- The paper identifies fundamental issues in evaluating Text2SQL, emphasizing noisy benchmark data and the limitations of SQL equivalence approximations.
- It highlights specific challenges in input preparation, inference, and output extraction that hinder accurate SQL query generation.
- The study proposes practical mitigation strategies, including improved prompt engineering and enhanced matching functions, to address these evaluation biases.
Challenges in Text2SQL Evaluation
The paper "Fundamental Challenges in Evaluating Text2SQL Solutions and Detecting Their Limitations" identifies significant issues in evaluating Text2SQL tasks, which convert natural language (NL) into structured query language (SQL) queries. The paper emphasizes two main problems: data quality within benchmarks and bias from SQL equivalence approximations. These issues provoke analysis across the Text2SQL pipeline, from input data quality to system limitations and evaluation metrics.
Data Quality and Evaluation Bias
Data Quality Issues
The text-to-SQL benchmarks frequently grapple with data quality issues like noise and ambiguity due to the natural language's probabilistic interpretation. A single input may yield multiple valid SQL queries, a reality existing benchmarks often overlook, contributing to noisy labels and evaluation biases. For example, ambiguity in NL descriptions and information loss during schema serialization create multiple valid SQL interpretations unacknowledged in the evaluation phase (Figure 1).
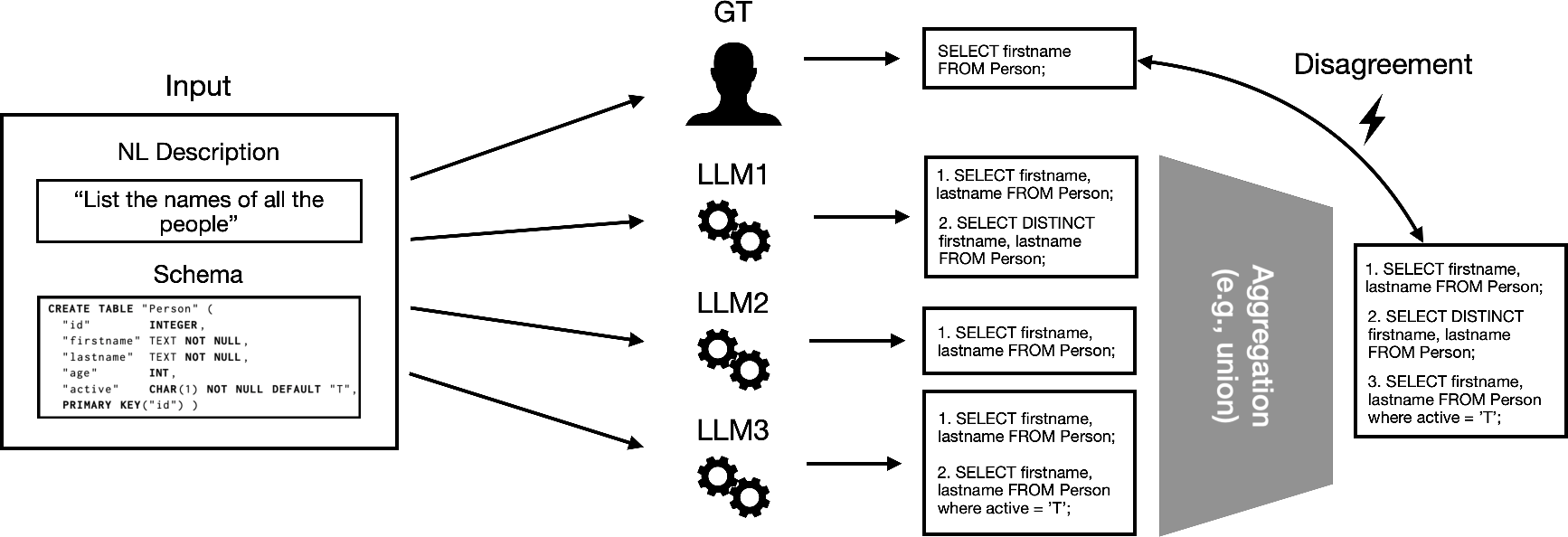
Figure 1: Multiple LLMs indicate SQL query variants for a given input, highlighting data ambiguity in labeling against single benchmark ground truth.
Approximation Bias
Testing SQL equivalence—essential in evaluating Text2SQL success—often requires approximations that introduce bias. Semantic match functions and execution match functions are commonly used, yet they may either narrow or widen the accuracy window improperly. Such variances suggest the need for improved and nuanced match functions that account for execution environment differences and SQL non-determinism.
Taxonomy of Limitations
Developing a taxonomy reveals the intricate matrix of limitations affecting Text2SQL systems:
- Text2SQL Solution Limitations:
- Input Preparation: Challenges here include suboptimal prompts and excluded relevant schema data due to context length constraints.
- Inference: Model mispredictions often require retraining or architecture refinement.
- Output Extraction: SQL extraction failures necessitate robust parsing strategies and possible constrained decoding approaches.
- Evaluation Data Limitations:
- Label Issues: Incomplete ground truth labels and label inaccuracies in benchmark data can lead to unreliable evaluation.
- Incomplete Features: Important schema features may be excluded, complicating correct SQL generation.
- Evaluation Metric Limitations:
- SQL Equivalence Approximation: Both semantic and execution match functions face challenges regarding computational feasibility and logical rigor.
- Ambiguity Relaxation: Fixed, context-agnostic relaxations of match functions can lead to substantial false positive or negative evaluation errors.
Practical Mitigation Strategies
Improvement Approaches
- Prompt Engineering and Retrieval: Effective prompt formulations and schema retrieval can circumvent the limited prompt length by focusing on eliminating irrelevant elements while retaining important context.
- Enhanced Matching and Variation Recognition: Advancements in SQL equivalence testing and acknowledging multiple valid SQL outputs can improve model evaluation processes.
- Constraint Decoding and Input Verifications: Introducing constraint-based decoding and additional verification steps can enhance SQL extraction from model outputs.
Open Challenges
- Automatic Detection and Mitigation: The development of tools for automatic detection and categorization of these issues across datasets and solutions is limited.
- Hyperparameter and Relaxation Impacts: Understanding relaxation impacts on evaluation inaccuracies across varied data distributions remains elusive.
- Balanced Evaluation Metrics: Crafting metrics that accurately reflect Text2SQL performance by accommodating randomness and ambiguity in natural queries is complex.
Conclusion
Text2SQL solutions provide a promising approach for transforming natural language queries into SQL; however, substantial limitations persist that require ongoing exploration and innovation. Addressing these challenges mandates a multifaceted approach—combining automatic detection tools, advancements in prompt engineering, relaxed match functions, and enriched benchmark datasets with multiple valid labels. Future advances must offer systematic methods of evaluating Text2SQL models' capabilities across diverse, real-world and complex datasets. Improved benchmarks capturing true ambiguity and knowledge incorporation into design architectures are essential steps toward achieving robust and reliable Text2SQL systems.