- The paper introduces Agent Laboratory, an autonomous framework that leverages LLM agents to execute literature reviews, experiments, and report writing, significantly reducing research time and cost.
- The methodology employs specialized roles—PhD, Postdoc, and ML Engineer agents—integrating state-of-the-art LLMs with iterative code generation and self-improvement loops for optimal performance.
- Evaluation results reveal that human-involved co-pilot mode enhances output quality and that the mle-solver consistently outperforms alternatives on MLE-Bench challenges.
Agent Laboratory: LLM Agents as Research Assistants
The paper "Agent Laboratory: Using LLM Agents as Research Assistants" (2501.04227) introduces Agent Laboratory, an autonomous framework leveraging LLMs to streamline the scientific research process. This system aims to reduce the time and resources required for research, while also improving the overall quality of the outputs. Agent Laboratory takes a human-provided research idea and then autonomously executes the literature review, experimentation, and report writing stages to produce a code repository and a research report, allowing for human feedback at various points. The study evaluates the framework using state-of-the-art LLMs, researcher surveys, and NeurIPS-style evaluations, demonstrating reduced research expenses and state-of-the-art performance on MLE-Bench challenges.
The paper contextualizes Agent Laboratory within the landscape of LLMs and AI-driven research. It references the transformer architecture and its application in models such as Claude, Llama, and ChatGPT. It emphasizes the capacity of LLMs to handle language-based tasks. The paper also covers LLM agents, which utilize chain-of-thought prompting, self-improvement, and external tool integration to tackle real-world tasks. This section provides the foundation for understanding how Agent Laboratory employs these technologies to automate machine learning research.
The related work section reviews automated machine learning, AI in scientific discovery, and LLMs for research-related tasks. It acknowledges the progress made by systems like ResearchAgent and The AI Scientist, which automate research ideation and paper generation. It highlights that Agent Laboratory distinguishes itself by assisting human scientists in executing their research ideas, rather than operating independently.
Agent Laboratory Framework
Agent Laboratory comprises three primary phases: Literature Review, Experimentation, and Report Writing (Figure 1). The Literature Review phase gathers relevant research papers using the arXiv API, with the PhD agent summarizing papers, extracting full texts, and adding pertinent information to the curated review.
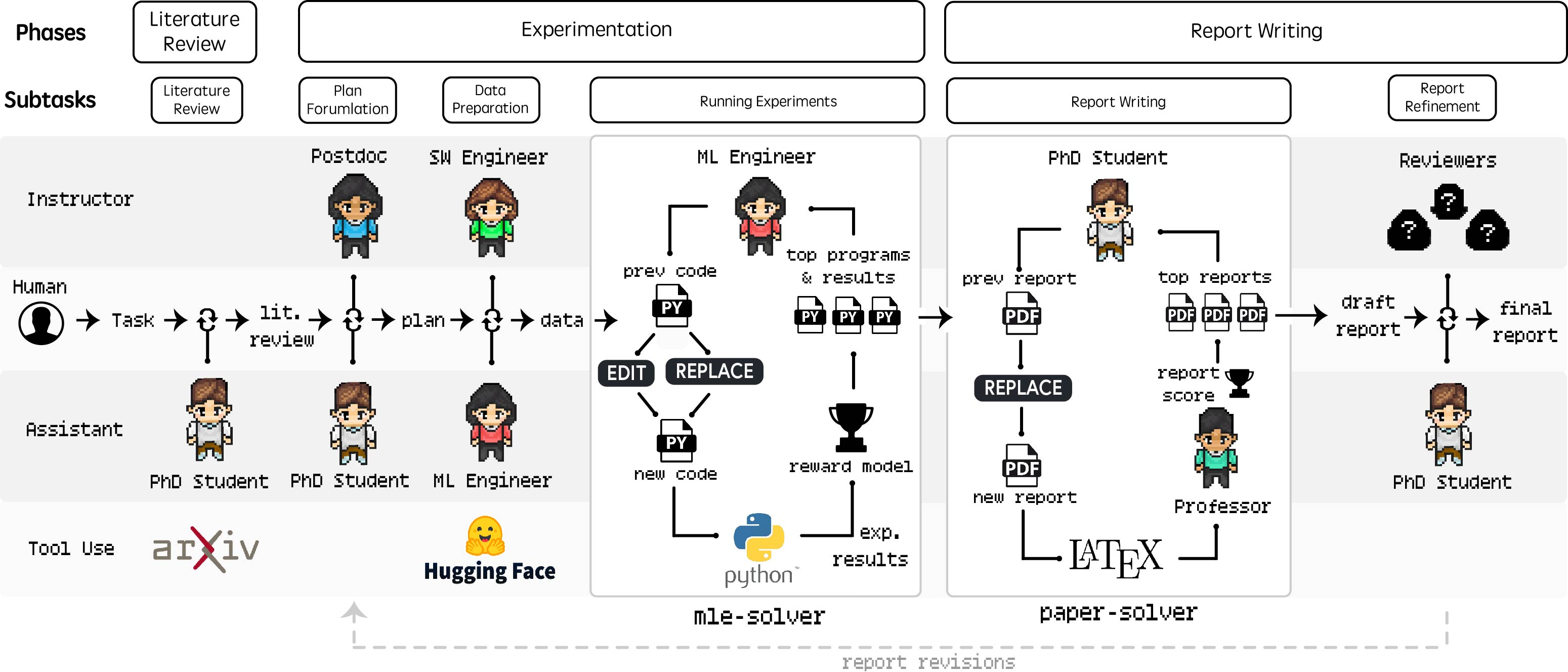
Figure 1: Agent Laboratory Workflow, detailing the Literature Review, Experimentation, and Report Writing phases, including tasks, tools, and human-agent roles.
The Experimentation phase involves plan formulation, data preparation, running experiments, and results interpretation. The PhD and Postdoc agents collaborate to formulate a research plan. The ML Engineer agent then prepares the data, leveraging Hugging Face datasets. The mle-solver module generates, tests, and refines machine learning code autonomously (Figure 2). This module uses command execution, code execution, program scoring, self-reflection, and performance stabilization to optimize the generated code. Finally, the PhD and Postdoc agents interpret the experimental results to inform the final report.
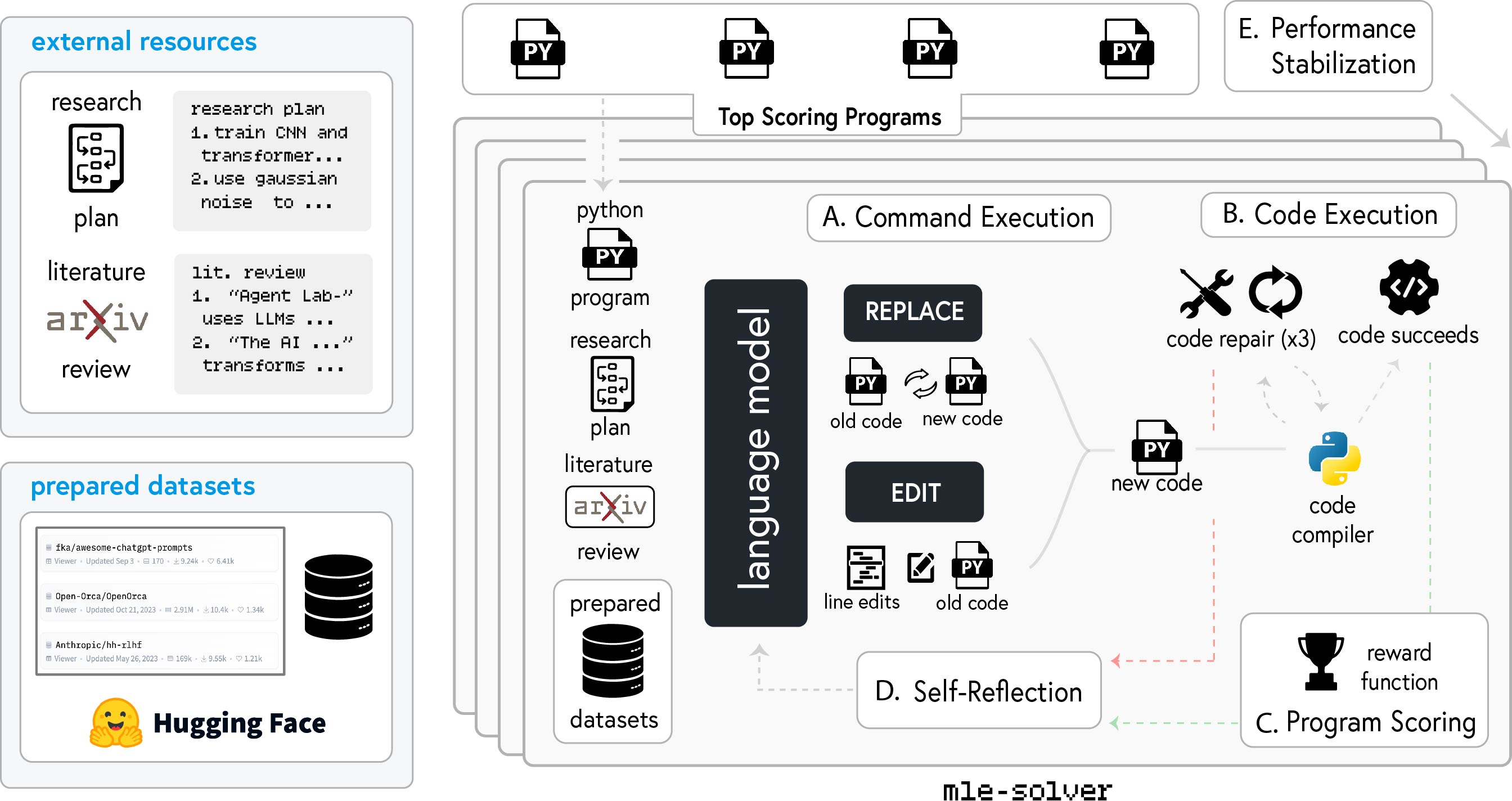
Figure 2: Overview of the mle-solver workflow, highlighting the iterative process of code generation, execution, scoring, self-reflection, and performance stabilization.
The Report Writing phase synthesizes research findings into an academic report using the paper-solver module (Figure 3). This module generates an initial report scaffold, conducts arXiv research, edits the report, and refines it based on feedback. The system leverages an automated review system, adapted from existing work, to simulate the scientific paper review process. The PhD agent then decides whether to revise the paper or finalize the project based on the reviewer feedback. Agent Laboratory offers both autonomous and co-pilot modes, with the latter involving human feedback at the end of each subtask.
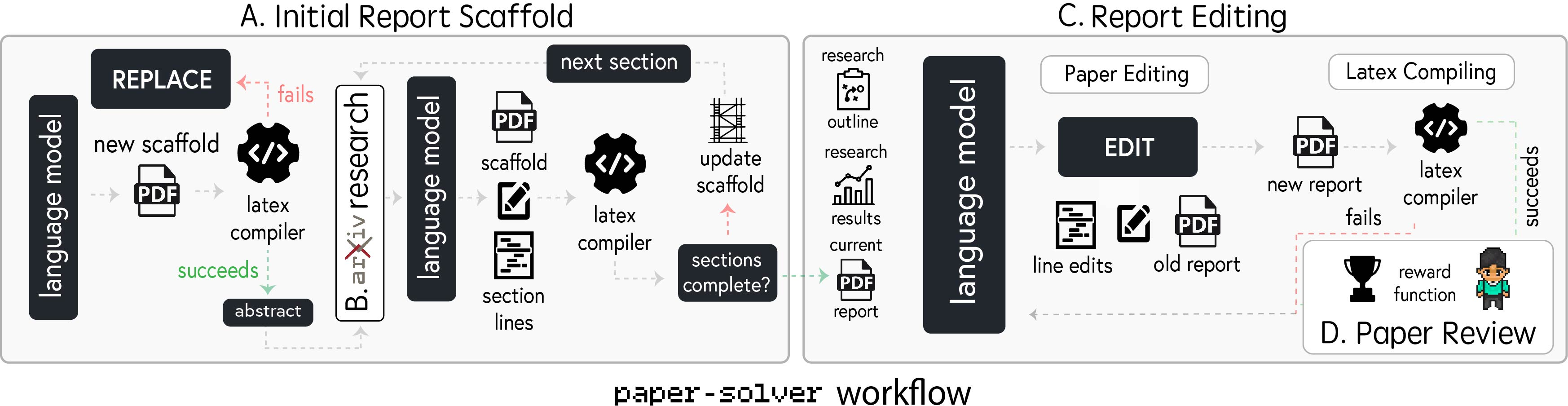
Figure 3: Graphical outline of paper-solver, illustrating the step-by-step process of generating and refining academic research reports.
Experimental Results
The paper presents a comprehensive evaluation of Agent Laboratory's efficacy in producing research. The evaluation covers the quality of papers generated in autonomous mode, the impact of human involvement in co-pilot mode, and detailed runtime statistics for various model backends. It also evaluates the mle-solver in isolation on MLE-Bench challenges.
Human evaluators assessed papers generated in autonomous mode based on experimental quality, report quality, and usefulness (Figure 4). The results indicate that o1-preview was perceived as the most useful, while o1-mini achieved the highest experimental quality scores, and gpt-4o generally lagged behind. NeurIPS-style evaluations revealed that o1-preview performed best in clarity and soundness, but a notable gap emerged between human and automated evaluations.
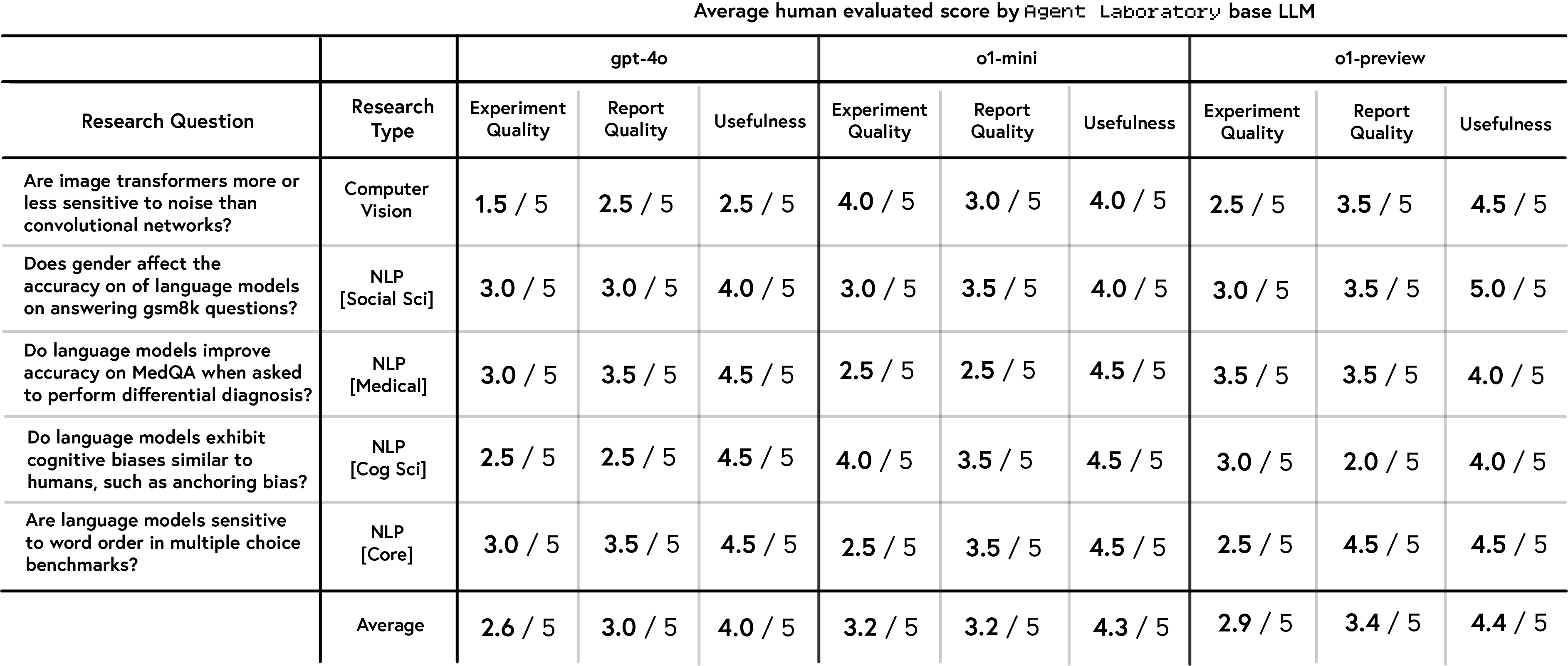
Figure 4: Human evaluation scores of papers generated by Agent Laboratory in autonomous mode, across different LLM backends.
The co-pilot mode was evaluated on custom and preselected topics, showing higher overall scores compared to autonomous mode (Figure 5). Researchers rated Agent Laboratory's utility, usability, and overall satisfaction, with most participants indicating they would continue using the tool. The evaluation of co-pilot generated papers involved self-assessment and external evaluation using NeurIPS-style criteria. External evaluations generally showed higher scores than self-assessments, with significant improvements in quality and significance.
The analysis of runtime statistics shows that gpt-4o exhibited the fastest execution times and lowest monetary costs, while o1-preview achieved the highest average subtask success rate (Figure 6).
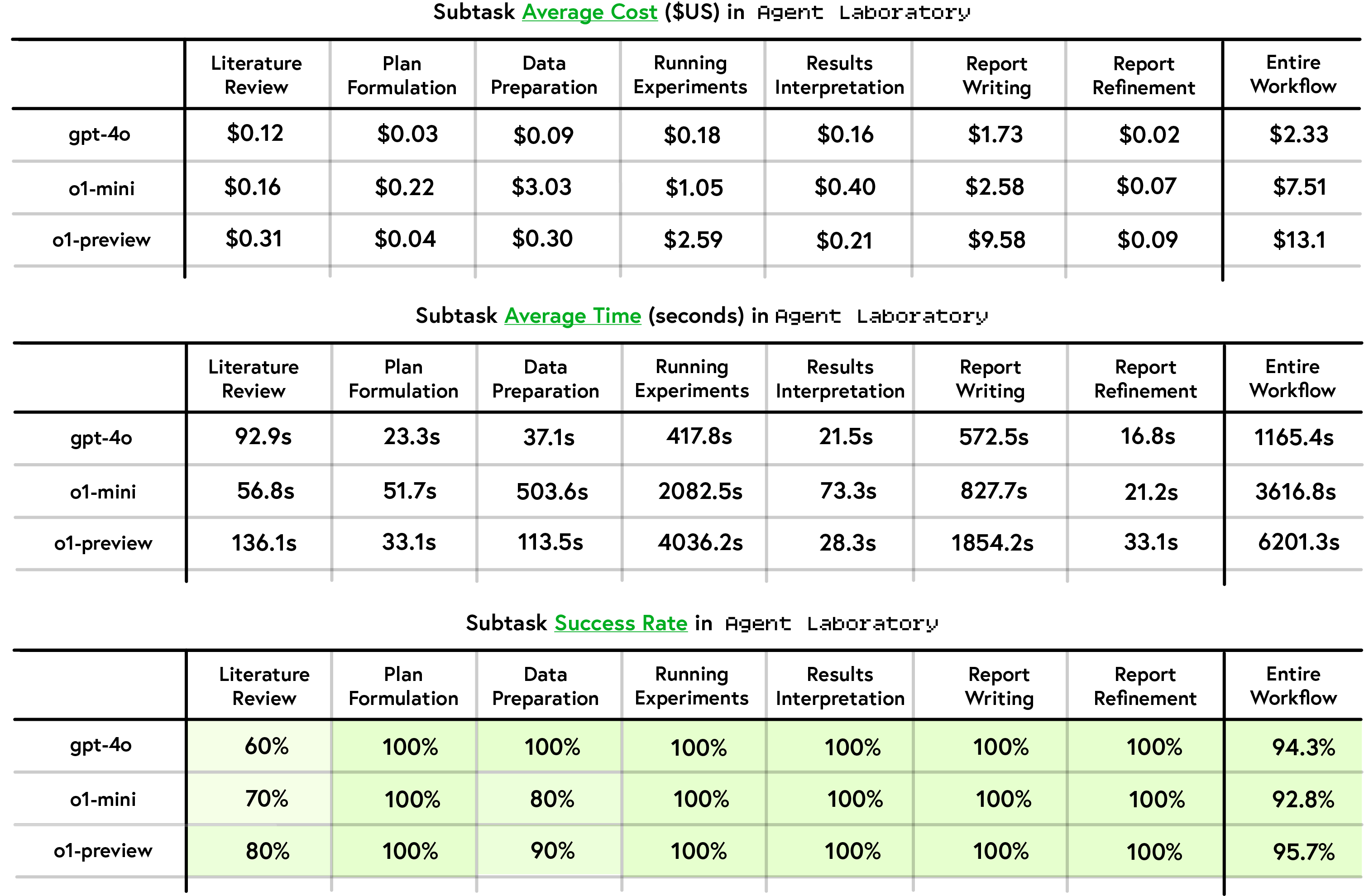
Figure 6: Performance and Cost Evaluation, summarizing runtime statistics, cost, and success rates across different model backends.
Evaluations of mle-solver on MLE-Bench showed that it achieved higher consistency and scoring compared to other solvers (Figure 7), earning more medals, including gold and silver, than MLAB, OpenHands, and AIDE.
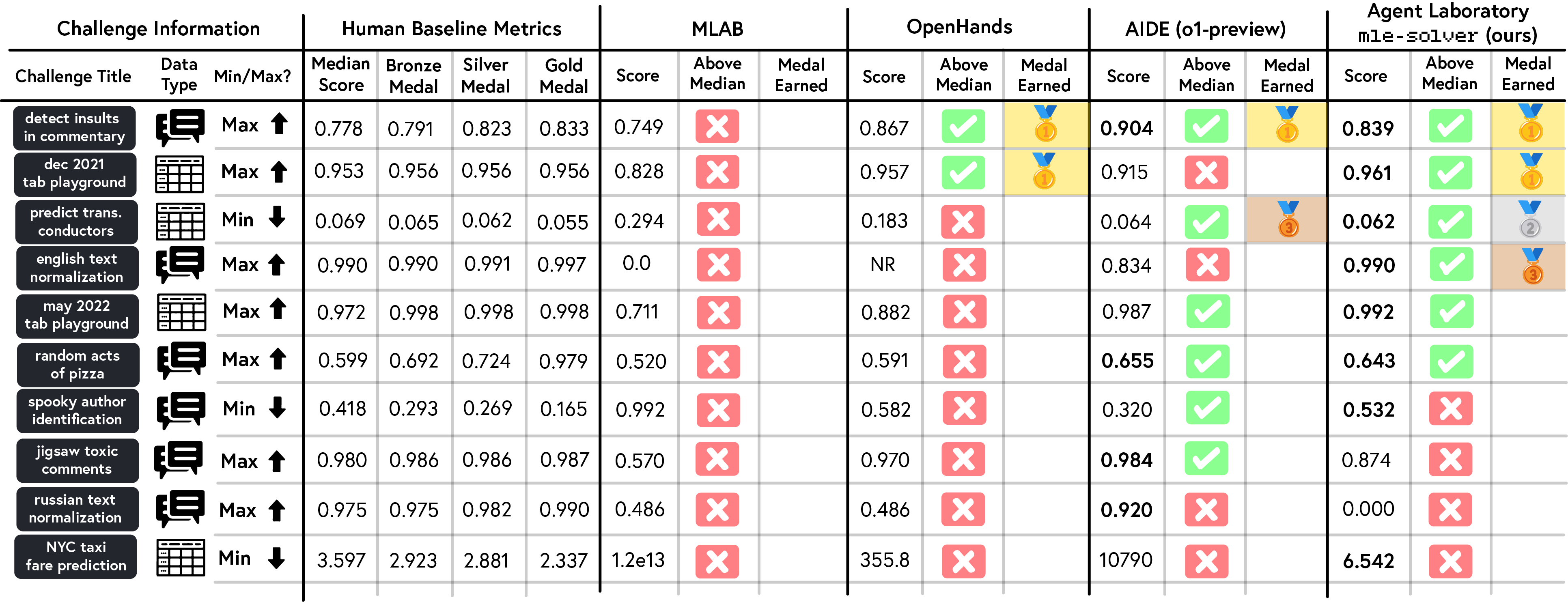
Figure 7: Average score of four methods (MLAB, OpenHands, AIDE, and mle-solver) on a subset of MLE-Bench, illustrating the performance of each method.
Limitations and Ethical Considerations
The paper acknowledges limitations within the workflow. The LLM-based paper-solver is evaluated by emulated NeurIPS reviewers, which, while aligned with real reviewers, produces less satisfactory research reports than other similar systems. The study also points out the challenges with the automated structure of the paper, such as the enforced structure and limited number of figures, and code hallucinations in some generated papers. Common failure modes observed during the runtime of Agent Laboratory include instruction-following challenges, token limit issues, figure generation problems, and experimental inaccuracies.
The paper also addresses the ethical considerations of autonomous research tools, including the potential for substandard outputs, amplification of biases, and misuse for unethical purposes. It emphasizes the need for transparent disclosure of AI involvement and robust governance mechanisms to align with ethical research standards.
Discussion and Conclusion
The paper concludes by positioning Agent Laboratory as a step toward more efficient, human-centered research workflows that leverage the power of LLMs. It highlights the variability in performance across LLM backends, the gaps between human and automated evaluations, and the potential for human involvement to improve output quality. The framework allows human researchers to focus more on conceptual design and critical thinking. Future research directions could involve longitudinal studies comparing researchers' outcomes with and without Agent Laboratory, as well as exploring automatic agent workflow and agent generation techniques to optimize the Agent Laboratory workflow. The authors express hope that Agent Laboratory may serve as a valuable tool to enable scientific discovery.