Steering Your Diffusion Policy with Latent Space Reinforcement Learning
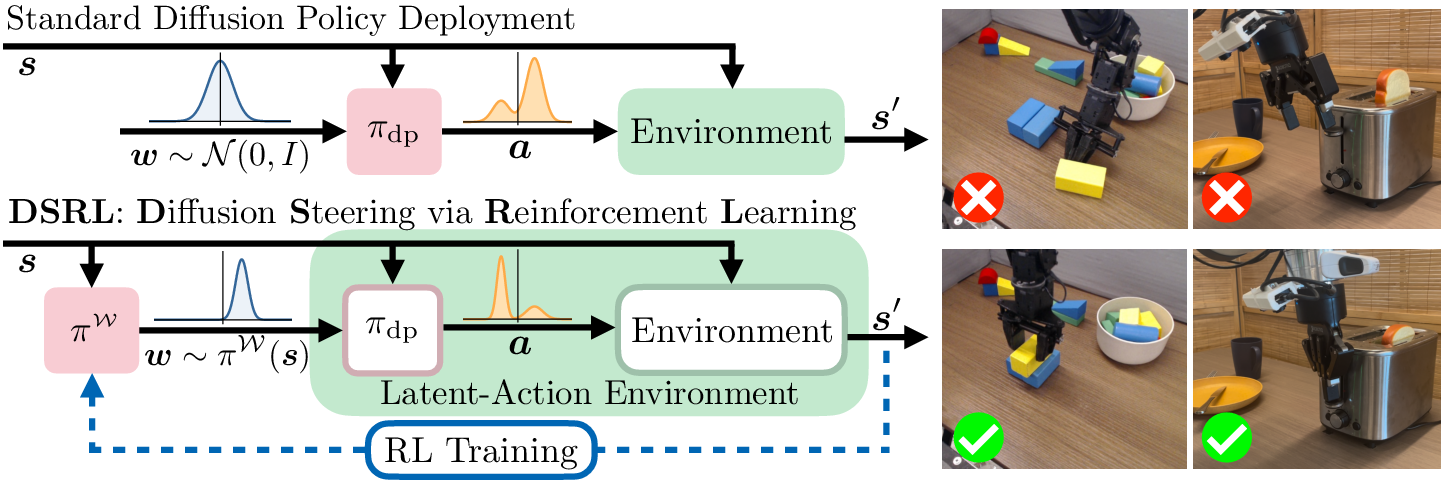
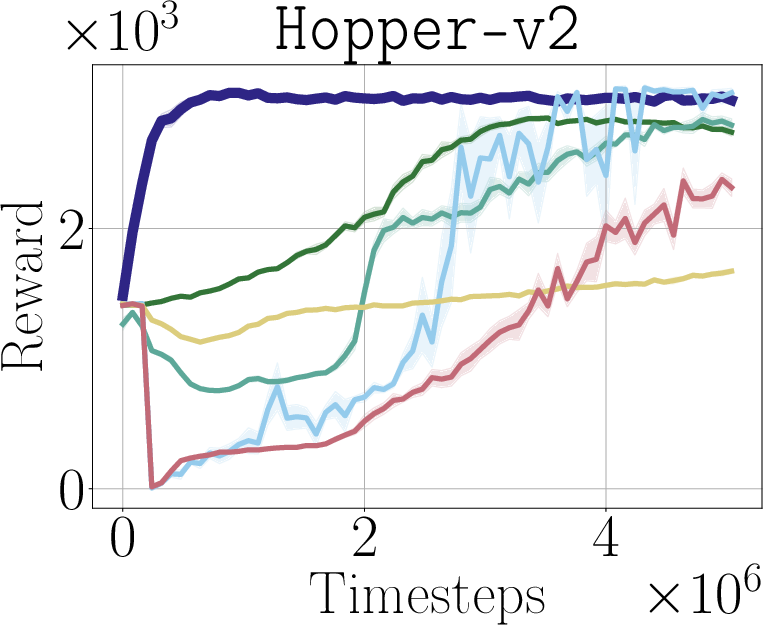
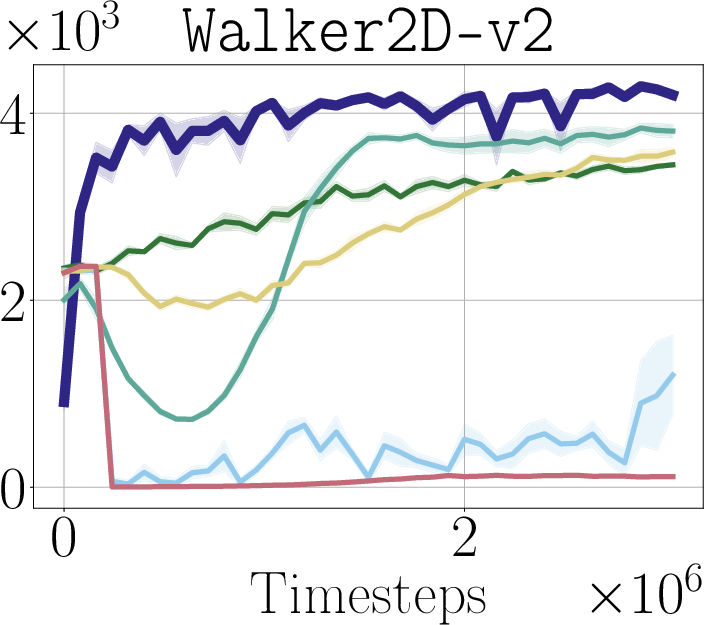
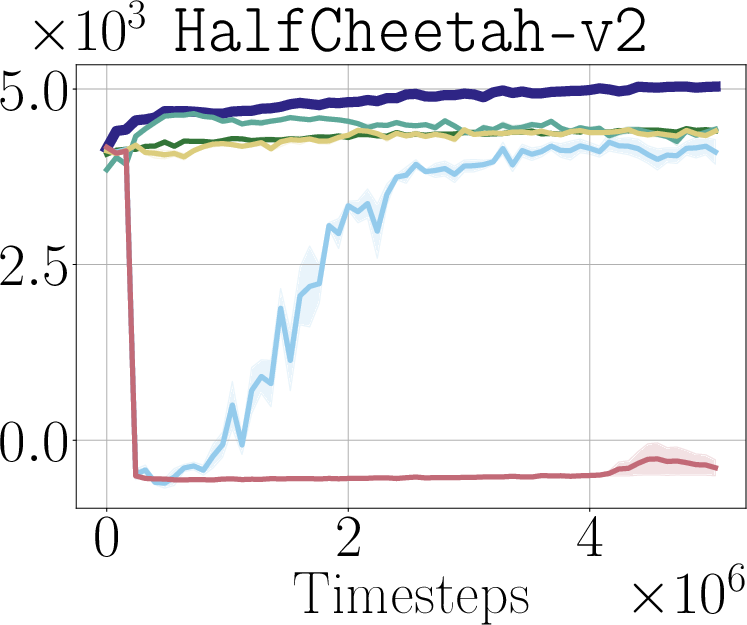
Abstract: Robotic control policies learned from human demonstrations have achieved impressive results in many real-world applications. However, in scenarios where initial performance is not satisfactory, as is often the case in novel open-world settings, such behavioral cloning (BC)-learned policies typically require collecting additional human demonstrations to further improve their behavior -- an expensive and time-consuming process. In contrast, reinforcement learning (RL) holds the promise of enabling autonomous online policy improvement, but often falls short of achieving this due to the large number of samples it typically requires. In this work we take steps towards enabling fast autonomous adaptation of BC-trained policies via efficient real-world RL. Focusing in particular on diffusion policies -- a state-of-the-art BC methodology -- we propose diffusion steering via reinforcement learning (DSRL): adapting the BC policy by running RL over its latent-noise space. We show that DSRL is highly sample efficient, requires only black-box access to the BC policy, and enables effective real-world autonomous policy improvement. Furthermore, DSRL avoids many of the challenges associated with finetuning diffusion policies, obviating the need to modify the weights of the base policy at all. We demonstrate DSRL on simulated benchmarks, real-world robotic tasks, and for adapting pretrained generalist policies, illustrating its sample efficiency and effective performance at real-world policy improvement.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, structured to guide future research.
- Steerability conditions: Formal characterization of when varying the initial noise can reliably steer a diffusion/flow policy to desirable actions. What properties of the denoiser, dataset, or task ensure that the mapping has sufficient coverage of high-value actions?
- Reachability limits: Criteria and diagnostics to detect when optimal or necessary actions are outside the image of for a given state, making Dsrl fundamentally incapable of reaching them without weight finetuning or residuals.
- Deterministic vs. stochastic sampling: Dependence of Dsrl on DDIM/flow (deterministic) sampling. Can Dsrl handle DDPM-style stochastic sampling (non-zero ), or does it require determinism for stability and sample efficiency?
- Sensitivity to diffusion hyperparameters: Systematic study of how denoising schedules, number of reverse steps, guidance weights, and architectural choices affect steerability, stability, and performance.
- Latent dimensionality and action chunking: Effects of the latent-noise dimension (especially for high-dimensional, chunked actions such as in ) on exploration difficulty, credit assignment, and scaling of sample complexity.
- Exploration in latent space: Analysis and methods for efficient exploration in (e.g., structured priors, intrinsic rewards, or optimism) to avoid myopic or mode-collapsed steering when high-reward regions of are rare.
- Noise aliasing theory: Theoretical justification and failure modes of the “noise aliasing” distillation (mapping to via with ). How much bias does this introduce, and how does it affect reaching high-value regions unlikely under ?
- Offline learning conservatism: Formal guarantees (or counterexamples) that Dsrl-Na remains conservative in offline settings. Under what conditions does steering push decoded actions out of the behavior distribution, and how can deviation be controlled (e.g., KL regularization to )?
- Inverse mapping from actions to noise: Methods to find that approximately invert for given offline pairs, potentially enabling stronger use of offline datasets than sampling .
- Safety and constraints: Mechanisms for safe exploration and constraint satisfaction when steering (e.g., action-space safety filters, constrained RL in ), especially in real-world robotics where risky decoded actions are possible.
- API/practical access constraints: Many deployed diffusion/flow policy APIs do not expose the initial noise. What interfaces or wrappers are required to enable Dsrl in practice, and how restrictive is this requirement?
- Compute and latency budget: Quantitative analysis of control-loop latency and compute overhead from denoising and aliasing-based distillation. How many forward passes per control step are needed, and how does this impact high-frequency control?
- Comparative finetuning baselines: Missing head-to-head comparisons with gradient-based finetuning of diffusion/flow policies on real robots, and with strong residual RL baselines under identical conditions and budgets.
- Task interference in generalist policies: When steering a multi-task or generalist policy, does the learned latent policy degrade performance on other tasks or generalization? How to condition or regularize steering to avoid catastrophic interference?
- Reward specification/feedback: The approach relies on sparse binary rewards in experiments; how can Dsrl incorporate preference-based feedback, learned reward models, or language-based rewards to scale to open-world deployment?
- Long-horizon temporal structure: Strategies for coordinating across long horizons and action chunks (e.g., temporal abstractions, sequence-level latent policies, or planning in ). How does temporal correlation of affect stability?
- Robustness and generalization: Sensitivity to observation noise, domain shifts, and sim-to-real gaps. Are Dsrl policies brittle to slight changes in scene layout, dynamics, or camera viewpoints?
- Optimization landscape in : Empirical/analytical study of (non)smoothness and multimodality of and its impact on policy gradient variance, convergence, and stability.
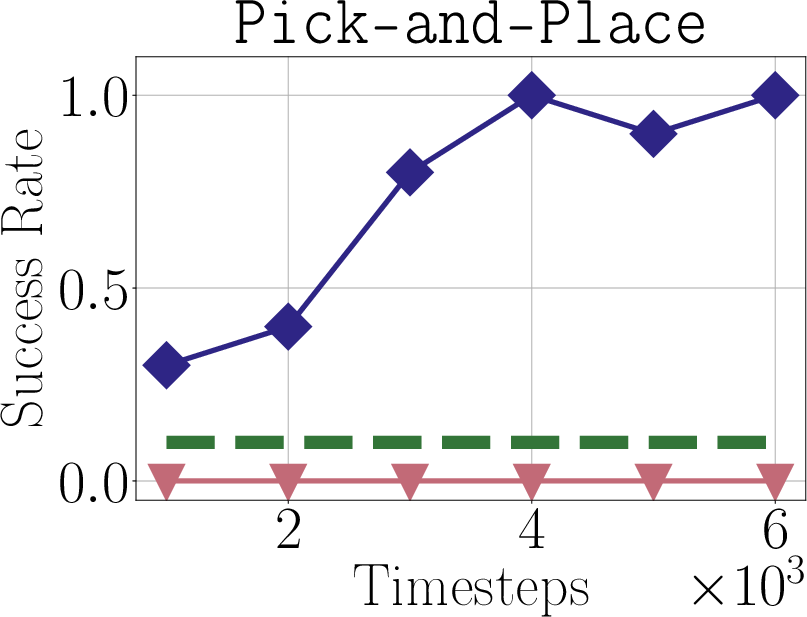
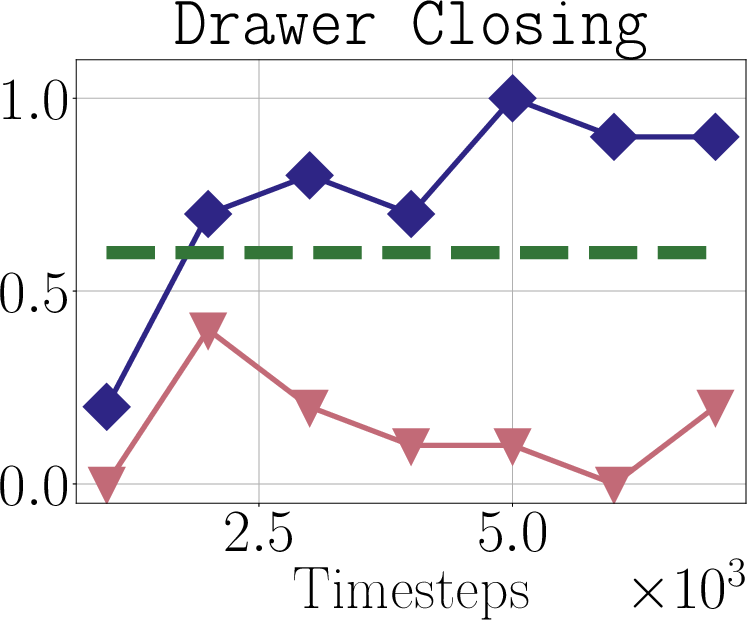
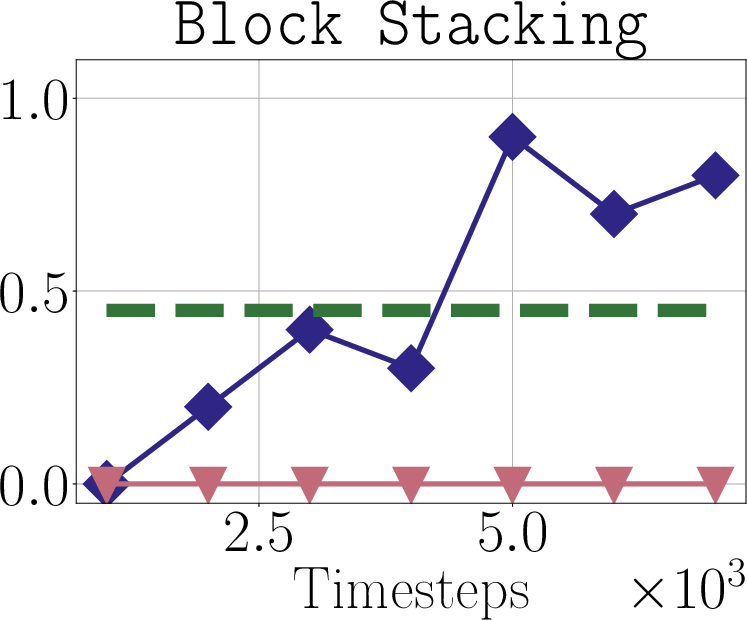
- Offline-to-online transition: Why did standard offline-to-online baselines fail while Dsrl succeeded? Ablations to isolate which Dsrl components (e.g., aliasing, initialization from base rollouts) drive the gains.
- Hybrid methods: Potential benefits of combining steering with small-weight finetuning or residual policies when steerability is insufficient. When and how should Dsrl switch or blend with these alternatives?
- Interpretability and diagnostics: Tools to visualize and diagnose how manipulates the action manifold, detect out-of-support decoding, and monitor safety margins during online adaptation.
- Theoretical sample complexity: Lack of convergence/sample-efficiency analysis for RL in the latent-noise MDP. How does performance scale with , task complexity, and the calibration of ?
- Robustness to denoiser miscalibration: Effects of approximation error in (e.g., under-trained or miscalibrated diffusion/flow policies) on Dsrl performance and reliability, especially when is out-of-distribution relative to demonstrations.
- Deployment considerations: Persistence and portability of learned steering policies across robots, scenes, and firmware updates; memory/compute footprint; and whether steering learned for one task negatively biases future tasks.
Collections
Sign up for free to add this paper to one or more collections.