VidHalluc: Evaluating Temporal Hallucinations in Multimodal Large Language Models for Video Understanding
Abstract: Multimodal LLMs (MLLMs) have recently shown significant advancements in video understanding, excelling in content reasoning and instruction-following tasks. However, hallucination, where models generate inaccurate or misleading content, remains underexplored in the video domain. Building on the observation that MLLM visual encoders often fail to distinguish visually different yet semantically similar video pairs, we introduce VidHalluc, the largest benchmark designed to examine hallucinations in MLLMs for video understanding. It consists of 5,002 videos, paired to highlight cases prone to hallucinations. VidHalluc assesses hallucinations across three critical dimensions: (1) action, (2) temporal sequence, and (3) scene transition. Comprehensive testing shows that most MLLMs are vulnerable to hallucinations across these dimensions. Furthermore, we propose DINO-HEAL, a training-free method that reduces hallucinations by incorporating spatial saliency from DINOv2 to reweight visual features during inference. Our results show that DINO-HEAL consistently improves performance on VidHalluc, achieving an average improvement of 3.02% in mitigating hallucinations across all tasks. Both the VidHalluc benchmark and DINO-HEAL code are available at https://people-robots.github.io/vidhalluc.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper looks at a common problem in AI that watches videos: “hallucinations.” That’s when an AI confidently says something that isn’t true about what it saw. The authors build a big test set (called VidHalluc) to check how often video AIs make three kinds of mistakes:
- Action mistakes: saying the wrong thing is happening.
- Order mistakes: getting the sequence of events wrong.
- Scene-change mistakes: missing or misreporting when the place changes.
They also introduce a simple add-on (called DINO-HEAL) that helps these AIs focus on the most important parts of each video frame so they hallucinate less—without retraining the whole model.
What questions were the researchers asking?
- Can we create a large, reliable test to catch when video AIs “make stuff up,” especially about actions, timing, and scene changes?
- How well do today’s top video-LLMs handle these tricky cases?
- Is there a quick, training-free way to make these models less likely to hallucinate?
How did they do it?
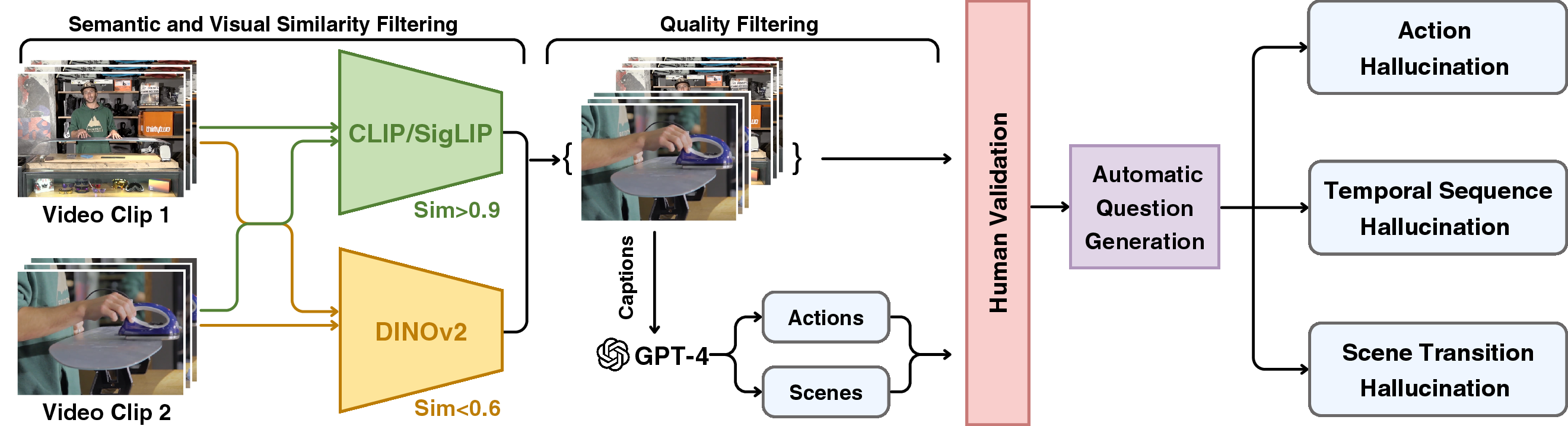
Building the VidHalluc benchmark
The team created VidHalluc, the largest test set of its kind:
- Size: 5,002 videos and 9,295 questions.
- Focus: Three types of hallucinations—actions, event order, and scene transitions.
To make the test both challenging and fair, they paired videos that mean similar things but look different. Think of two videos both about “making tea,” but one shows boiling water first and the other starts with putting tea leaves in a cup. These “same idea, different looks” pairs are good at tricking models.
Here’s how they built it (in everyday terms):
- Two “checkers” picked video pairs:
- Meaning checker: finds videos that share a similar overall idea (like CLIP/SigLIP models do).
- Looks checker: finds videos that visually look different (like DINOv2 does).
- Automatic helper: GPT-4 read the original video captions to pull out actions and scenes.
- Human review: People double-checked to make sure the actions and scenes really matched or differed as expected.
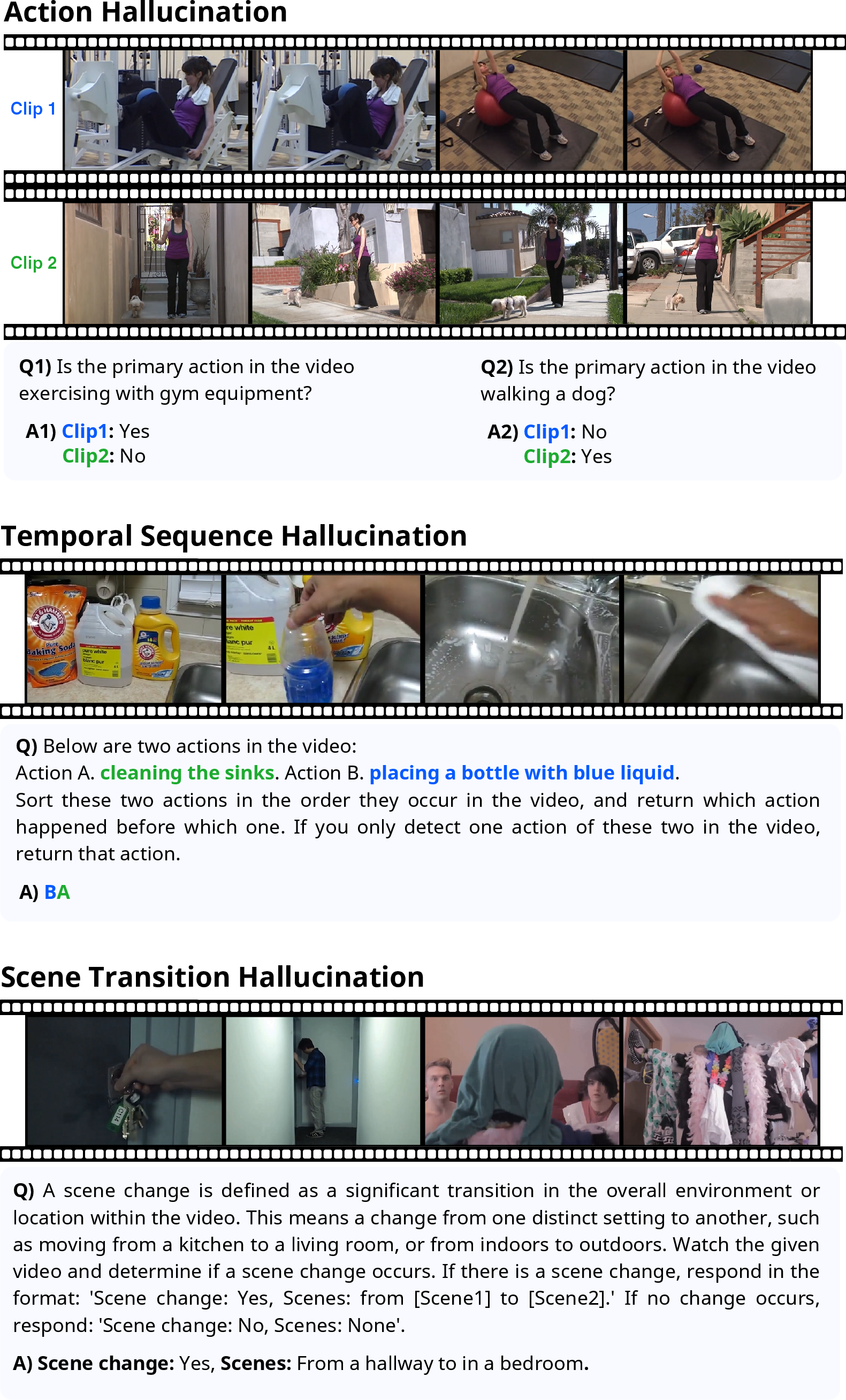
- Question types:
- Action hallucination: yes/no questions and multiple-choice (“What is the main action?”).
- Order hallucination: sorting questions to get the order of events right.
- Scene-change hallucination: “Did a scene change happen?” and “From what to what?”
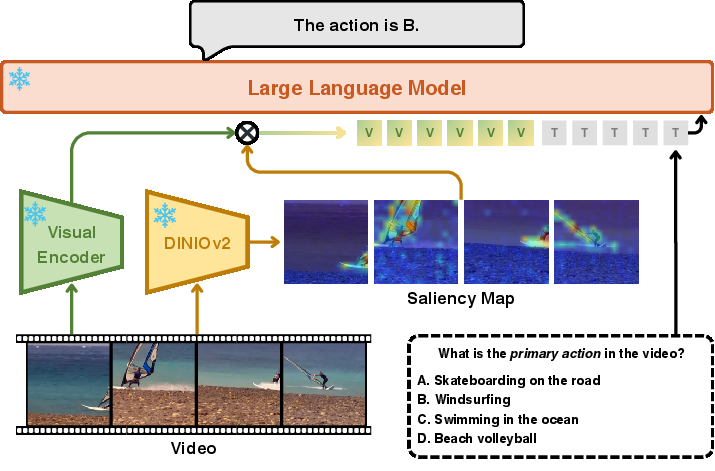
What is DINO-HEAL, and how does it help?
DINO-HEAL is like giving the AI a highlighter for each frame:
- It uses “saliency maps” (heatmaps of what’s important) from a vision model called DINOv2.
- These maps reweight the video features so the model pays more attention to key regions (like hands, tools, or moving objects) and less to unimportant background.
- It’s training-free: you don’t have to retrain the whole model—just apply this at test time.
- It works with many common video encoders (like CLIP and SigLIP).
Why this helps: Many video AIs rely on visual encoders trained to match images with text. That can make them focus on general context (“kitchen,” “stadium”) instead of the tiny details that prove exactly what action is happening or when it happens. DINO-HEAL nudges the focus back toward the most important bits.
What did they find, and why is it important?
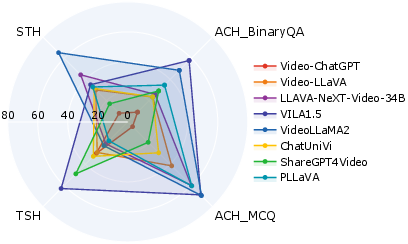
- Most models hallucinate across all three areas, especially with action and order.
- Many did much better on multiple-choice action questions than yes/no questions. With choices, models can compare; with yes/no, they must be sure—and that’s where they slip up.
- For event order, many models fell below 50% accuracy and often collapsed separate actions into one, missing the sequence.
- For scene changes, most models struggled to reliably detect and describe transitions.
- Bigger isn’t always better. A larger model or more frames didn’t automatically mean better performance. Models with higher-resolution vision modules generally did better than those with lower resolution.
- Commercial models did best overall. GPT-4o and Gemini-1.5-Pro were stronger and closer to human performance, with GPT-4o near human levels on several tasks.
- DINO-HEAL improves results without training:
- Action questions (yes/no): around +5% improvement for some models.
- Event order: big gains (about +12% and +19% for two models tested).
- Scene-change: smaller gains, likely because the method emphasizes foreground objects (people and things) more than background shifts.
Why this matters:
- Video AIs are used in real-world tools (assistive tech, training videos, robots, safety systems). If they hallucinate about what’s happening or when, outcomes can be wrong or even unsafe.
- A large, realistic benchmark helps developers spot and fix these weaknesses.
- A simple, training-free fix like DINO-HEAL is practical for teams without massive computing resources.
What’s the bigger picture?
VidHalluc gives the community a tough, real-world test for video understanding that focuses on things videos are uniquely good at—actions over time and scene changes—not just static objects. The results show we still have work to do: models can be fooled when videos have similar meanings but different looks, and they’re especially shaky on the order of events.
DINO-HEAL shows a promising, easy-to-use way to cut down hallucinations by helping models “look” in the right places. Going forward, the authors suggest:
- Expanding to more types of hallucinations.
- Combining spatial and temporal “highlighters” to better capture both what is important and when it matters.
In short, this research gives us a clearer, more honest picture of what video AIs can and can’t do today—and a practical step toward making them more trustworthy.
Collections
Sign up for free to add this paper to one or more collections.