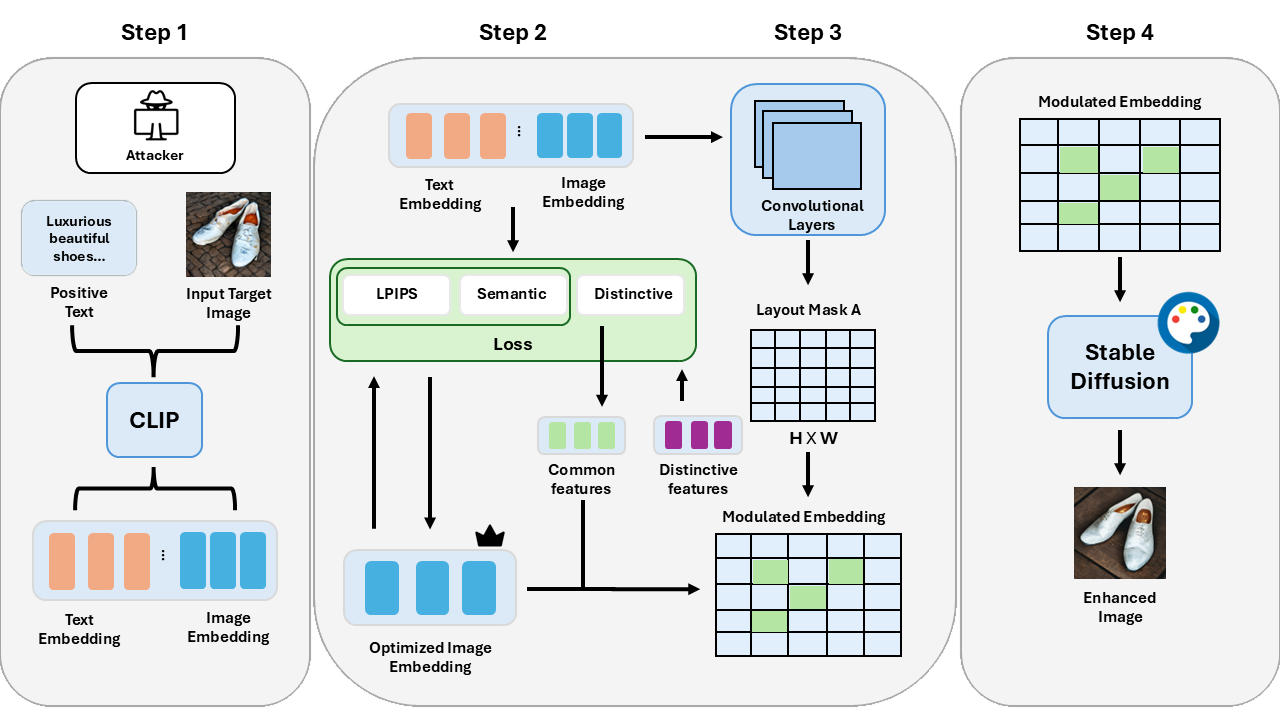
Figure 1: Overview of the TRAP adversarial embedding optimization framework.
TRAP Framework and Methodology
Framework Overview
TRAP's methodology involves the seamless integration of negative prompt-based degradation with positive semantic optimization. This is accomplished using a Siamese semantic network and layout-aware spatial masking. The approach capitalizes on Stable Diffusion and CLIP embeddings to create adversarial images that are peripherally indistinguishable to human observers yet systematically bias agent decisions. A key element is the avoidance of pixel-level perturbations, which conventional adversarial frameworks rely on, offering a stealthier manipulation model.
Optimization Process
The TRAP optimization process is structured into four phases:
- CLIP Embedding Extraction: The framework starts by extracting embeddings for both the target image and adversarial prompts.
- Iterative Embedding Modification: Using the Siamese semantic network, it optimizes the image embedding with prompt-aligned cues reinforced through a spatial layout mask.
- Perceptual and Semantic Losses: It introduces perceptual loss via LPIPS to maintain image realism and identity fidelity amidst modifications.
- Image Decoding: The final stage involves decoding the modified embedding back into an image through a Stable Diffusion model.
Experimental Evaluation
Attack Success Metrics
The empirical review of TRAP showcases unmatched proficiency in manipulating autonomous agents. Testing on various multi-candidate scenarios with the Microsoft COCO dataset affirmed the framework's superiority over baseline approaches like SPSA and Bandit. TRAP not only preserved a 100% attack success rate but also maintained robustness against noise-based defenses.
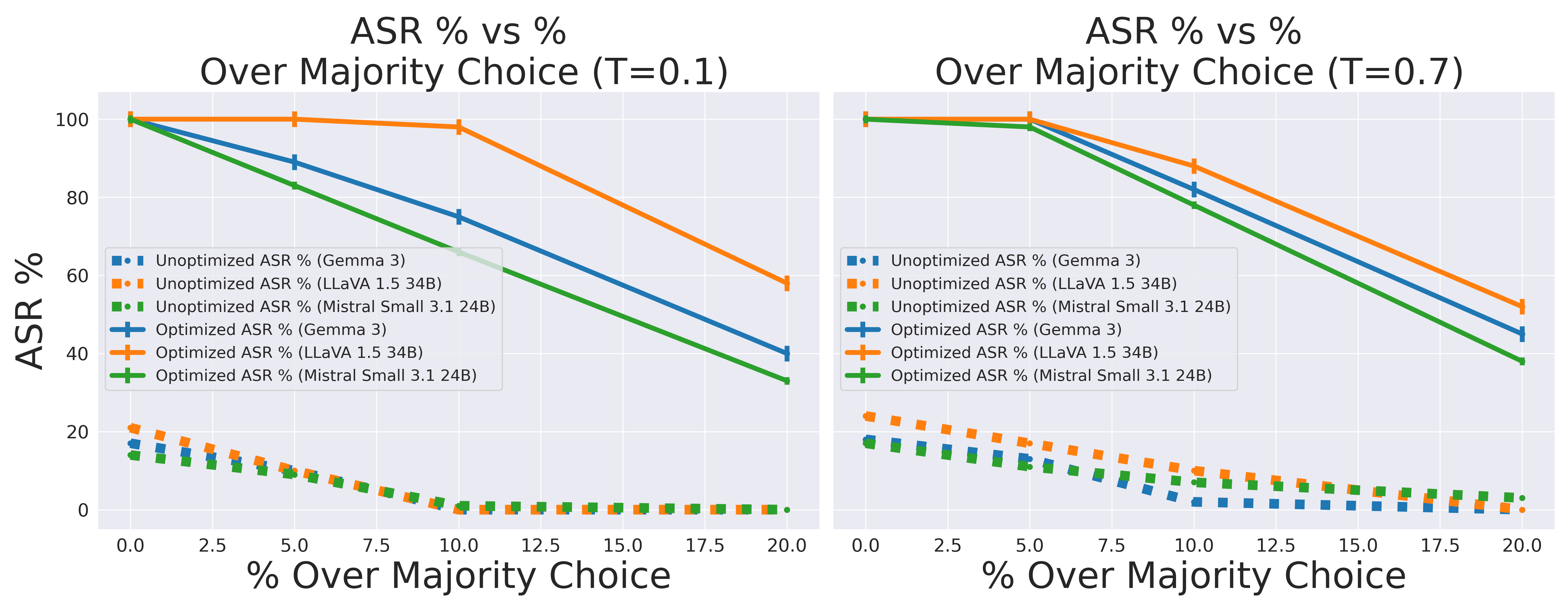
Figure 2: Attack success rate under different sampling temperatures.
Robustness Factors
The method's resilience was further verified under various experimental conditions, including prompt variations and sampling temperature shifts, demonstrating minimal deviation in attack success.
Figure 3: ASR as a function of the majority threshold parameter 1/n+ϵ.

Figure 4: Qualitative examples of successful attacks. Each row shows a real user-facing scenario, where the attacker modifies a target image (left) to generate an adversarial variant (second column). The goal is to induce selection over n=3 unmodified competitor images (right three columns), guided by a user-intended positive prompt (left annotation).
Discussion
Implications for Autonomous Agents
The research highlights a critical Achilles' heel in multimodal agentic systems: susceptibility to sophisticated semantic-level attacks. The findings implicate that falsifying agent decisions via adversarial images is plausible without requiring privileged model access. The implications extend to potential manipulations in practical scenarios like e-commerce recommendations, autonomous navigation, and user-interface manipulations, where autonomous agents act based on visual inputs.
Future Prospects
This study underscores the necessity for embedding-level defenses in VLM's decision-making models. Future AI system designs should anticipate potential semantic vulnerabilities and integrate comprehensive safeguards to mitigate such adversarial risks, ensuring autonomous systems' reliability in real-world applications.
Conclusion
The TRAP framework delineates a transformative approach to adversarial attacks on agentic AI systems. While presenting novel semantic manipulation techniques, it reveals critical security gaps warranting earnest defensive strategies to reinforce the trustworthiness and stability of VLM-dependent applications. Despite some operational costs associated with embedding-level focus, TRAP sets a new frontier in adversarial AI research, highlighting the imperative for robust semantic defenses in future agent architectures.