- The paper introduces a novel evaluation dataset, Plancraft, that challenges LLMs with realistic planning tasks in Minecraft, including unsolvable scenarios.
- It employs a depth-first search methodology combined with retrieval-augmented generation to benchmark both text-only and multi-modal LLM and VLM models.
- Results show larger LLMs excel in task solvability and action efficiency, emphasizing the benefit of integrating external knowledge.
Plancraft: Dataset for Planning with LLM Agents
Introduction to Plancraft
The paper "Plancraft: an evaluation dataset for planning with LLM agents" (2412.21033) introduces a dataset targeted at assessing the planning capabilities of LLMs within the context of crafting in Minecraft. Plancraft operates with both text-only and multi-modal interfaces. The dataset challenges LLM agents with planning tasks that require efficiency and decision-making, including scenarios that are unsolvable, thereby examining the agents' ability to discern feasibility.
Evaluation Framework
Plancraft incorporates an evaluation framework that benchmarks various state-of-the-art LLM and Vision LLMs (VLM) against handcrafted planners and uses retrieval-augmented generation (RAG) for information sourcing. This framework stresses the importance of realistic planning challenges and distinguishes Plancraft from other datasets by including the "Impossible Set" for evaluating decision-making under uncertainty.

Figure 1: A Plancraft example where the task is to craft a green bed. The agent uses observations to generate the next action, involving crafting the necessary green dye from cactus, then combining items in crafting slots.
The dataset emphasizes scenarios typical in game environments where solution paths may not be straightforward. By implementing tasks with varying complexity and intentional unsolvable scenarios, Plancraft provides a robust platform for evaluating real-world problem-solving capabilities.
LLM agents have seen a surge in applications across interactive environments due to their potential in leveraging pretrained knowledge for task completion via natural language. Plancraft fills a gap in existing benchmarks which often prioritize output success rates over efficiency or plan quality. Additionally, it addresses the deficiency in current datasets where the assumption that all tasks have a solution prevails — an assumption rarely upheld in practical settings.
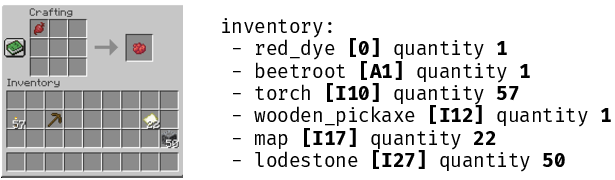
Figure 2: Example of Plancraft observation format in text and image, demonstrating encoding through slot notation for crafting grids and inventories.
As compared to datasets such as MineDojo and others illustrated in the paper, Plancraft uniquely combines environmental feedback mechanisms with the structured context of the Minecraft crafting interface, thus offering a novel approach to assessing agent capabilities in grounded human-centric environments.
Methodology
The paper details the implementation of Plancraft using a handcrafted planner and Oracle Retriever, highlighting a depth-first search method over possible crafting recipes. Such methodologies ensure a comprehensive exploration of craftable paths, although limitations in optimality due to search constraints are acknowledged.
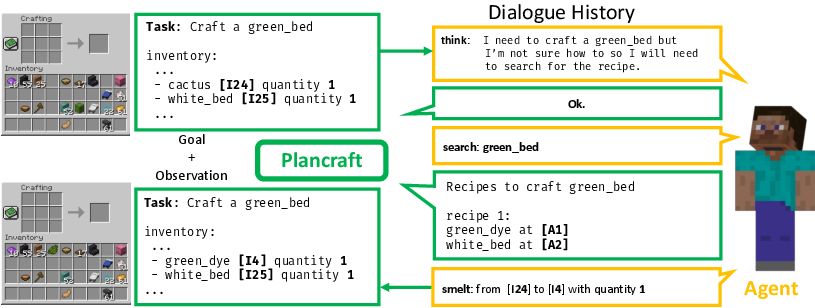
Figure 3: Example flow in Plancraft, outlining how varied tool sets and dialogue history come into play for decision-making processes.
Agents are evaluated under diverse conditions: varying sets of actions (like think and search), zero-shot and few-shot learning scenarios, and text versus multi-modal observations. For multi-modal aspects, an R-CNN model facilitates object recognition from images, demonstrating how text-bound LLM models can engage with visual data.
Results
The paper reports distinctive insights into agent performance, contrasting task success rates and plan length efficiencies across model sizes and action setups. Given the difficulty of tasks, larger LLMs show marked superiority over smaller counterparts in both solvability and action efficiency.
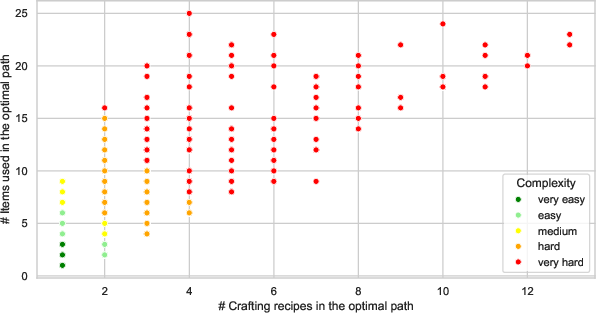
Figure 4: Scatterplot illustrating complexity in terms of items versus recipes required, showcasing varying difficulty levels in task setups.
Fascinatingly, integrating external knowledge through RAG significantly boosts task accomplishments, underscoring the worth of leveraging readily available human knowledge sources like the Minecraft Wiki for in-game planning.
Conclusion
Plancraft sets a sophisticated benchmark for evaluating LLM and VLM models based on problem-solving and planning efficiency. The experimental outcomes underscore the potential and challenges of LLMs in environments demanding nuanced planning and decision strategies. Future implications are directed towards enhancing tool adaptability and refining approaches for handling real-world knowledge that is inherently noisy or incomplete, setting the stage for advancements in RAG system applications.
This paper thus offers compelling insights into the practical and theoretical utility of Plancraft in driving forward the capabilities of AI in crafting complex decision-making environments.