- The paper introduces a neural memory module that learns at test time using a surprise metric, momentum, and forgetting mechanisms.
- It presents three architectures—MAC, MAG, and MAL—each integrating memory differently to enhance context and decision-making.
- Experimental evaluations show superior long-context handling, scaling to over 2 million tokens with improved accuracy in diverse tasks.
Titans: Learning to Memorize at Test Time
This essay discusses the research and implementation of a novel memory module for deep learning architectures, inspired by human memory systems, called Titans. Titans introduce a neural memory module capable of learning to memorize at test time, integrating both short-term and long-term memory mechanisms. The research highlights significant improvements over existing Transformer and linear recurrent models, especially in tasks requiring long context handling and reasoning.
Neural Memory Module
The neural memory module is the core innovation within the Titans architecture, combining associative memory with an in-context learning approach. This approach allows the model to adapt its memory at test time based on surprising or unexpected inputs, akin to human memory processing.
- Learning Process and Surprise Metric: The memory training uses an online learning framework where the model updates its parameters based on a surprise metric, calculated as the gradient of the loss with respect to the input. This ensures that the memory adapts to new, surprising data.
- Momentum and Forgetting: To manage memory effectively, a momentum term is introduced to carry forward the significance of past surprises. Additionally, a forgetting mechanism allows the selective erasure of outdated or irrelevant information, akin to weight decay in optimization.
- Deep Memory Architecture: The module leverages multi-layer perceptrons (MLPs) for its memory, extending beyond simple linear models for richer, non-linear memorization capabilities.
- Parallelized Training: The memory training is parallelized to leverage GPU/TPU hardware, reformulating gradient descent to exclusively use matrix multiplications, significantly improving computational efficiency.
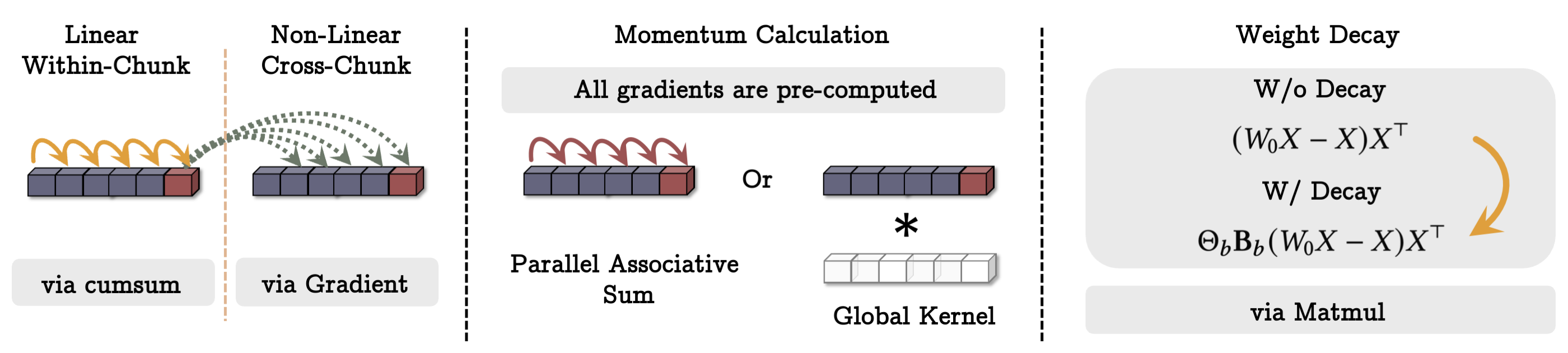
Figure 1: The illustration of how the training of neural memory can be done in parallel and using matmuls.
Titans Architectures
Titans extends the neural memory module across three architectural variants—Memory as a Context (MAC), Memory as a Gate (MAG), and Memory as a Layer (MAL)—each variant designed to integrate the memory module differently into the deep learning architecture.
- MAC Architecture: Utilizes the neural memory as contextual information, augmenting the Transformer attention mechanism. The memory is used to retrieve historical context relevant to the current segment, allowing deeper context integration and decision-making.
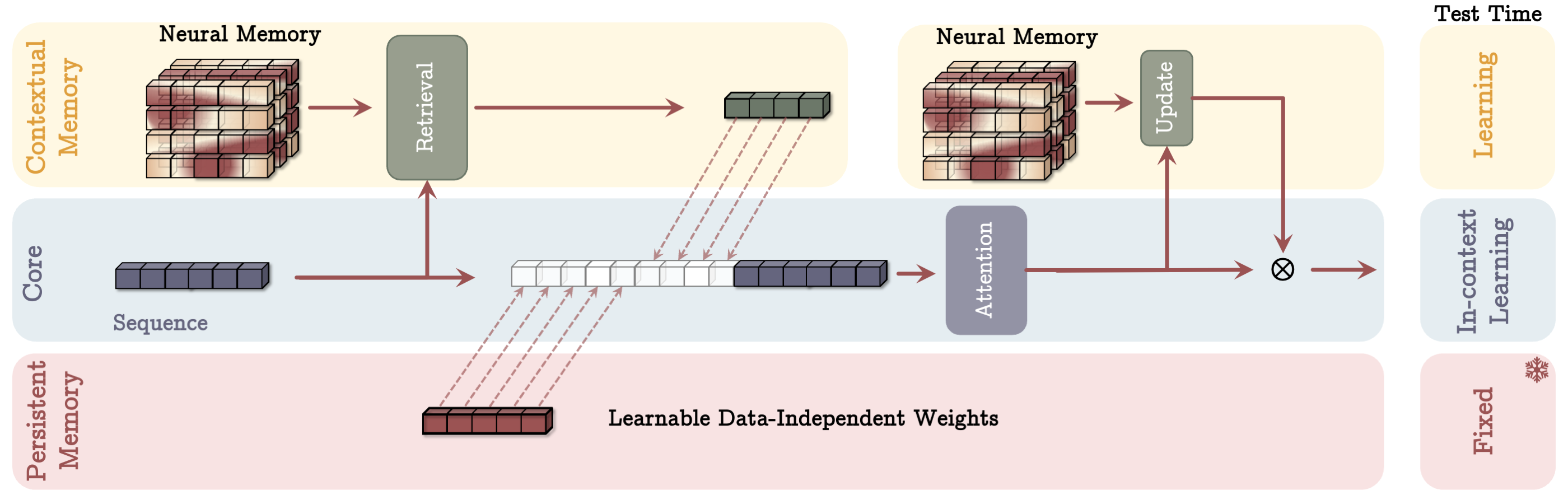
Figure 2: Memory as a Context (MAC) Architecture: Displays integration of past memory with core network segments.
- MAG Architecture: Employs a gating mechanism that controls memory influence on the core learning module, allowing for dynamic modulation between learned and immediate data.
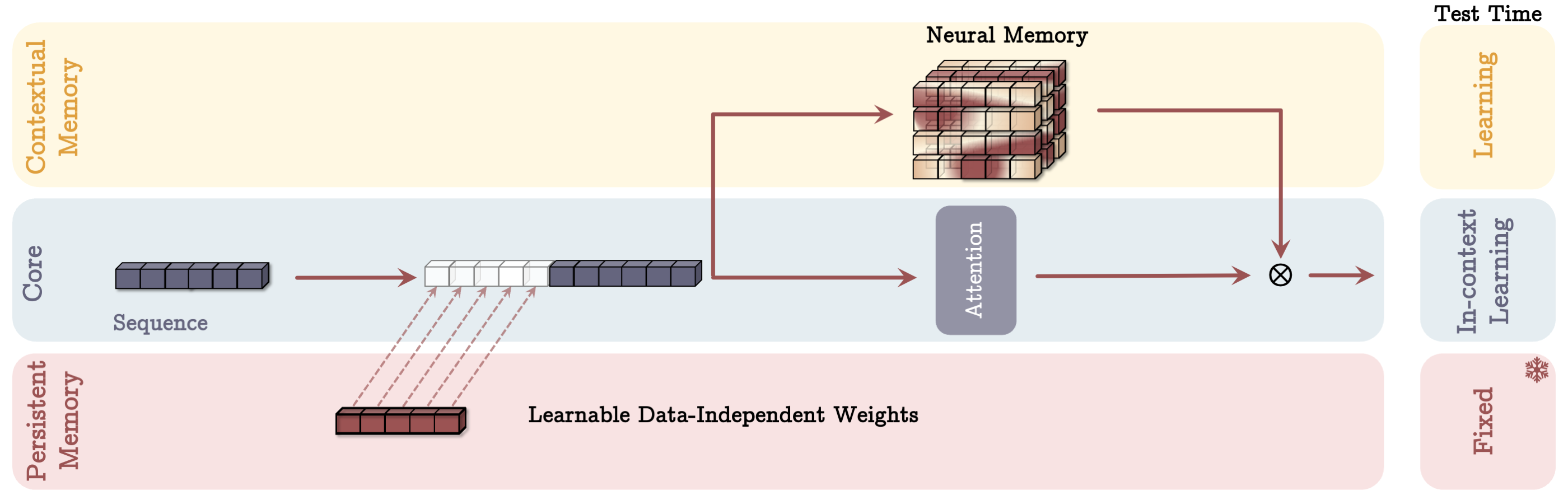
Figure 3: Memory as a Gate (MAG) Architecture: Demonstrates gating mechanism for integrating memory influence.
- MAL Architecture: Embeds the memory module as a modular layer directly within the neural network stack, acting as a preprocessing stage for information compression before application within the main network attention layers.
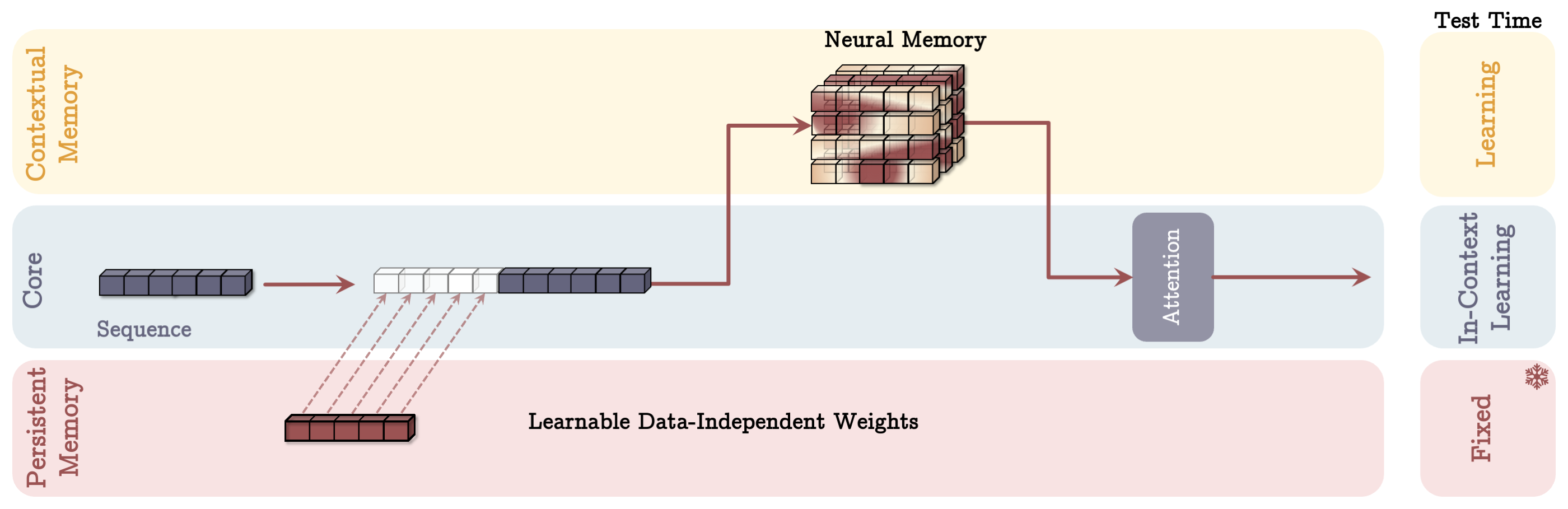
Figure 4: Memory as a Layer (MAL) Architecture: Exhibits memory layer role in compressing past and present context.
Experimental Evaluation
Titans were evaluated on benchmarks across language modeling, commonsense reasoning, genomics, and time-series forecasting, showcasing their efficacy in handling larger context windows with higher accuracy compared to state-of-the-art Transformer and linear recurrent models. Key results include:
- Improved Scaling: Titans scale effectively to context windows larger than 2 million tokens, maintaining accuracy and memory efficiency where other models falter.
- Superior Long Context Handling: The neural memory module demonstrates the ability to remember critical long-term dependencies, outperforming models like Transformers and existing recurrent architectures.
- Task Performance: Evaluation on tasks such as needle-in-a-haystack and genomics benchmarks reveals higher accuracy and adaptability.
Conclusion
The introduction of Titans and its neural memory module offers significant strides in the scalability and functionality of deep learning architectures. By drawing inspiration from human cognitive processes, Titans bridge the gap between traditional model scaling challenges and the nuanced demands of real-world applications needing extensive contextual understanding and dynamic memory interactions. Future exploration in this domain may focus on optimizing these architectures further for even more diverse and demanding datasets.