Memory-Augmented Transformers: A Systematic Review from Neuroscience Principles to Enhanced Model Architectures
Abstract: Memory is fundamental to intelligence, enabling learning, reasoning, and adaptability across biological and artificial systems. While Transformer architectures excel at sequence modeling, they face critical limitations in long-range context retention, continual learning, and knowledge integration. This review presents a unified framework bridging neuroscience principles, including dynamic multi-timescale memory, selective attention, and consolidation, with engineering advances in Memory-Augmented Transformers. We organize recent progress through three taxonomic dimensions: functional objectives (context extension, reasoning, knowledge integration, adaptation), memory representations (parameter-encoded, state-based, explicit, hybrid), and integration mechanisms (attention fusion, gated control, associative retrieval). Our analysis of core memory operations (reading, writing, forgetting, and capacity management) reveals a shift from static caches toward adaptive, test-time learning systems. We identify persistent challenges in scalability and interference, alongside emerging solutions including hierarchical buffering and surprise-gated updates. This synthesis provides a roadmap toward cognitively-inspired, lifelong-learning Transformer architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is a guide to making Transformers (the kind of AI used in tools like ChatGPT) better at “remembering.” It connects ideas from how the human brain uses memory—like short-term and long-term memory, attention, and sleep-like “replay”—to new engineering tricks that let Transformers handle longer texts, reason better, learn during use (not just during training), and keep useful knowledge without forgetting old facts.
What questions the paper tries to answer
The authors ask simple but important questions:
- How can we give Transformers a memory that works more like a human’s, across seconds, minutes, and years?
- What kinds of memory add-ons exist, and what are they each good for?
- How do models decide what to store, when to update or forget, and how to find the right thing later?
- What problems still block progress, and what new ideas could fix them?
How the researchers approached it (in everyday terms)
This is a review paper: the authors didn’t run one new experiment; they read and compared many recent studies and organized them into a clear map.
To make sense of a crowded field, they use three lenses (think of them as three ways to sort the tools in a workshop):
- By goal: What is the memory used for? (e.g., longer context, better reasoning, integrating knowledge, adapting to new situations)
- By memory type: Where is the memory kept? (e.g., inside the model’s weights, in its temporary “state,” in an external database, or a mix)
- By how it connects: How does the model plug memory into thinking? (e.g., through attention, gates/filters, or associative “find by content” search)
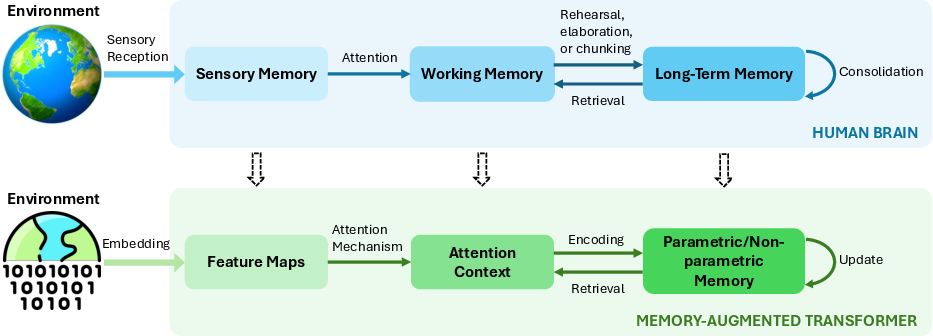
They also borrow concepts from neuroscience and explain them in AI terms:
- Sensory memory → quick buffers for raw input (like token embeddings)
- Working memory → a small scratchpad for current thinking (like attention over a recent window)
- Long-term memory → durable storage (like external memories or knowledge built into the model’s parameters)
- Attention and gating → the “librarian” that decides what to focus on and what to store
- Consolidation/replay → moving important stuff from short-term to long-term, sometimes triggered by “surprise”
What they found and why it matters
Here are the main takeaways, translated into plain language:
- The field is shifting from “static memories” to “adaptive, learn-as-you-go” systems
- Old approach: keep a rolling cache of recent tokens and hope it’s enough.
- New approach: detect novelty or surprise, store meaningful chunks (episodes), compress intelligently, and retrieve by content, not just by position.
- Different goals need different kinds of memory
- Longer context: smarter caching, compression, and tiered storage (like a small fast memory + a big slower memory) let models handle very long documents without huge costs.
- Better reasoning: memory helps keep multi-step chains coherent and re-check facts, rather than losing track in long sequences.
- Knowledge integration: combining parametric knowledge (in the weights) with external retrieval (like a fact library) gives both speed and freshness.
- Adaptation: surprise-gated updates let models learn new facts during use without rewriting all weights or forgetting old facts.
- There are four core memory operations (just like how you manage a school notebook):
- Reading: how the model finds what it needs (best when it can search by meaning, not just by where it was written).
- Writing: what to store and when (ideally triggered by relevance or surprise, not every token).
- Forgetting: clearing or compressing low-value bits to avoid clutter and interference.
- Capacity management: using hierarchies (fast small + slow large) and compression so memory scales without blowing up compute or cost.
- Three main ways to plug memory into a Transformer
- Attention fusion: treat memories like extra tokens to attend to.
- Gated control: “doors” decide whether to write/read/ignore based on signals like prediction error.
- Associative retrieval: “find by content” like how a single cue can trigger a full memory.
- Neuroscience principles are turning into practical design rules
- Multi-timescale memory (sensory → working → long-term)
- Surprise/novelty signals to decide what’s worth storing
- Replay/consolidation to reduce catastrophic forgetting
- Content-addressable recall (pattern completion) to retrieve from partial cues
- Cross-modal binding to connect information across text, vision, audio, etc.
- Big challenges that remain
- Scalability and energy: long contexts are expensive; we need sparse, selective access.
- Interference: new information can overwrite or confuse old facts; better consolidation and gated updates help.
- Retrieval quality: it’s hard to always fetch the most relevant snippet at the right time.
- Self-management: models must decide what to keep, compress, or discard on their own.
- Promising solutions emerging
- Hierarchical buffering (like a fast GPU “working memory” plus a large CPU “long-term memory”)
- Reversible or smart compression (shrink without losing meaning)
- Episodic segmentation (store meaningful events, not just raw tokens)
- Surprise-gated writes (update only when it matters)
- Hybrid memory (mix inside-the-model knowledge with external stores and retrievers)
Why this matters (real-world impact)
If these ideas continue to improve, we’ll get AI systems that:
- Remember relevant things over hours, days, or longer—like a helpful assistant that actually recalls your preferences and prior conversations.
- Learn safely at test time—adapting to new topics or tools without breaking what they already know.
- Handle very long documents—keeping context and coherence in research, law, medicine, and code.
- Use energy and compute more efficiently—by reading and writing memory sparingly and smartly, not eagerly and expensively.
- Move closer to human-like cognition—coordinating short- and long-term memory, focusing attention on what matters, and consolidating knowledge over time.
In short, the paper offers a roadmap for building Transformers that don’t just “look up patterns,” but manage memory actively—more like brains do—so they can think over longer spans, learn as they go, and stay reliable as the world changes.
Collections
Sign up for free to add this paper to one or more collections.