- The paper introduces a Multi-Power Law framework that accurately predicts the entire loss curve of LLM pretraining using cumulative learning rate sums and a power-law decay term.
- It employs a novel empirical approach that outperforms existing methods like the Chinchilla and Momentum Laws through effective schedule-aware loss prediction.
- Optimized learning rate schedules derived from MPL demonstrate improved training efficiency and stability across various model sizes and non-monotonic scheduling scenarios.
Multi-Power Law for Loss Curve Prediction Across Learning Rate Schedules
Motivation and Problem Statement
The paper introduces the Multi-Power Law (MPL), an empirical scaling law for predicting the entire pretraining loss curve of LLMs under arbitrary learning rate (LR) schedules. Existing scaling laws, such as the Chinchilla law, model final loss as a function of model size and training steps, but do not account for the LR schedule, which is a critical hyperparameter for optimization efficiency and stability. The MPL addresses the schedule-aware loss curve prediction problem: given a sequence of learning rates E={η1,η2,…,ηT}, can one accurately predict the training loss %%%%1%%%% at every step?
The MPL is derived through a bottom-up empirical approach, starting from constant LR schedules, then analyzing two-stage and multi-stage decaying schedules, and finally generalizing to arbitrary monotonic and non-monotonic schedules. The law is formulated as:
L(t)=L0+A⋅(S1(t)+SW)−α−LD(t)
where S1(t)=∑τ=1tητ is the cumulative LR sum post-warmup, SW is the warmup LR sum, and LD(t) is a loss reduction term capturing the effect of LR decay:
LD(t)=Bk=1∑t(ηk−1−ηk)⋅G(ηk−γSk(t)),Sk(t)=τ=k∑tητ
with G(x)=1−(Cx+1)−β, and L0,A,B,C,α,β,γ are fit from a small number of training runs.
The first two terms generalize the Chinchilla law by replacing the number of steps with the cumulative LR sum, while the LD(t) term models the additional loss reduction from LR decay, empirically shown to follow a power law rather than an exponential form.
Empirical Validation
Extensive experiments validate the MPL across Llama-2, GPT-2, and OLMo architectures, with model sizes from 25M to 1B parameters and training horizons up to 72,000 steps. The law is fit using only two or three schedule-loss curve pairs and generalizes to unseen schedules, longer horizons, and non-monotonic schedules (e.g., cyclic, random-polyline).
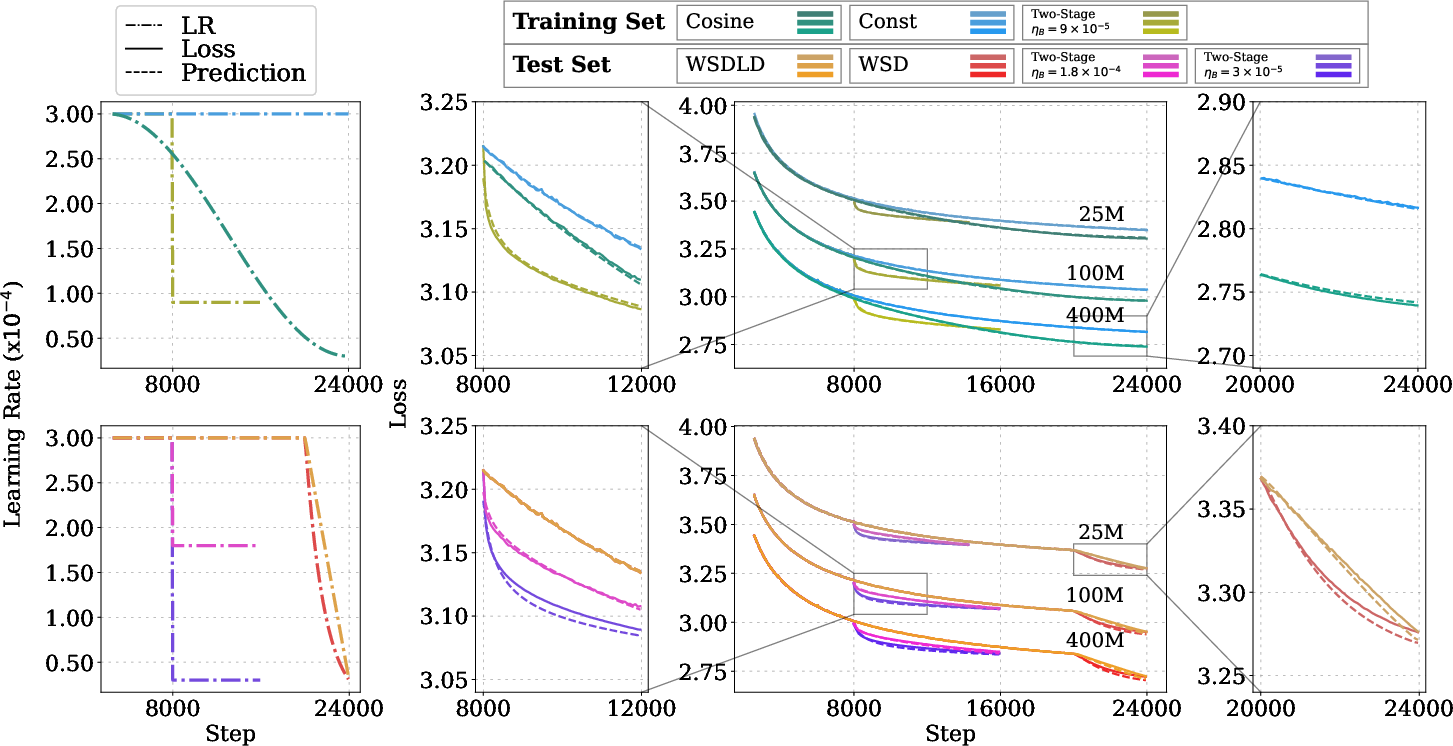
Figure 1: MPL achieves higher R2 and lower error metrics than the Momentum Law across 25M, 100M, and 400M models for unseen schedules.
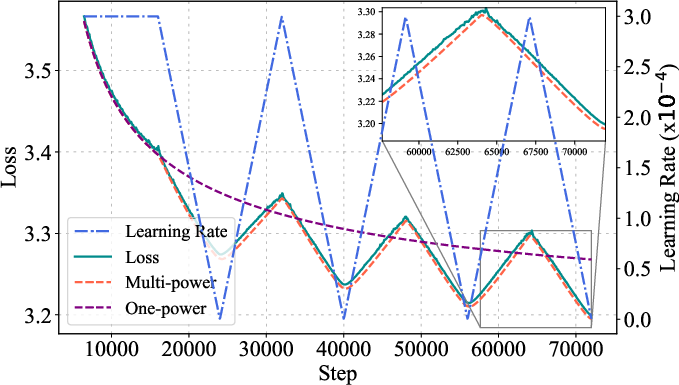
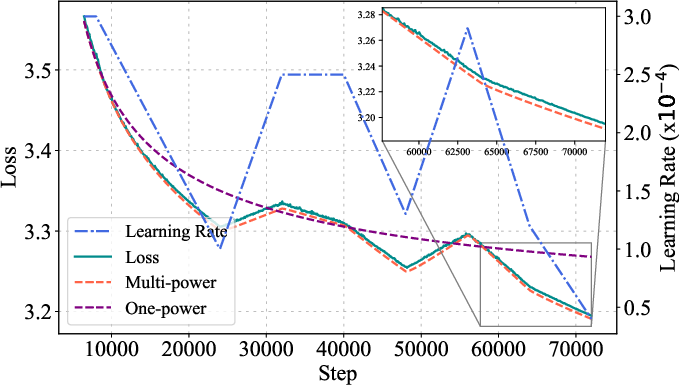
Figure 2: MPL accurately predicts loss curves for long-horizon cyclic and random-polyline schedules, demonstrating generalization to non-monotonic LR schedules.
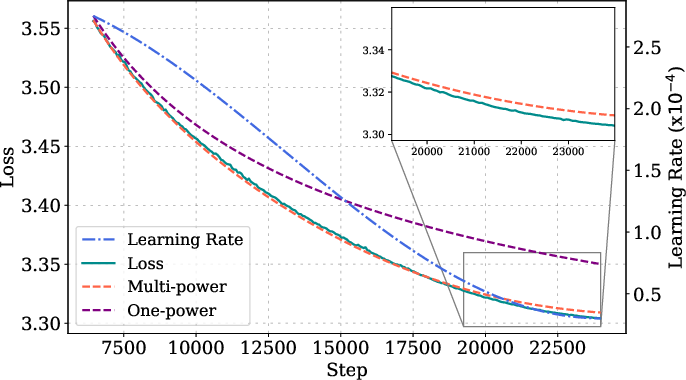
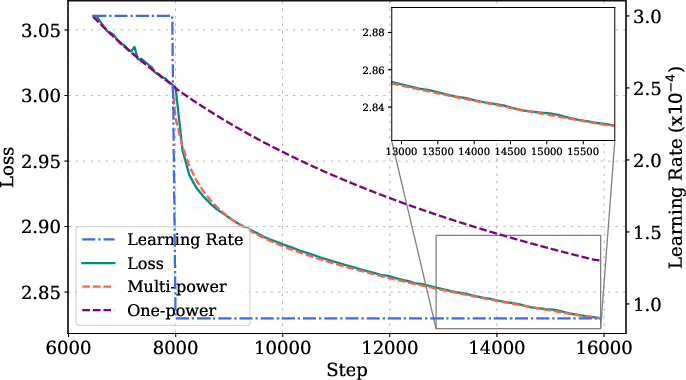
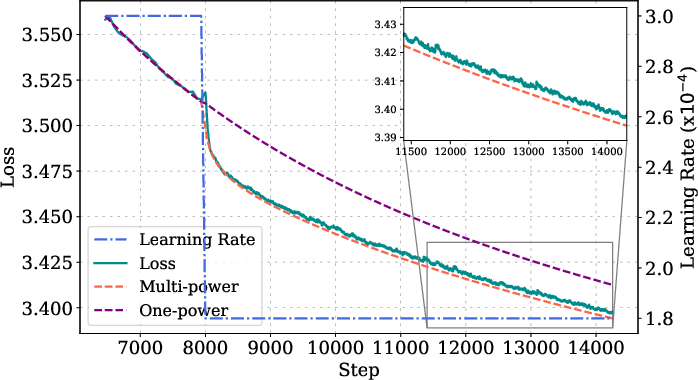
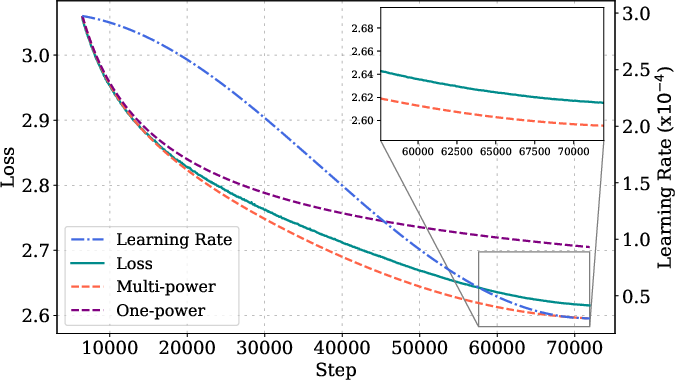
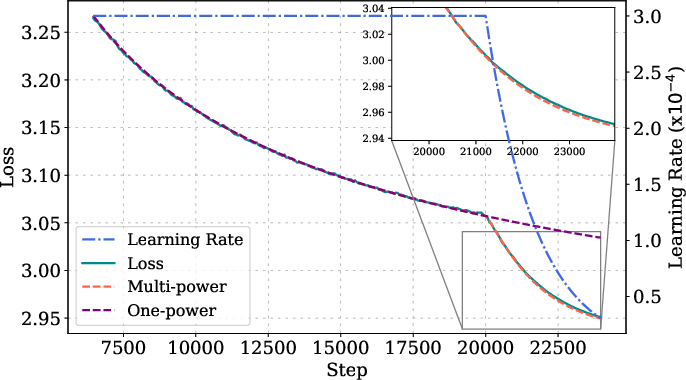
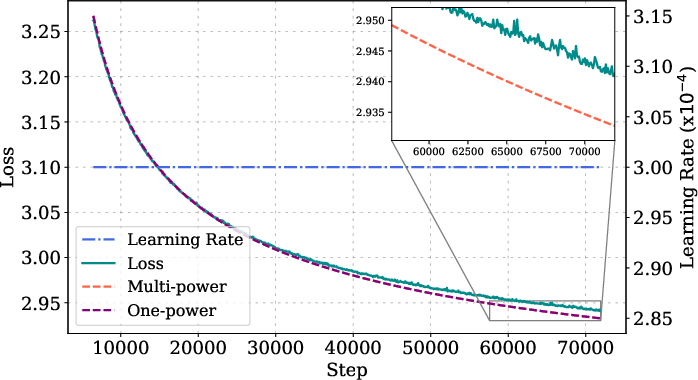
Figure 3: MPL fitting and prediction details for various model sizes, step lengths, and LR schedules, showing high accuracy across configurations.
Ablation studies show that omitting the LD(t) term or replacing the power law with an exponential form degrades prediction accuracy. The law is robust to changes in peak LR, batch size, and random seed, with prediction errors approaching the lower bound set by seed variability.
Theoretical Analysis
A theoretical justification is provided for quadratic loss functions with power-law spectra in the Hessian and noise covariance. Under these assumptions, the expected loss curve of SGD with arbitrary LR schedule matches the MPL form, with the loss reduction term saturating as a power law in the scaled LR sum. The analysis highlights the connection between spectral properties of the optimization landscape and the empirical scaling law, though the explicit dependence on ηk in practice is not fully captured by the quadratic theory.
Schedule Optimization and Practical Implications
By minimizing the predicted final loss under the MPL, the authors optimize the LR schedule via gradient-based methods, subject to monotonicity constraints. The resulting schedules consistently outperform cosine and WSD schedules, both in final loss and downstream task performance.
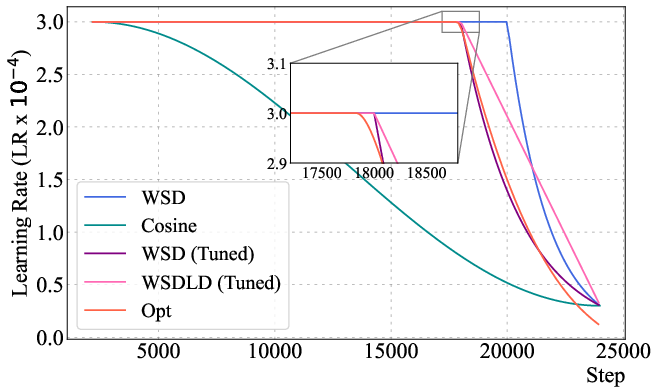
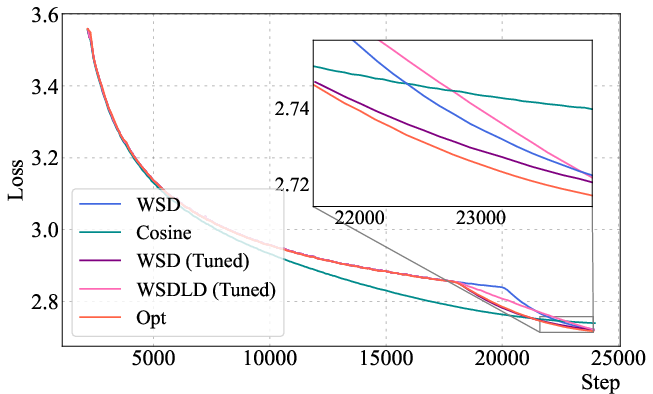
Figure 4: The optimized LR schedule (Opt) outperforms cosine and WSD schedules for a 400M Llama-2 model, with a stable phase followed by a power-law decay.
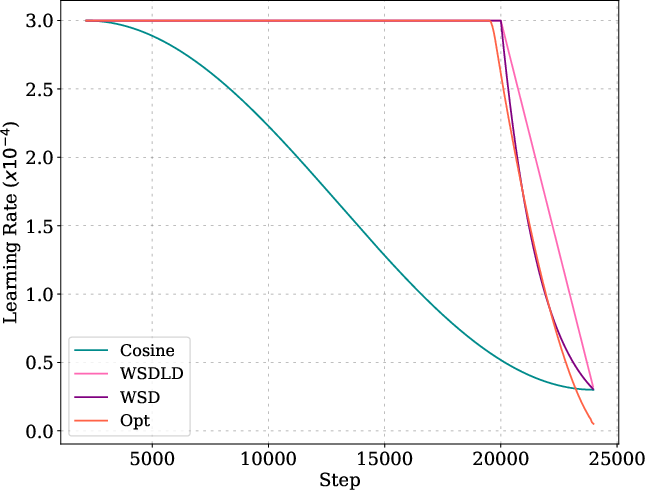
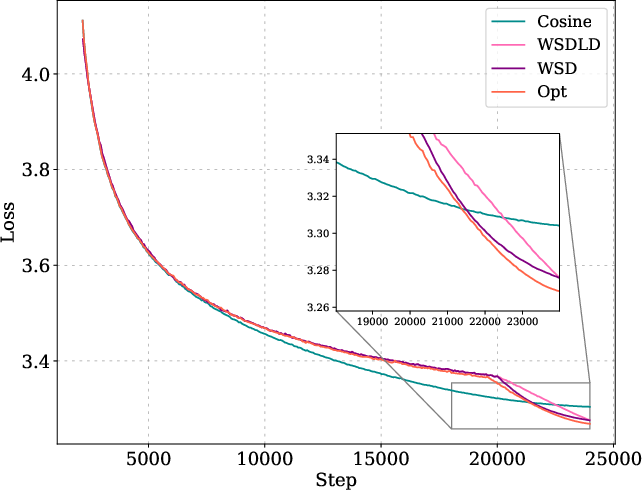
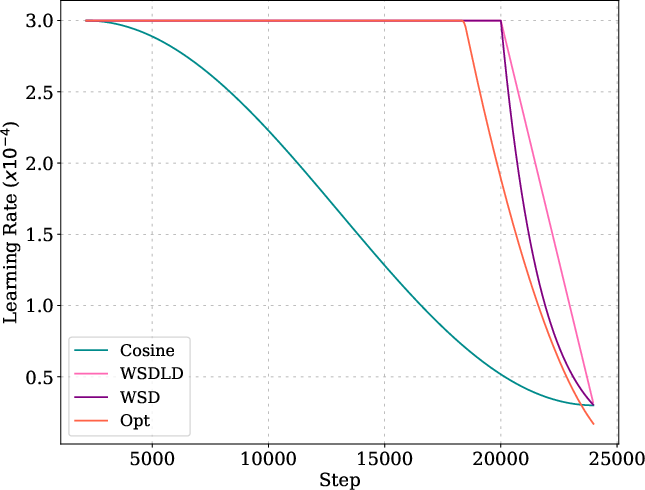
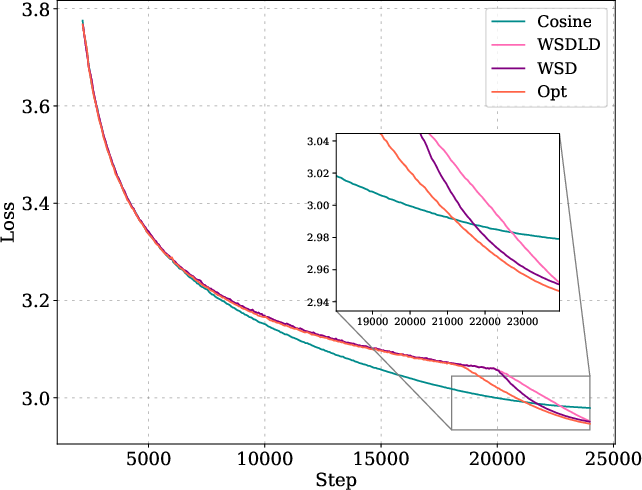
Figure 5: Optimized schedules and their loss curves compared to cosine, WSD, and WSDLD schedules for 25M and 100M models.
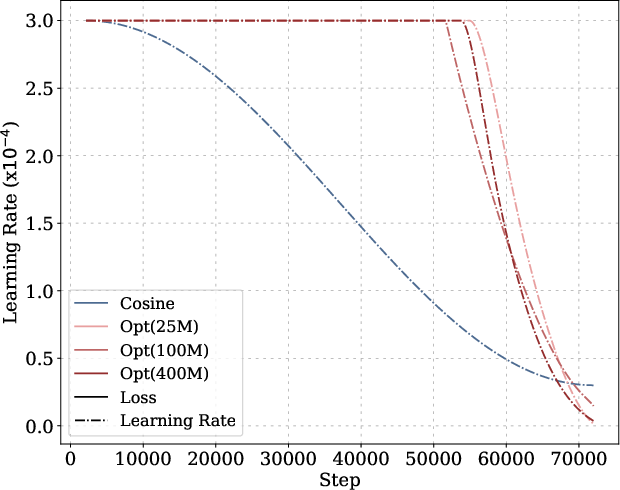
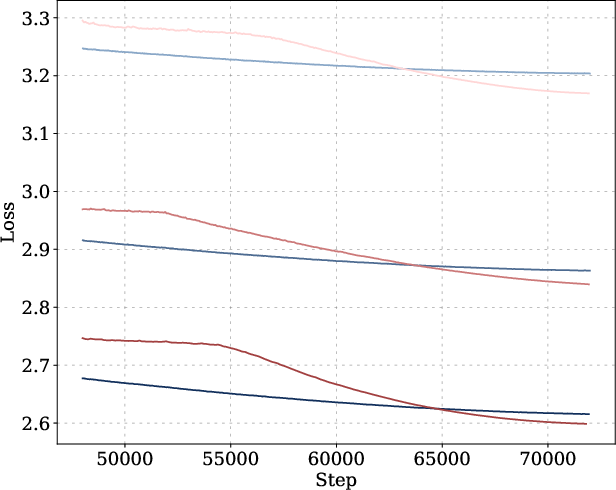
Figure 6: Optimized and cosine LR schedules and corresponding loss curves for long-horizon training across model sizes.
The optimized schedules exhibit a Warmup-Stable-Decay (WSD) pattern, but with a decay phase following a power law rather than linear or exponential decay. The optimized schedules decay to near-zero LR, outperforming WSD variants even when their ending LR is tuned to zero.
Comparison to Baselines
MPL outperforms the Chinchilla law and the Momentum Law (MTL) in both sample efficiency and prediction accuracy. While Chinchilla requires multiple full training runs for fitting, MPL achieves superior accuracy with only a few curves. MTL, which models loss reduction as an exponential function of LR reduction, provably yields suboptimal collapsed schedules and fails to match the empirical power-law behavior observed in loss reduction.
Implications and Future Directions
The MPL provides a practical tool for schedule-aware loss curve prediction, enabling efficient hyperparameter tuning and schedule optimization for LLM pretraining. Its empirical accuracy and theoretical grounding suggest that power-law relationships govern not only model/data scaling but also the dynamics induced by LR schedules. The law's ability to generalize to arbitrary schedules and long horizons is particularly relevant for compute-constrained training and continual learning scenarios.
Future work should refine the theoretical analysis to account for non-quadratic loss landscapes and further investigate the dependence of MPL parameters on other hyperparameters. Extending MPL to capture the effects of adaptive optimizers, data mixing, and transfer learning remains an open challenge.
Conclusion
The Multi-Power Law establishes a robust, empirically validated framework for predicting the entire loss curve of LLM pretraining under arbitrary LR schedules. It enables efficient schedule optimization, surpasses existing scaling laws in accuracy and sample efficiency, and provides new insights into the interplay between optimization dynamics and hyperparameter schedules. The approach is extensible to diverse architectures and training regimes, with significant implications for both theoretical understanding and practical deployment of large-scale models.