- The paper presents a novel benchmark featuring 4,460 exam-style questions to evaluate advanced medical reasoning across 17 specialties and 11 body systems.
- It employs adaptive Brier scoring, data synthesis, and expert review to ensure robustness and mitigate data leakage.
- Evaluation of 16 leading AI models reveals significant performance gaps in complex diagnostic tasks, guiding future research.
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
The paper "MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding" presents a sophisticated benchmark designed to evaluate expert-level medical reasoning skills across diverse specialties and body systems. Through rigorous examination questions and comprehensive clinical data integration, MedXpertQA sets a new standard in the evaluation of AI capabilities in medical domains.
Overview of MedXpertQA
MedXpertQA introduces a benchmark with 4,460 questions spanning 17 medical specialties and 11 body systems, consisting of two subsets: one for text evaluation and another for multimodal evaluation. The benchmark features exam-level questions enriched with detailed clinical data, distinguishing it significantly from conventional QA benchmarks that utilize basic caption-derived elements. This depth allows for a thorough assessment of advanced medical reasoning and decision-making skills.
MedXpertQA's text and multimodal tasks are crafted to provide a challenging environment for AI models, ensuring that they are tested on complex reasoning and contextual understanding. The benchmark involves data synthesis to reduce potential data leakage and employs expert reviews to ensure the accuracy and reliability of questions.
Benchmark Construction
Figure 1 delineates the design process of MedXpertQA, illustrating its diverse data sources, question attributes, and the comparative analysis with traditional benchmarks.
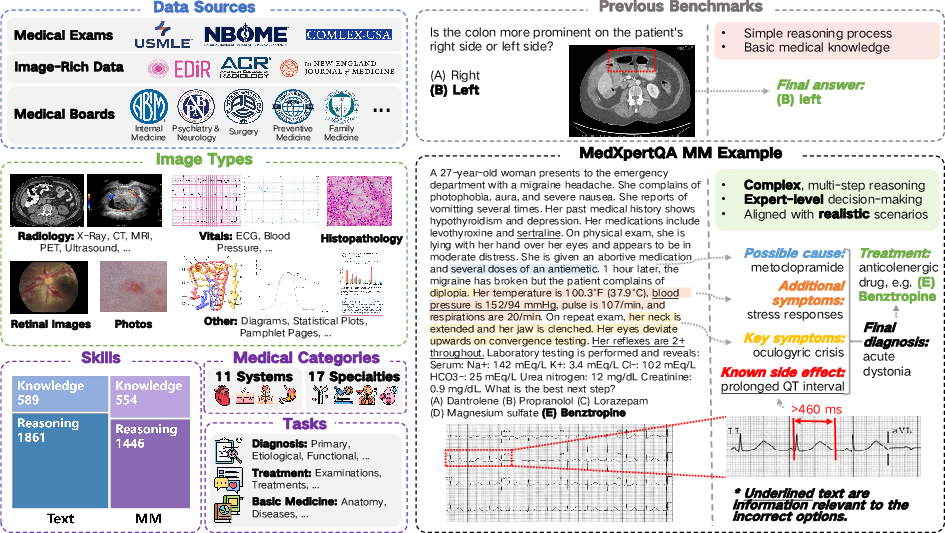
Figure 1: Overview of MedXpertQA construction process, highlighting diverse data sources and question attributes.
MedXpertQA undergoes a rigorous construction process, beginning with data collection from professional medical exams and textbooks. It includes USMLE and COMLEX for broader medical evaluation coverage and specialty board exams for specific diagnostics. The data undergo filtering through adaptive Brier score methodology based on human expert annotations. Additionally, similarity filtering removes repetitive data, ensuring diversity and robustness.
The benchmark further implements question and option augmentation to mitigate data leakage risks. Both the augmented questions and options are reviewed by licensed medical experts to assure quality and accuracy.
Evaluation Results
The evaluation of 16 leading AI models on MedXpertQA shows limited performance, particularly in tasks requiring deep medical reasoning. Figure 2 compares the performance of different models on MedXpertQA against other benchmarks.
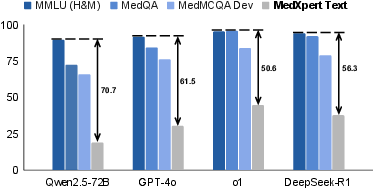
Figure 2: Performance of different models on MedXpertQA, showing limited performance in complex medical reasoning tasks.
Results suggest that current models, including sophisticated Large Multimodal Models (LMMs) and LLMs, struggle with the benchmark’s complex scenarios. The inference-time scaling models show some improvement in reasoning tasks, underscoring the benchmark’s challenge level and its ability to identify areas necessitating further research and improvement.
Implications and Future Directions
MedXpertQA's comprehensive nature underscores its potential in advancing AI research in healthcare applications. By tackling the critical gaps in existing medical benchmarks, it provides a foundational tool for developing AI systems with better diagnostic and reasoning capabilities. Researchers can leverage this benchmark to address shortcomings in model architecture related to medical reasoning.
Future developments may focus on expanding the dataset by including global medical standards and further diversifying the questions to cover more nuanced medical fields. This expansion could provide a broader evaluation spectrum for AI models and contribute to more universally applicable AI applications in medicine.
Conclusion
MedXpertQA introduces a sophisticated, challenging benchmark for medical AI, targeting expert-level reasoning and application of medical knowledge. By incorporating diverse clinical scenarios and rigorous examination constructs, MedXpertQA advances the evaluation of AI capabilities within healthcare contexts, setting a new standard for medical benchmark design.