- The paper introduces an iterative batch unrolling strategy that consolidates successive kernel launches into a single CUDA Graph to minimize overhead.
- It employs manual graph creation and performance modeling to determine an optimal batch size, achieving up to a 1.4× speed-up for smaller workloads.
- The study demonstrates that kernel batching with CUDA Graphs delivers consistent performance benefits across diverse GPU architectures and real-world applications.
Introduction
The paper "Boosting Performance of Iterative Applications on GPUs: Kernel Batching with CUDA Graphs" introduces a methodology to optimize GPU performance by batch processing kernels using CUDA Graphs. As GPUs evolve and become prevalent in accelerating scientific applications, the study focuses on addressing the constant overhead associated with launching fine-grained kernels. CUDA Graph consolidates multiple kernel launches into a single graph-based execution, thus reducing overhead. This paper proposes a strategy for optimizing iteratively launched kernels by grouping them into iteration batches, followed by unrolling these batches into a CUDA Graph to improve performance.
Methodology
The central proposal of the paper involves an iteration batch unrolling strategy where successively launched kernels are grouped. These groups are then used to construct a CUDA Graph, thus reducing the launch overhead. The method balances the graph creation overhead against the performance gains from reduced execution time (Figure 1).
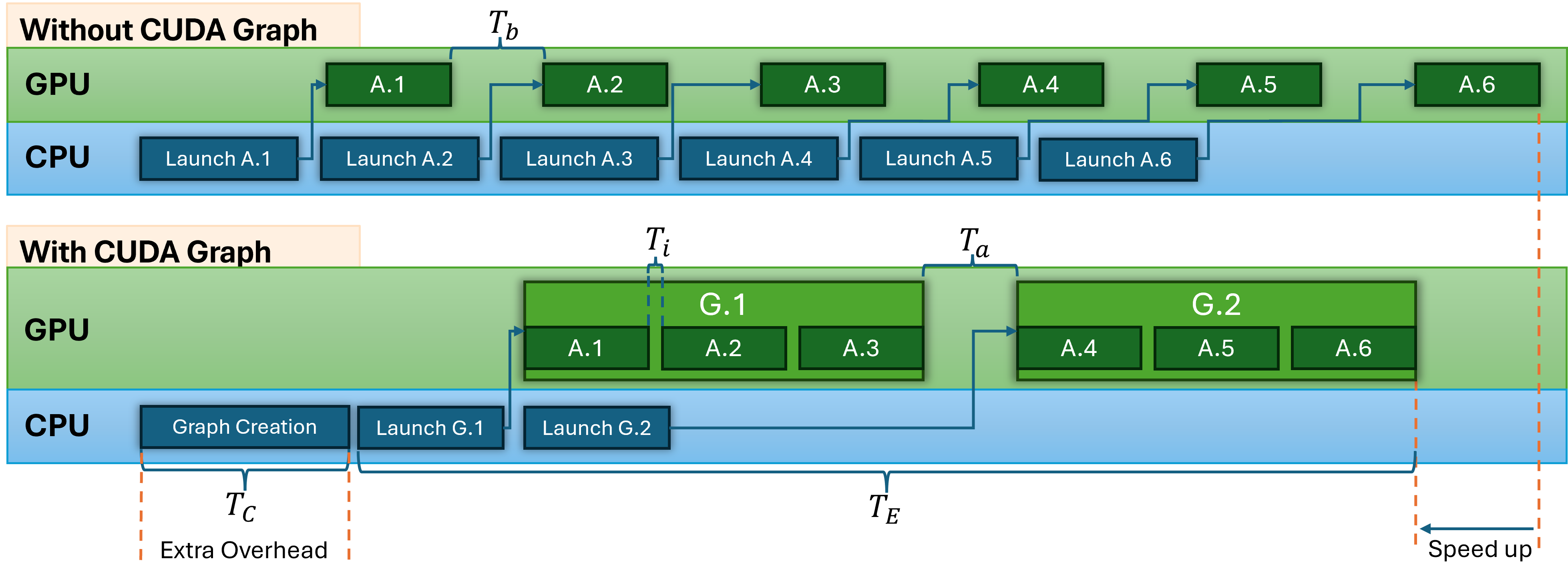
Figure 1: A schematic representation of the iteration batch unrolling strategy presented in this paper.
The methodology involves two significant components:
- Manual Graph Creation: The authors chose the manual graph creation method, providing granular control over the graph structure and dependencies, crucial for optimizing performance.
- Performance Modeling: A performance model evaluates the graph creation and execution, helping identify an optimal batch size that maximizes performance gains without incurring excessive overhead. The model considers creation time TC and execution time TE (Equations \ref{eq:T_total} to \ref{eq:graph_executions} in the paper).
Experimental Setup
The study employs a skeleton application to validate the benefits of the proposed methodology. This application serves as a general example for converting iterative solvers into CUDA Graphs and for deriving a performance model. Tests are conducted on an Nvidia A100 and a Nvidia Grace-Hopper system to ensure robustness across different architectures.
Results
The experiments demonstrate that the graph creation overhead is linear up until a batch size threshold, beyond which non-linear effects are observed due to resource constraints (Figure 2).
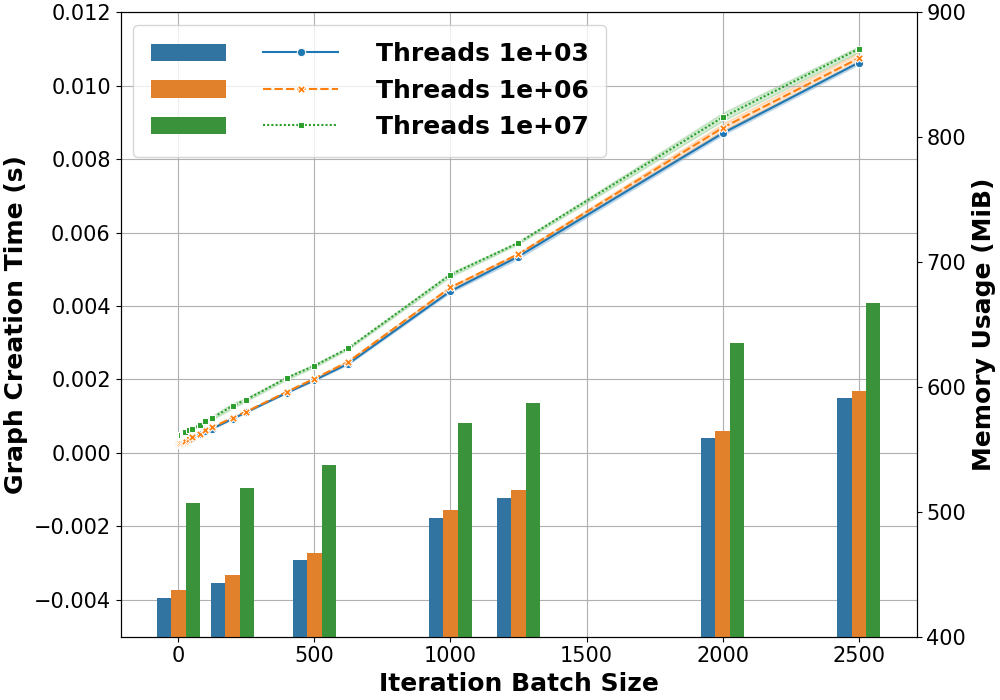
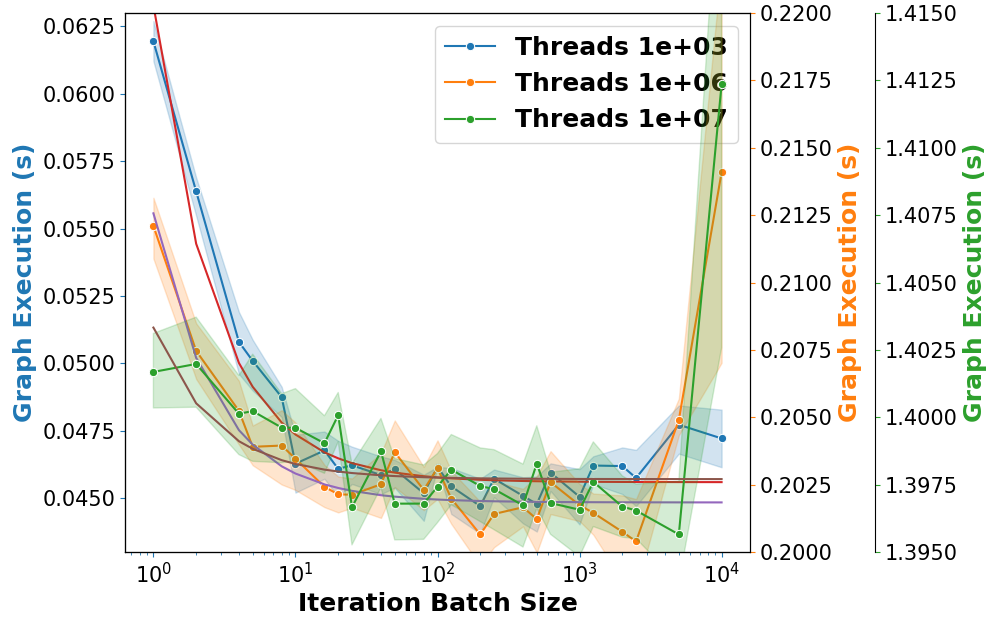
Figure 2: Graph creation overhead and memory usage as iteration batch size increases.
The execution time benefits from batching are depicted in Figure 3, indicating a reduction in overall execution time when the batch size is optimized. The performance model suggests an optimal batch size around 100 nodes.
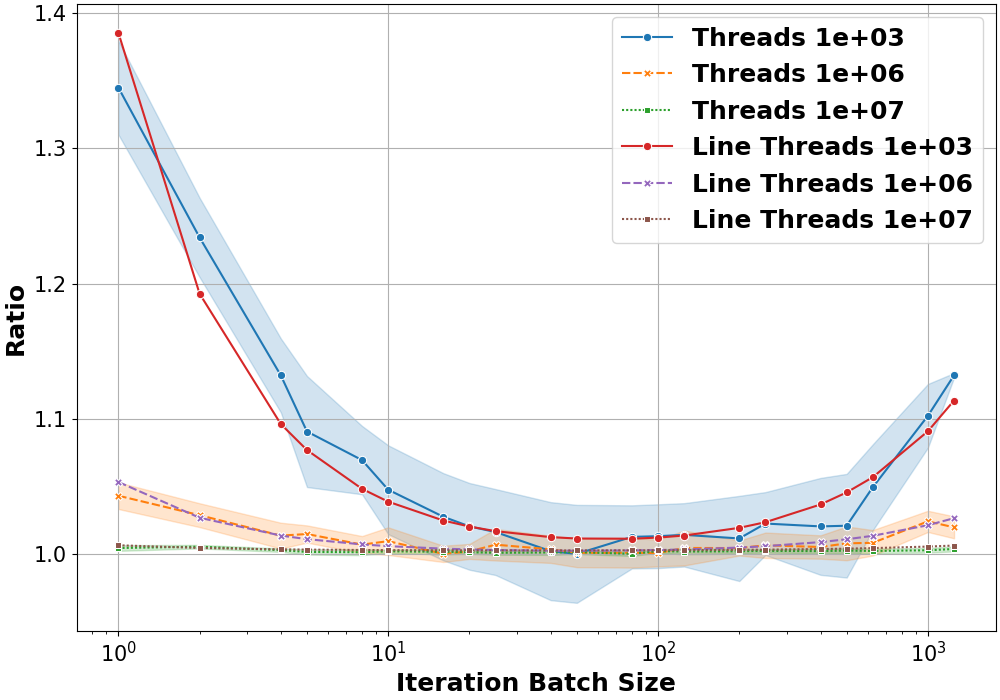
Figure 3: Skeleton application performance for different batch sizes.
The results also highlight how smaller workloads (e.g., fewer threads per kernel) benefit more from the strategy, achieving up to a 1.4× speed-up (Figure 4). Larger workloads, while seeing less relative gain, do not suffer performance penalties.
Figure 4: Skeleton application speedup compared to baseline on different systems.
Discussion
The work demonstrates that the iterative batch unrolling strategy can significantly enhance performance for iterative GPU applications, especially those with small workloads. The strategy's effectiveness is validated across different applications, including Hotspot and FDTD Maxwell solvers, showcasing consistent performance boosts.
However, the implementation's complexity may limit adoption unless integrated into higher-level abstractions or frameworks. Future research could focus on automating conversion processes within DSLs or heterogeneous programming frameworks to enhance usability and broaden applicability.
Conclusion
Overall, the research provides a compelling strategy to leverage CUDA Graphs for performance optimization in iterative applications, with significant benefits for real-world workloads. The methodology outlines crucial considerations for batch-sizing and highlights potential for implementation within larger frameworks to maximize accessibility and impact.