- The paper introduces LVMark, which robustly embeds and decodes invisible watermarks directly in the latent video diffusion model to secure model ownership.
- It employs importance-based selective weight modulation and a robust spatio-temporal decoder using 3D wavelet low-frequency fusion to maintain high perceptual quality and temporal coherence.
- Extensive evaluation shows LVMark achieves over 90% bit accuracy at 48-bit capacity under severe video distortions, outperforming traditional image-based watermarking schemes.
LVMark: A Robust Watermarking Framework for Latent Video Diffusion Models
The proliferation of high-fidelity video generative models has elevated the urgency for robust mechanisms that secure model ownership and facilitate post-hoc identification of generated content. Classical image watermarking approaches, when naively transferred to the video domain, neglect temporal coherence and are inherently brittle when subjected to adversarial post-processing and lossy video-specific distortions. The lack of video-specific watermarking schemes that operate directly on generative models rather than on individual outputs impedes the deployment of legally relevant ownership tracking and content provenance tools in multimedia pipelines.
The LVMark framework addresses these challenges by embedding robust, invisible watermarks directly into the latent decoder of video diffusion models, enabling persistent and owner-verifiable signature recovery from model outputs even after lossy or adversarial modification. The approach is agnostic with respect to underlying backbone architectures, supporting both U-Net and DiT-based latent video diffusion models.
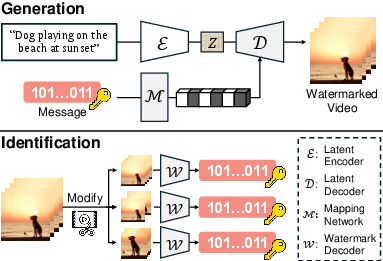
Figure 1: Schematic of watermark embedding in the latent decoder and end-to-end ownership identification from generated and distorted videos.
Methodology
LVMark combines three principal innovations: 1) importance-based selective weight modulation for efficient and quality-preserving message embedding, 2) a distortion-robust watermark decoder leveraging spatio-temporal representations in the 3D wavelet domain fused via cross-attention, and 3) tailored training objectives balancing perceptual quality and watermark recovery accuracy, including a novel weighted patch loss.
Importance-Based Selective Weight Modulation
Rather than modulating all parameters, which degrades generation quality, LVMark analyzes the importance of latent decoder layers by perturbing each and ranking by perceptual degradation (quantified via LPIPS). Watermark message embedding is then confined to the least important 50% of layers. Messages are mapped and injected as modulation factors into randomly selected latent decoder parameters using a two-layer MLP followed by normalization. This selective injection achieves high watermark capacity while maintaining visual and temporal fidelity.
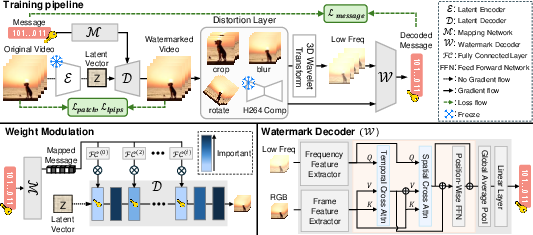
Figure 2: LVMark training pipeline illustrating selective layer modulation and the dual-domain cross-attention watermark decoder.
Robust Spatio-Temporal Watermark Decoding
The watermark decoder is optimized to retrieve embedded binary messages even after severe video-specific transformations (e.g., H.264 compression, cropping, frame drops), crucial for practical forensics. LVMark employs a cross-attentional fusion of 3D wavelet low-frequency subbands and RGB features, where temporal and spatial self-attention modules (depth=2, multi-head) enable robust and context-aware decoding. Only the lowest-frequency wavelet bands are used, maximizing resilience to compression artifacts, with cross-attention ensuring that spatial semantics guide temporal aggregation.
Distortion Simulation and Differentiable H.264 Approximation
During training, LVMark applies aggressive data augmentation mimicking both frame-wise (e.g., cropping, blurring, JPEG) and video-specific attacks (frame swapping, dropping, and H.264 compression). To enable end-to-end differentiability under H.264, a neural approximation of the codec is incorporated, aligning the optimization trajectory with non-differentiable deployment-time distortions.
Weighted Patch Loss
To mitigate local artifacts that can result from aggressive watermark embedding, LVMark introduces a softmax-weighted mean absolute error focusing optimization on patches with the highest perceptual error, successfully suppressing localized watermark-induced visual artifacts especially in transformer-based decoders (e.g., DiT/Open-Sora).
Experimental Evaluation
LVMark is evaluated using both Open-Sora (DiT) and DynamiCrafter (U-Net) architectures trained/fine-tuned on Panda-70M and tested on prompts from VidProm. Evaluation spans bit accuracy, perceptual metrics (PSNR, SSIM, LPIPS), and temporal consistency (tLP, FVD) under varying watermark capacities (32/48 bits) and distortion suites.

Figure 3: Qualitative comparison of LVMark and baseline watermarking methods: LVMark-embedded videos remain visually faithful and artifact-free, with difference maps ×10 highlighting minimal deviation from originals.
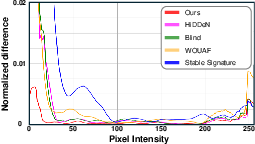
Figure 4: Normalized pixel intensity difference between original and watermarked video frames, demonstrating minimal perceptual impact for LVMark across diverse architectures.
Notably, LVMark achieves bit accuracy >90% at 48-bit capacity with imperceptible generation degradation (PSNR above 30, LPIPS near 0.1) on both DiT and U-Net backbones. Competing methods (HiDDeN, Blind, Stable Signature, WOUAF), when applied to video generative architectures, exhibit substantial trade-offs or failure modes—either losing temporal coherence or succumbing to adversarial modification.
LVMark's robustness is emphasized by bit recovery rates above 90% even after combined distortion attacks and H.264 compression, a domain where non-temporally aware watermarking completely fails.
Ablation Studies
Modulation Rate
Systematically increasing the fraction of modulated parameters improves recoverability (bit accuracy) at the expense of perceptual quality. A rate of 50% provides the best trade-off, as shown by the inflection point in the accuracy/quality curves.
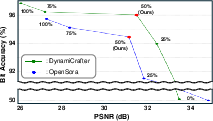
Figure 5: Relationship between weight modulation rate (0–100%) and watermark-relevant quality/robustness metrics.
Decoder Design and Frequency Domain
Switching from 2D to 3D DWT for watermark decoding yields substantial improvement in motion consistency and robustness, confirming the necessity of temporal domain modeling for video watermarks. Fusing RGB with low-frequency bands (LLL) is critical; omitting either domain severely impedes message accuracy or resilience to compression.
Weighted Patch Loss
Inclusion of the weighted patch loss consistently lowers local artifact rates and improves LPIPS while occasionally sacrificing marginal bit accuracy, a favorable overall trade-off due to its impact on visual coherence.

Figure 6: Visualization of artifact regions with and without weighted patch loss; the patch-aware approach robustly suppresses localized distortions.
Implications and Future Directions
LVMark establishes that direct watermarking of video diffusion model decoders is both practical and highly effective compared to both per-video and image-based approaches. The method's resilience to deliberate and lossy distortions makes it viable for real-world ownership tracking, synthetically auditable forensics, and regulatory compliance mechanisms in automatic video generation pipelines.
Key limitations include the significant memory overhead associated with large video diffusion models during watermark training (25GB-level consumption), and the need for further memory- or compute-efficient embedding strategies.
Theoretically, LVMark motivates further study into fingerprinting generative models at scale, the limits of robust watermark capacity under adversarial scenarios, and seamless integration with federated model auditing or copyright systems. Extension to additional generative modalities (audio, 3D, multimodal) and defense-aware model watermark obfuscation are promising directions.
Conclusion
LVMark provides a comprehensive solution to robust model-level watermarking for latent video diffusion generators. By leveraging spatio-temporal domain fusion, importance-guided weight selection, and distortion-simulating training objectives, it sets a new standard for invisible, persistent, and highly accurate watermarking in generative video settings. The empirical results validate LVMark's superiority over competing methods, particularly in robustness to real-world attack vectors and minimal perceptual impact on generation quality (2412.09122).