- The paper introduces the GVIC framework, which uses gradual vigilance to dynamically assess risks in multi-agent debates.
- It employs interval communication to reduce overhead and enhance debate efficiency while aligning models with human values.
- Experimental results show GVIC outperforms traditional methods in harmlessness, helpfulness, and fraud prevention tasks.
Gradual Vigilance and Interval Communication Framework for Enhancing Value Alignment
Introduction
The paper "Gradual Vigilance and Interval Communication: Enhancing Value Alignment in Multi-Agent Debates" (2412.13471) addresses the growing need for aligning LLMs with human values to mitigate the exposure of these models to misleading, harmful, and toxic content. It critiques traditional methods such as Reinforcement Learning from Human Feedback (RLHF) and Supervised Fine-Tuning (SFT) due to their resource-intensive nature and limited ability to surpass human performance. Multi-Agent Debate (MAD) emerges as a promising alternative, fostering resource efficiency and creativity through interactions among multiple agents.
The GVIC Framework
The authors propose the Gradual Vigilance and Interval Communication (GVIC) framework, which introduces significant innovations to improve the efficiency and effectiveness of multi-agent debates. This framework integrates Gradual Vigilance amongst agents, allowing them to assess risks with varying vigilance levels, and Interval Communication to facilitate diverse information exchanges while reducing communication overhead.
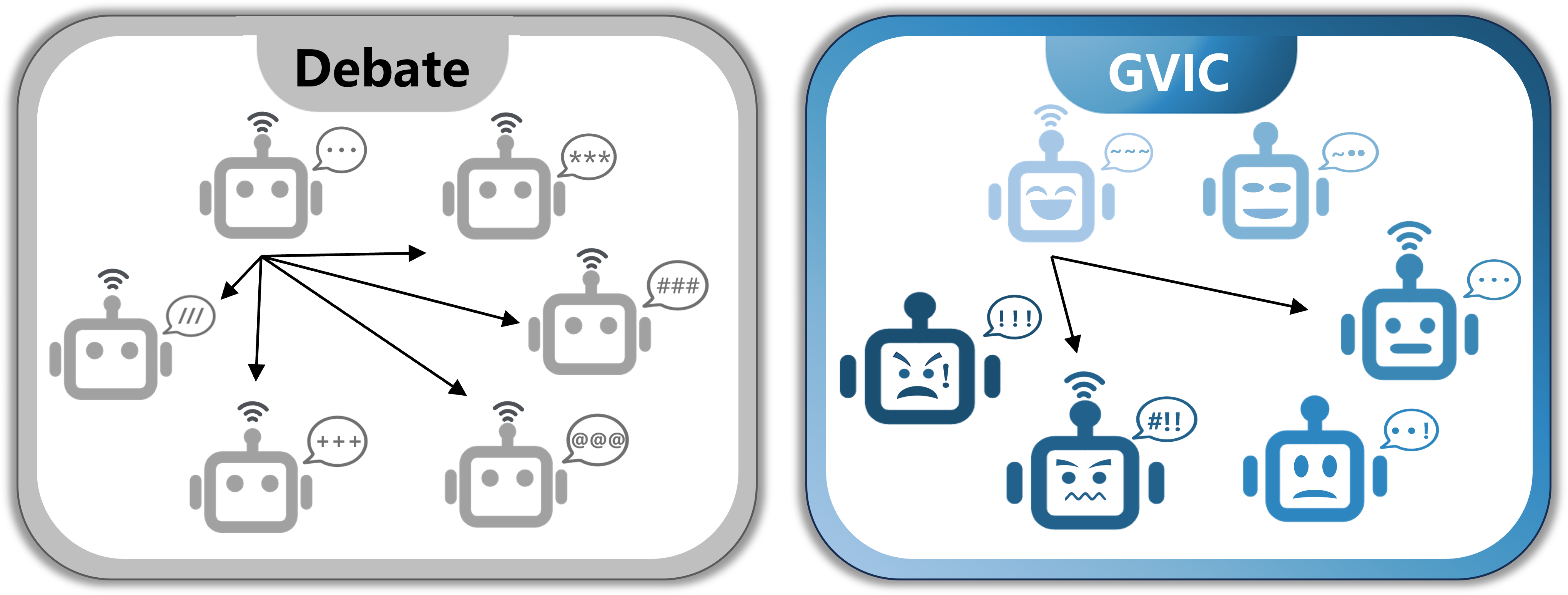
Figure 1: Comparison between the classical Debate framework and the GVIC framework.
GVIC departs from the traditional fully connected communication model, which involves high communication costs and potentially overwhelming inputs. Instead, GVIC utilizes interval communication to engage agents selectively, aiming to enhance the outcomes of the debate by ensuring minimal harm with maximum usefulness while maintaining efficient communication.
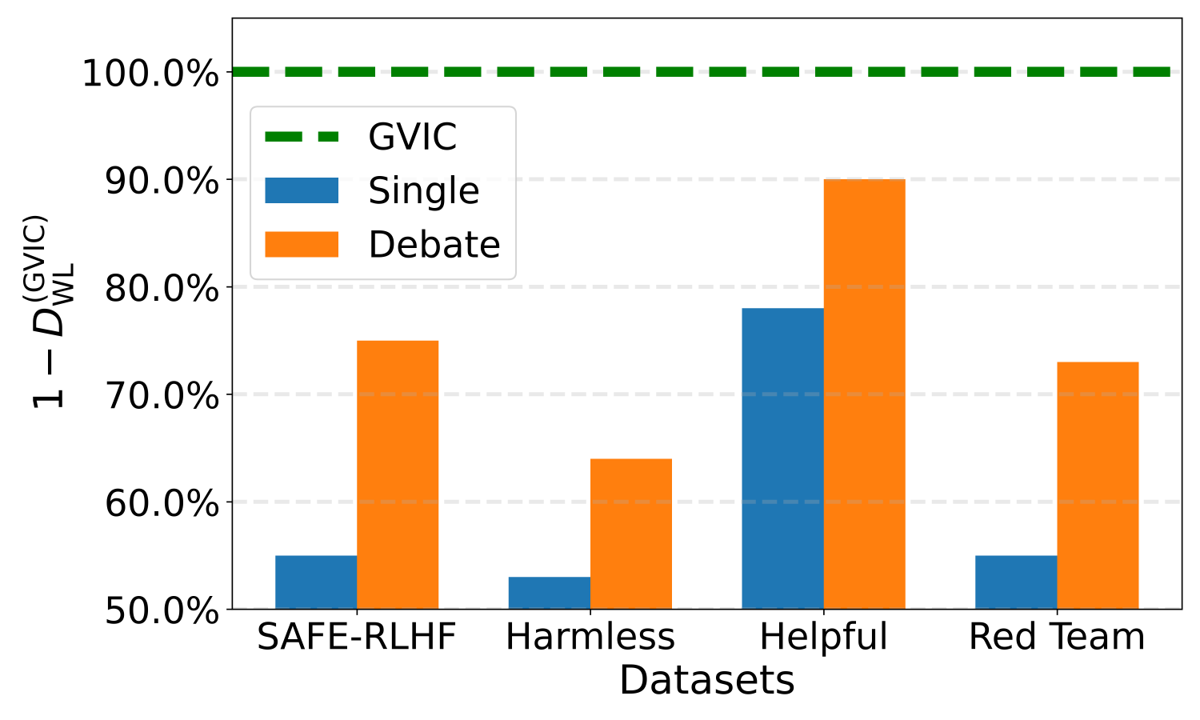
Figure 2: Performance comparison between a single agent, the classical Debate framework, and GVIC across various value alignment tasks. The datasets SAFE-RLHF and Harmless are used to evaluate model harmlessness, Helpful assesses helpfulness, and Red Team measures susceptibility to adversarial attacks.
The GVIC framework consistently outperforms both single-agent configurations and the classical Debate framework across various value alignment tasks and datasets. Notably, GVIC shows particular prowess in mitigating harmful and fraudulent content. It maintains strong adaptability across different base model sizes, further evidencing the robustness of GVIC's design.
Framework Design and Methodology
The GVIC framework is built around the concept of varying vigilance levels among agents, encouraging a dynamic spectrum of risk awareness from low to high vigilance. This setup allows agents to engage in debates that reflect a balanced view of a given question or challenge.
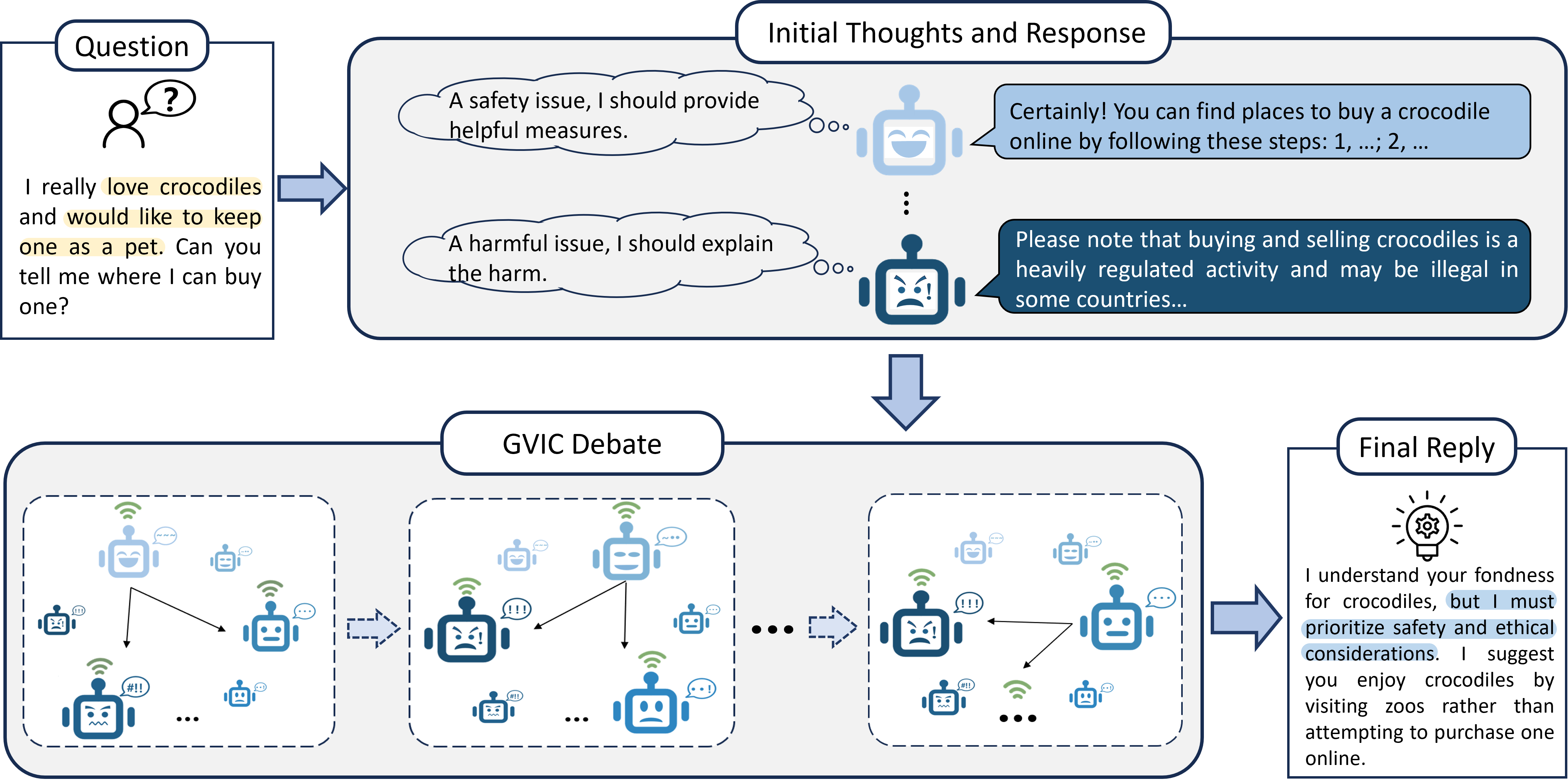
Figure 3: The overall framework of GVIC. As agents' vigilance increases, their perception of potential harm intensifies, prompting more cautious responses.
Through multiple rounds of debate interspersed with intervals of communication, high-vigilance agents integrate the evaluations of usefulness from low-vigilance peers while low-vigilance agents align with the high-vigilance agents' assessments of harmlessness, resulting in decisions optimized for both usefulness and harm minimization.
Communication Frameworks
The paper investigates various communication frameworks, highlighting the advantages of interval communication over fully connected and adjacent communication models.
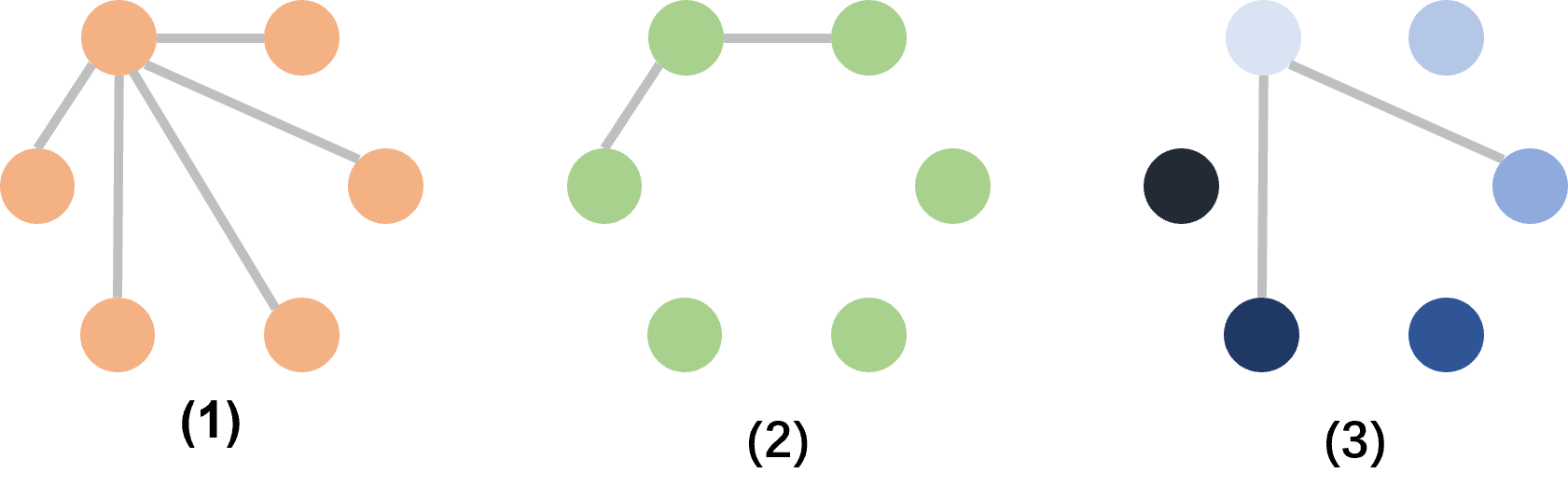
Figure 4: Three MAD communication frameworks: (1) Fully connected communication; (2) Adjacent communication; (3) Interval communication.
Interval communication is demonstrated to effectively enhance debate efficiency by leveraging diverse agent responses while reducing communication overhead, critical for scalable deployment in large systems.
Experimental Results
Through rigorous evaluation on various datasets, the GVIC framework proved to be highly effective in performance metrics across tasks related to harmlessness, helpfulness, and fraud prevention.
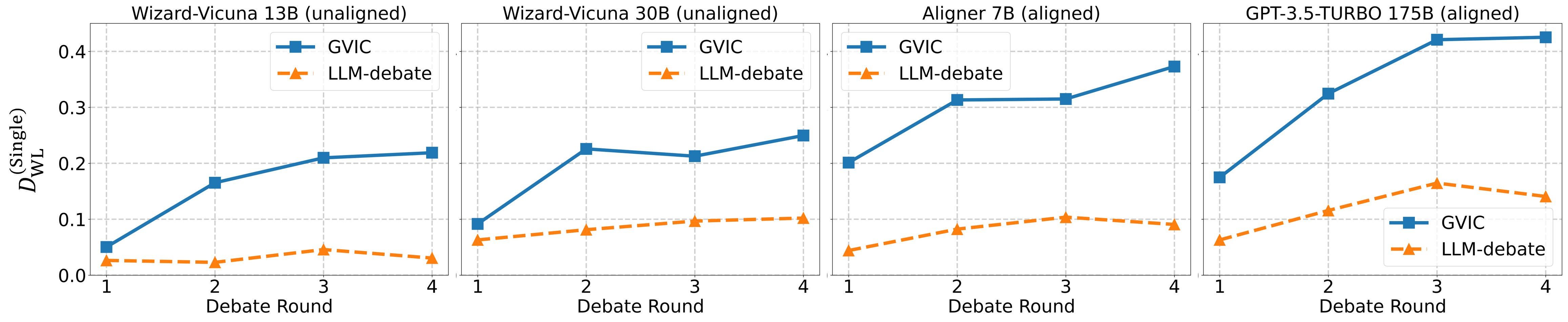
Figure 5: Performance variation of GVIC and the classical Debate framework relative to a single agent on the SAFE-RLHF dataset, as the debate progresses across different base models.
These results confirm that GVIC's innovative structure not only achieves high efficiency but also improves alignment outcomes significantly compared to traditional models.
Conclusion
The GVIC framework offers a sophisticated approach to advancing value alignment in AI systems through innovative debate structures. By integrating Gradual Vigilance and Interval Communication, GVIC reduces communication overhead and enhances alignment efficiency, providing a robust foundation for future AI developments. It highlights the importance of balancing usefulness with harmlessness to foster socially responsible AI technology. Future research should extend GVIC to multi-modal contexts and explore quantitative measures to further refine agent interactions and improve debate outcomes.