- The paper reveals that convex optimization theory predicts optimal learning-rate schedules, mirroring empirical loss trajectories.
- It shows that both cosine and warmup-stable-decay schedules achieve similar performance with fewer tuning parameters for the latter.
- The findings indicate that transferring the optimal learning rate across schedules can significantly accelerate large language model training.
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
Introduction
This essay explores the research presented in "The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training," which investigates the alignment between convex optimization theory and empirical learning-rate schedules in large-scale model training. The study focuses specifically on the comparison between cosine and the warmup-stable-decay (wsd) schedules, widely used in LLM training, and explores how insights from non-smooth convex optimization can guide practical learning-rate tuning.
Convex Optimization and Learning-Rate Schedules
Recent advancements in learning-rate (LR) scheduling have primarily emerged from empirical practices rather than theoretical underpinnings. This paper asserts that non-smooth convex optimization theory provides a framework that closely mirrors these empirical observations. Specifically, it highlights the absence of logarithmic terms in the theoretical convergence bound under a constant schedule with a linear cooldown, compared to the cosine schedule.
The paper posits that transferring the optimal learning-rate across different schedules results in noticeable efficiency improvements and performance gains for models such as Llama, leading to more resource-efficient training pipelines.
Theoretical vs. Empirical Alignments
The study arrives at its conclusions by simulating bounds on suboptimality for convex problems, demonstrating that these theoretical results mirror empirical findings closely. Of particular note is that both the cosine and wsd schedules perform similarly, but with wsd requiring less parameter tuning due to its cooldown period. This is evidenced by the striking similarity between real loss curves and theoretical suboptimality bounds, asserting the practical applicability of these theoretical insights.
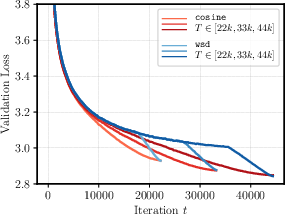
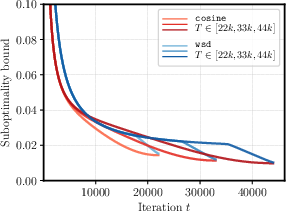
Figure 1: Real Loss Curves
Schedule Design and Optimization
The wsd schedule, particularly its cooldown phase, results in a significant improvement over constant schedules by eliminating logarithmic terms from the convergent bound. The paper presents a rigorous examination of its theoretical convergence results—without warmup—in the non-smooth convex setting, suggesting practitioners consider extended schedules and optimal base learning-rate transfer to benefit model training effectively.
Additionally, the analysis of cooldown fraction shows that extending the cooldown period is beneficial when using the optimal base learning-rate, signifying that crafting the schedule requires meticulous tuning.
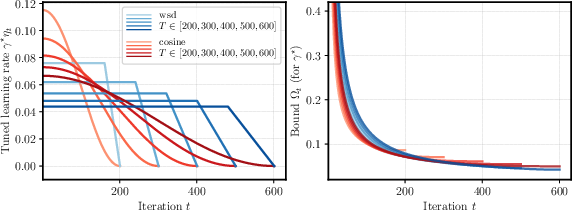
Figure 2: Schedule (left) and theoretical bound (right) for cosine and wsd.
Implications and Practical Applications
The research offers practical applications in continued training scenarios by constructing learning-rate schedules that adapt optimally when extending training steps. By leveraging theoretically optimal schedules, practitioners can conduct training more efficiently and effectively. Furthermore, the paper extends its empirical insights to theoretical grounds, showing that wsd's design aligns with convex optimization theory, thus providing theoretical underpinnings to an empirically derived practice.
In addition to establishing a theoretical basis, this work emphasizes the importance of understanding gradient norms and their constancy, which directly influence the sudden drop in the suboptimality seen in practice.
Conclusion
In conclusion, the convergence of non-smooth convex optimization theory with empirical learning-rate scheduling provides a robust foundation for refining LLM training protocols. This alignment allows practitioners to design and implement efficient LR schedules, enhancing large model training performance effectively. Future work could explore extending these theoretical insights to more complex, non-convex scenarios, further solidifying the link between robust theoretical frameworks and practical machine learning implementations.