- The paper presents NEAR, a novel framework using noise-conditioned energy functions to produce smooth reward landscapes from expert observational data.
- It integrates score-based models and an annealing strategy to create continuous reward signals, mitigating the instability common in adversarial methods.
- Experimental results on complex humanoid tasks show NEAR's performance is comparable or superior, achieving robust policy learning measured via dynamic metrics.
Noise-conditioned Energy-based Annealed Rewards (NEAR): A Generative Framework for Imitation Learning from Observation
The paper proposes a novel generative framework for imitation learning from observation using energy-based models. It introduces an algorithm, NEAR, which leverages Noise-conditioned Energy-based Annealed Rewards to learn smooth reward representations derived from expert demonstrations without requiring action labels. This approach circumvents some of the challenges associated with adversarial imitation learning methods by providing stable and continuously defined reward signals. NEAR has been evaluated on various complex tasks and demonstrates comparable efficacy to adversarial techniques.
Introduction to Imitation Learning from Observation
Imitation learning (IL) is an algorithmic approach to skill acquisition by learning from expert demonstrations. One challenging variant of IL is imitation from observation (IfO), where only state trajectories from experts are available, with no accompanying action information. This scenario closely mirrors real-world setups where obtaining action data is cumbersome. IfO demands that the learning agent infer and replicate the dynamics underlying the observed motion trajectories. Traditional behavioral cloning techniques fall short in this context, as they depend on action availability, leaving inverse reinforcement learning as a viable approach.
Noise-Conditioned Score Networks
To address the smoothness and stability challenges of adversarial IL, the paper utilizes score-based generative models, specifically Noise-Conditioned Score Networks (NCSN), which employ denoising score matching to create perturbed versions of data distributions. These models can interpolate between expert data and unexplored regions using noise-conditioned perturbations, enabling well-defined and informative reward signal learning across the entire sample space.
The NCSN approach involves perturbing expert data with Gaussian noise, followed by learning a score function representing the data distribution's gradient. This perturbation ensures the manifold hypothesis — that datasets support lower-dimensional manifolds — does not hinder reward signal generation, providing a complete and smooth energy landscape with continuous gradients.
NEAR Algorithm
The NEAR algorithm combines NCSN-derived energy functions with reinforcement learning to achieve high-quality imitation policies. It dynamically adjusts the reward function via annealing, switching between different smooth energy landscapes based on the agent's progress. Starting with high-variance, exploratory reward landscapes and gradually refining them helps the learning agent consistently receive informative updates and maintain stable learning dynamics.
Implementation Details
- Energy Function Learning: NEAR constructs multiple perturbed expert distributions, learning an energy function for each using denoising score matching. The score function s(x′,σ)=∇x′eθ(x′,σ) approximates these distributions' gradients.
- Annealing Strategy: By adjusting the level of noise used in the energy function, NEAR facilitates smoother transitions in reward landscapes, avoiding abrupt reward changes that may destabilize policy updates.
- Reinforcement Learning: It employs standard RL methods with energy-based reward signals, enhancing consistency and sample quality over traditional min-max optimization approaches.
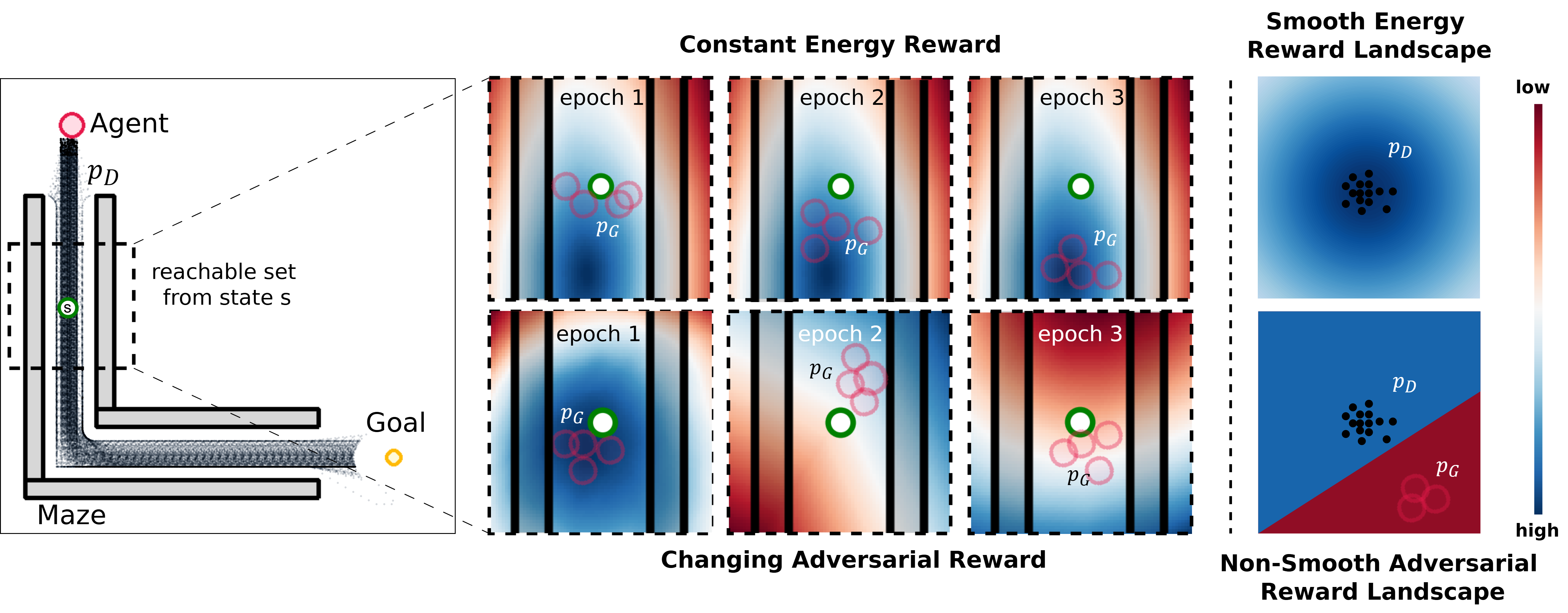
Figure 1: A comparison of reward functions (probability density approximations) learnt in a 2D target-reaching imitation task, demonstrating stable, smooth reward landscapes compared to adversarial methods.

Figure 2: Illustration of performance instability and degradation in policies learnt using adversarial IL, highlighting non-smooth reward landscapes.
Experimental Results
NEAR has been tested on diverse, complex humanoid motion tasks, revealing comparable, often superior, performance compared to state-of-the-art adversarial techniques. Its ability to smoothly converge to high-quality policies while maintaining training stability highlights its efficacy.
Key metrics such as average dynamic time warping error and spectral arc length were used to measure performance, with NEAR exhibiting robust results across various settings, including single-clip and composed task scenarios.
Limitations and Future Work
Although NEAR presents a promising alternative to adversarial IL, it is sensitive to noise-level choices and dataset density, potentially affecting convergence quality. Future improvements may focus on more advanced annealing metrics or hybrid approaches combining task-specific domain knowledge with learned energy functions.
In conclusion, NEAR is a significant step forward in IL, offering a stable, energy-based approach to reward signal generation that enhances policy learning quality and applicability in observation-based imitation scenarios. Its integration of score-based models and dynamic reward adjustment sets a compelling precedent for future developments and refinements in the field.

