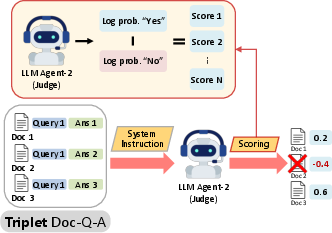
- The paper introduces a multi-agent filtering framework that improves document retrieval in RAG systems by eliminating irrelevant content.
- It employs three specialized LLM agents—Predictor, Judge, and Final-Predictor—to collaboratively rank and filter documents based on adaptive relevance thresholds.
- Experimental results show a 2-11% boost in answer accuracy, positioning MAIN-RAG as a scalable, training-free solution for real-time applications.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Introduction
"MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation" (2501.00332) presents a training-free framework that aims to improve the performance of Retrieval-Augmented Generation (RAG) systems by addressing the quality of retrieved documents. The paper identifies a critical issue in existing RAG methodologies: the presence of irrelevant or noisy documents that diminish response reliability and increase computational overhead. MAIN-RAG introduces a collaborative approach leveraging multiple LLMs agents to effectively filter and rank these documents, thus enhancing system accuracy without additional training requirements.

Figure 1: An overview of the proposed framework MAIN-RAG, consisting of three LLM agents to identify noisy retrieved documents for filtering.
Framework Components
Multi-Agent Architecture
The MAIN-RAG architecture employs a triad of LLM agents, each with distinct roles:
The use of inter-agent consensus and an adaptive filtering mechanism allows MAIN-RAG to process documents dynamically, improving efficiency by minimizing noise yet maintaining high document recall.
Adaptive Filtering Mechanism
The adaptive filtering component is driven by an adjustable relevance threshold, termed as the "adaptive judge bar" (τq), which varies according to the score distribution of retrieved documents. This adaptability facilitates robust performance across diverse queries by tailoring the filtering rigour to the specific context and document set at hand.
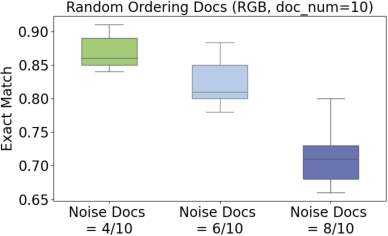
Figure 3: Impacts of document ordering on variance in RAG performance, where Noise Docs t/u means t noisy documents out of u retrieved documents.
Experimental Validation
Experimental results across four QA benchmarks reveal MAIN-RAG outperforming traditional RAG approaches, attaining a 2-11\% improvement in answer accuracy. The reduction in irrelevant documents not only boosts efficiency but also reinforces response consistency.
The quantitative analysis provided highlights the robustness of the proposed system, underscoring the efficacy of the multi-agent consensus strategy in delivering reliable, contextually accurate information.
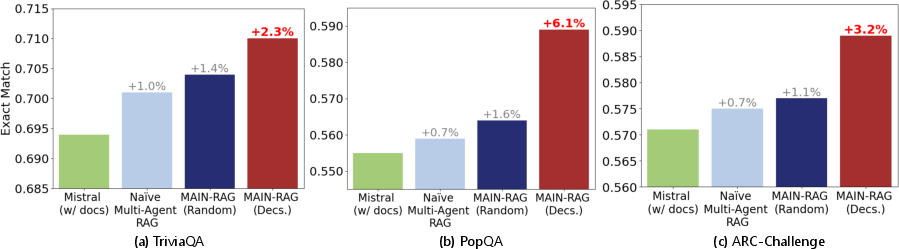
Figure 4: Performance comparison among MAIN-RAG and its variant baselines on three QA benchmarks, where all three LLM agents are pre-trained Mistral7B.
Implications and Future Directions
Practical Implications
MAIN-RAG offers a scalable, training-free solution that can be seamlessly integrated into existing RAG workflows, presenting a practical alternative for real-time applications that demand high reliability and contextual relevance, such as healthcare and legal domains.
Theoretical Implications
The introduction of a multi-agent framework within retrieval-augmented systems opens new avenues for research on agent collaboration and inter-agent communication mechanisms.
Speculation on Future Developments
Potential future developments in the field might explore the integration of human feedback loops to further refine the filtering thresholds and adaptively tune LLM agents to enhance efficacy across broader task domains.
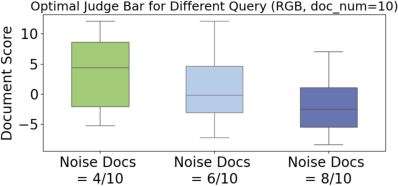
Figure 5: Optimal judge bars for different noise ratios in different queries, where Noise Docs t/u means t noisy documents out of u retrieved documents.
Conclusion
"MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation" provides a robust framework for improving RAG systems by effectively addressing the challenge of noisy document retrieval. Through its innovative multi-agent strategy and adaptive mechanisms, MAIN-RAG demonstrates marked improvements in response accuracy and system reliability, offering a compelling pathway for advancing RAG methodologies in both theoretical and practical domains.