- The paper presents the DGN method that leverages a state-conditioned noise distribution to implicitly guide exploration using expert demonstration differences.
- It enhances sample efficiency in sparse reward settings by biasing exploration toward actions proven successful in expert data.
- Empirical evaluations on continuous control benchmarks reveal up to 2-3x performance gains over traditional and imitation-regularized RL methods.
"Reinforcement Learning via Implicit Imitation Guidance"
Introduction
The paper "Reinforcement Learning via Implicit Imitation Guidance" addresses the challenge of sample efficiency in reinforcement learning (RL), particularly in the context of sparse reward signals where prior expert data is available. This study departs from traditional imitation learning (IL) approaches that directly influence the policy via explicit imitation constraints. Instead, the authors propose a novel framework called Data-Guided Noise (DGN) that implicitly introduces expert-guided exploration through a learned noise distribution, thereby enhancing exploration without restricting policy optimization.
Implicit Imitation Through Data-Guided Noise
The primary contribution of the paper is the introduction of DGN, which leverages previous expert demonstrations to guide the exploration phase in RL. Instead of imposing constraints that align the agent's actions closely with those of the experts, DGN learns a state-conditioned noise distribution. This noise, conditioned on the difference between the expert actions and the agent’s current policy, introduces implicit imitation signals that bias the exploration towards actions that have previously led to success.
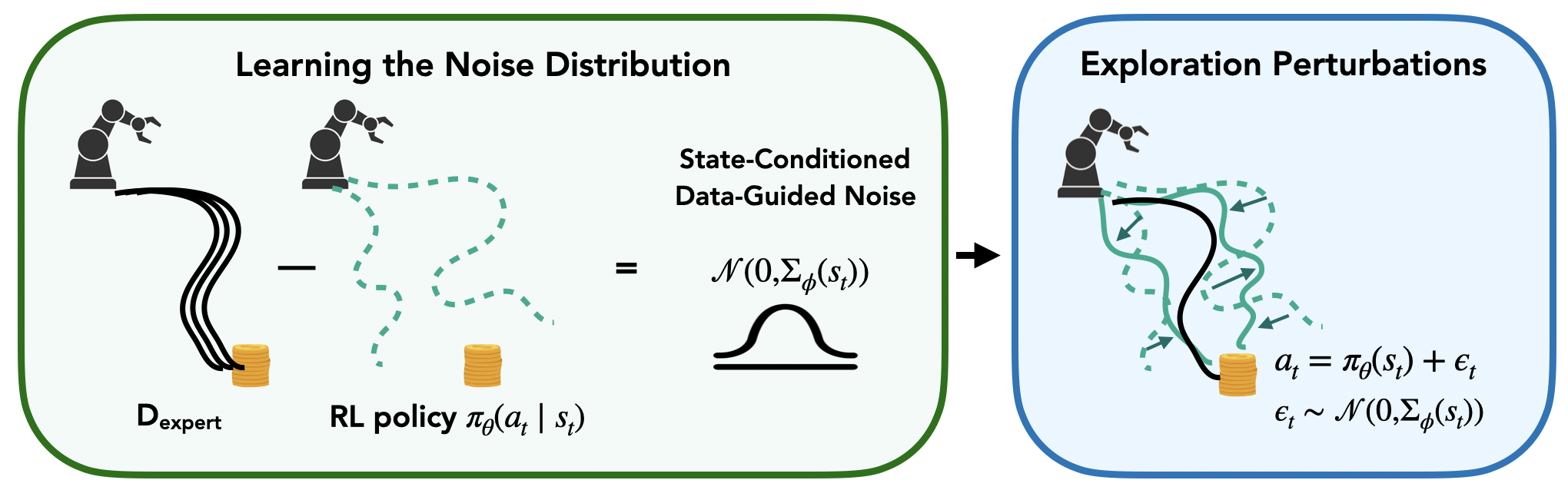
Figure 1: Data-Guided Noise (black). We propose to guide exploration by learning a state-conditioned noise distribution that uses the difference between expert actions and the current RL policy to provide implicit imitation signals for exploration.
DGN is realized by modeling a distribution over action differences between expert data and the agent’s learned policy. By structuring noise as a state-dependent Gaussian, it effectively biases exploration towards promising action regions without constraining the optimization of the policy itself. This framework is adaptable, allowing integration with standard RL or IL-augmented RL pipelines.
Behavioral Analysis and Comparisons
The paper extensively evaluates DGN across multiple continuous control tasks, including those from the Robomimic and Adroit benchmarks, to assess its effectiveness in practice compared to both unconstrained RL and imitation-regularized RL methodologies.
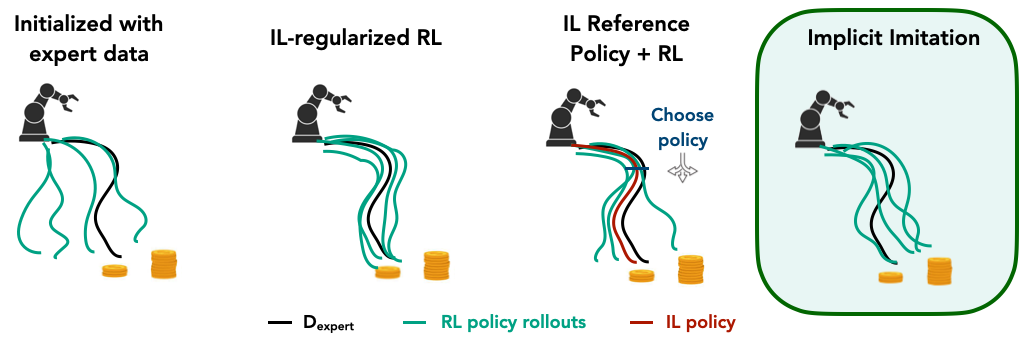
Figure 2: Behavior of Online RL with Expert Data. Instead of using explicit imitation constraints, black implicitly guides exploration by using expert-policy action differences to learn a noise distribution that accelerates the agent's learning.
Results consistently show that DGN outperforms or matches existing state-of-the-art methods, providing significant improvements, particularly in environments where tasks become more challenging. For instance, in complex tasks like tool hanging and relocating objects, DGN exhibits a larger margin of improvement over baseline methods, often achieving 2-3x performance gains.
Furthermore, when compared to methods relying on pre-trained imitation policies, such as Imitation-Bootstrapped RL (IBRL), DGN demonstrates robustness even when the IL policy is weak or derived from multimodal datasets. This occurs because DGN's performance is independent of the quality of the imitation policy, focusing instead on guidance through exploration noise.
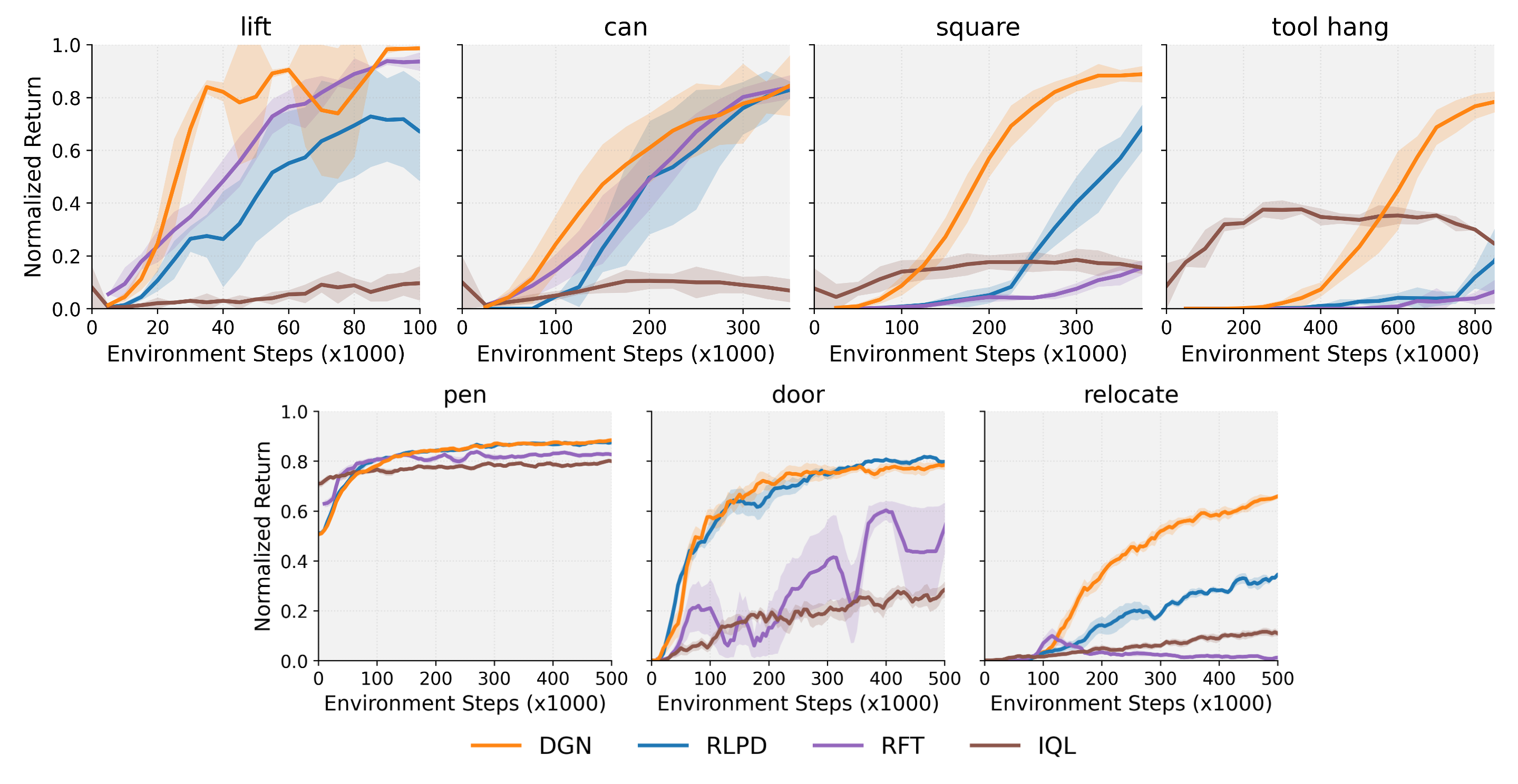
Figure 3: Average Normalized Returns. for Robomimic and Adroit tasks comparing with standard unconstrained RL and imitation-regularized RL methods. Across all tasks, black consistently exceeds or matches the performance of the best baseline—even as the best baseline method varies by task.
Ablation Studies
To validate the components critical to DGN’s success, the authors perform several ablation studies:
- Learning a Full Residual Policy: DGN's default setting, which learns only the covariance matrix, is benchmarked against a variant that learns both mean and covariance. Results indicate that both settings provide similar advantages, underscoring the flexibility and robustness of the strategy.
- State-Conditioning Importance: Removing state-conditioning from the covariance matrix adversely affects performance, demonstrating the critical role of adapting exploration noise to the state dynamics.
- Number of Demonstrations and Network Size: Additional experiments show that performance scales with the number of expert demonstrations and that DGN is surprisingly robust to changes in the network size used for learning the noise distribution.
Conclusion
The paper offers a novel approach to reinforcement learning through implicit imitation guidance, making significant strides in sample efficiency and performance in sparse reward environments. By implicitly guiding exploration through state-dependent data-driven noise, DGN allows agents to efficiently discover reward-maximizing behaviors without explicit behavior cloning constraints. This not only enhances the exploration phase but also allows agents the freedom to uncover more optimal policies autonomously. Future work may explore different modeling choices for the noise distribution and extend the theoretical framework to broader applications and more complex environments.

