- The paper demonstrates that current LLMs achieve modest accuracy on complex diagnostic tasks, with models scoring 17.79% to 45.82%.
- The benchmark is built via a rigorous four-stage pipeline, turning clinical case reports into standardized, reasoning-focused evaluations across 28 specialties.
- Results show that converting the task into multiple-choice questions improves performance, highlighting the potential oversimplification of traditional formats.
DiagnosisArena: Benchmarking Diagnostic Reasoning for LLMs
Introduction
The paper "DiagnosisArena: Benchmarking Diagnostic Reasoning for LLMs" (2505.14107) introduces a comprehensive benchmark aimed at evaluating the diagnostic reasoning abilities of LLMs. DiagnosisArena is designed to address the limitations of existing medical benchmarks, which often fail to adequately challenge the reasoning capabilities of LLMs in diagnostic settings. It comprises 1,113 pairs of segmented patient cases and corresponding diagnoses, spanning 28 medical specialties derived from clinical case reports published in top-tier medical journals. The benchmark, constructed through a meticulous pipeline, highlights a significant generalization bottleneck in current LLM capabilities when faced with complex clinical diagnostic reasoning challenges.
Benchmark Construction
DiagnosisArena was developed through a four-stage pipeline which includes data collection, data structuring, iterative filtering, and expert-AI collaborative verification.
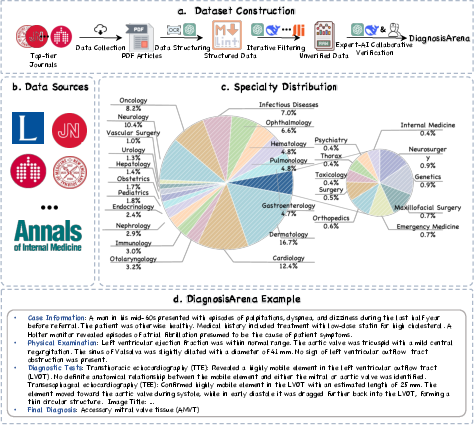
Figure 1: Overview of the DiagnosisArena Benchmark. (a) The pipeline for constructing the DiagnosisArena dataset consists of four stages: data collection from journals, data structuring, iterative filtering of non-reasoning examples, and expert-AI collaborative verification. (b) DiagnosisArena is sourced from 10 top-tier medical journals. (c) It covers 28 medical specialties. (d) DiagnosisArena offers information-dense clinical cases with greater reasoning complexity.
- Data Collection: DiagnosisArena sources its 1,113 clinical cases from case reports published in leading medical journals such as Lancet, NEJM, and JAMA. These journals provide real-world, challenging diagnostic cases with rich contextual information essential for effective AI model evaluation.
- Data Structuring: The raw case reports are transformed into standardized segmented formats, ensuring the inclusion of only diagnostic-relevant content. This process involves rule-based filtering and AI-based structuring, resulting in detailed case information, physical examination findings, diagnostic test results, and ground truth final diagnoses.
- Iterative Filtering and Expert-AI Collaborative Verification: Cases are screened to ensure complexity and logical consistency, involving both AI and human reviewers. The benchmark excludes cases whose diagnoses can be easily inferred from memorized facts or lack sufficient diagnostic complexity.
Experimental Results
The experimental analysis in the paper demonstrates that current SOTA reasoning models, such as o3-mini, o1, and DeepSeek-R1, struggle significantly on DiagnosisArena, achieving modest accuracy rates of 45.82\%, 31.09\%, and 17.79\% respectively. These results underscore the difficulties faced by LLMs in handling the intricacies of clinical reasoning.
Figure 2: Performance of SOTA models on DiagnosisArena and other benchmarks.
Additionally, converting the diagnostic task into multiple-choice questions revealed marked performance improvements, highlighting a potential oversimplification in traditional benchmark formats. For instance, in the multiple-choice setting, o1 reached 61.90\% accuracy, showcasing the potential reduction in task difficulty when constraining the answer space.
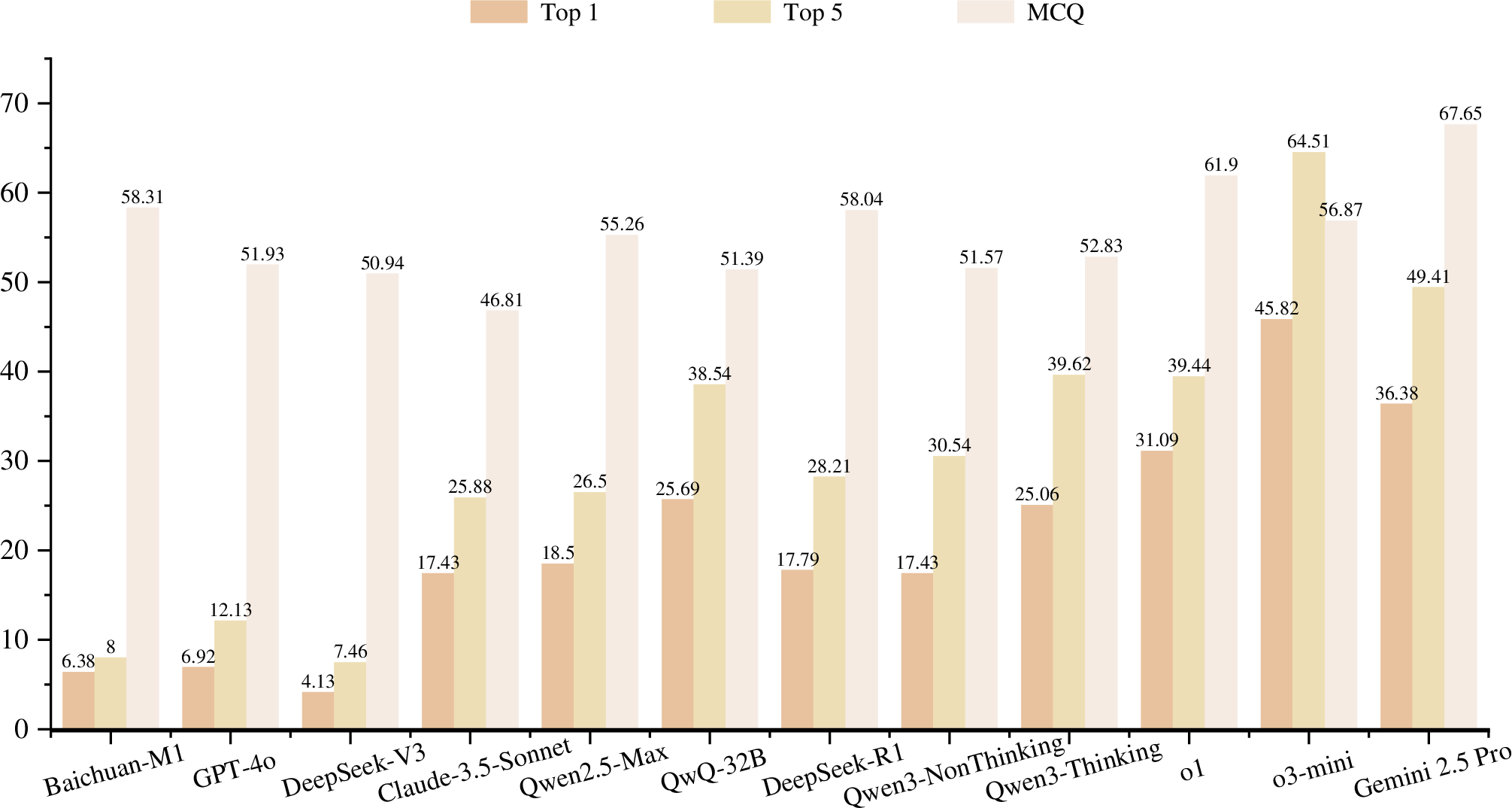
Figure 3: Performance of Different Models on DiagnosisArena. (a) The Top-k metric represents the proportion of cases where the correct answer is included among the Top-k predictions, ranked in descending order of confidence. (b) The MCQ presents the multiple-choice version of DiagnosisArena, with o1 reaching 61.90\% accuracy.
Data Leakage Study
The paper explores potential data leakage by analyzing model performance against case publication dates, ensuring robustness in evaluation results. The study concludes that data leakage is rare and does not negatively impact model assessment accuracy.
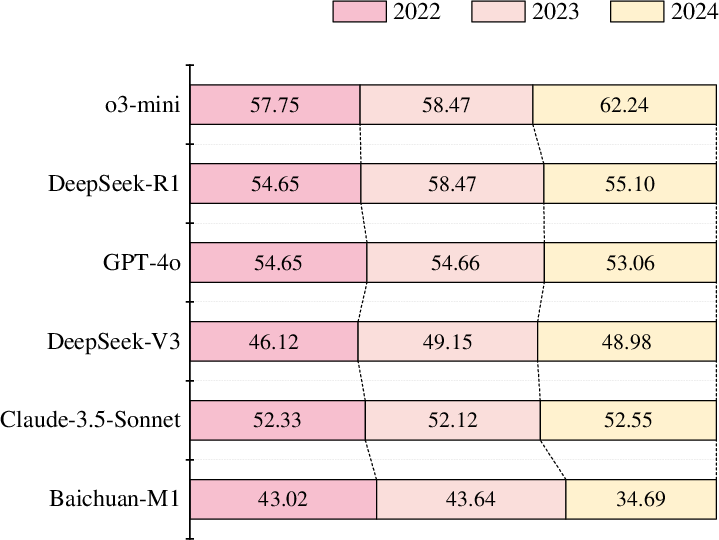
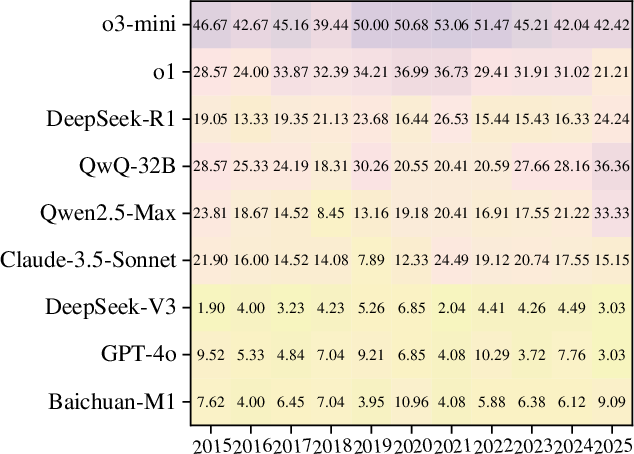
Figure 4: Leakage Detection on DiagnosisArena.
Case Study
Analyzing a specific case from DiagnosisArena reveals the diagnostic challenges LLMs face. For example, DeepSeek-R1 misinterpreted critical diagnostic features due to over-reliance on reasoning paths of common diseases, underscoring the limited adaptation of current models to complex medical reasoning requirements.

Figure 5: A Case Study of DiagnosisArena. Except for o3-mini, which provided the correct answer, other models missed the correct diagnosis.
Conclusion
DiagnosisArena serves as a pivotal step toward refining diagnostic reasoning capabilities of LLMs in clinical settings. By presenting a rigorous benchmark, it reveals current limitations and directs future research towards enhancing reasoning abilities to support complex medical diagnostics effectively. This benchmark aims to drive further advancements in AI’s diagnostic proficiency, ultimately contributing to safer and more effective integration of AI systems into real-world healthcare environments.