Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging
Published 3 Feb 2026 in cs.LG, cs.AI, math.OC, and stat.ML | (2602.03702v1)
Abstract: LLMs are increasingly trained in continual or open-ended settings, where the total training horizon is not known in advance. Despite this, most existing pretraining recipes are not anytime: they rely on horizon-dependent learning rate schedules and extensive tuning under a fixed compute budget. In this work, we provide a theoretical analysis demonstrating the existence of anytime learning schedules for overparameterized linear regression, and we highlight the central role of weight averaging - also known as model merging - in achieving the minimax convergence rates of stochastic gradient descent. We show that these anytime schedules polynomially decay with time, with the decay rate determined by the source and capacity conditions of the problem. Empirically, we evaluate 150M and 300M parameter LLMs trained at 1-32x Chinchilla scale, comparing constant learning rates with weight averaging and $1/\sqrt{t}$ schedules with weight averaging against a well-tuned cosine schedule. Across the full training range, the anytime schedules achieve comparable final loss to cosine decay. Taken together, our results suggest that weight averaging combined with simple, horizon-free step sizes offers a practical and effective anytime alternative to cosine learning rate schedules for LLM pretraining.
The paper demonstrates that horizon-free learning-rate schedules paired with weight averaging can achieve minimax-optimal convergence similar to tuned cosine decay.
It offers a comprehensive theoretical analysis supported by empirical evidence using OLMo transformer models over various compute budgets.
Empirical results reveal that constant or 1/√t decay rates with averaging closely track the cosine envelope, enhancing continual LLM pretraining efficiency.
Horizon-Free Optimization in Large-Scale Pretraining: An Expert Review of "Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging" (2602.03702)
Motivation and Context
Standard pretraining of LLMs relies heavily on well-tuned, horizon-dependent learning rate (LR) schedules such as cosine decay. This dependence creates inefficiencies in continual or open-ended training where the total number of optimization steps cannot be specified upfront—a scenario increasingly relevant in modern LLM development pipelines. The examined paper investigates whether horizon-free (anytime) LR schedules combined with weight averaging are empirically and theoretically competitive with the typical horizon-coupled schedules, specifically focusing on stochastic gradient descent (SGD) for both overparameterized linear regression and large-scale LLMs.
Theoretical Foundation and Main Results
The authors present a detailed theoretical analysis of stochastic optimization with polynomially decaying LR schedules of the form ηt=1/tγ(0<γ<1), equipped with tail weight averaging. Their key theoretical result establishes that for SGD in overparameterized linear regression (with power-law spectra in the data covariance), such horizon-free schedules attain convergence rates comparable to those of horizon-tuned schedules—even in the absence of pre-specified training duration. The optimal schedule exponent γ∗ depends directly on the source and capacity exponents characterizing the covariance's spectral decay: specifically, γ∗=max{1−a/b,0}, where a and b govern the decay of feature and signal directions, respectively.
This extends and unifies earlier work on linear and nonlinear decay schemes, and rigorously clarifies under what spectral conditions constant or polynomially decaying LR schedules—paired with iterate-averaging—can be minimax-optimal and horizon-free. Notably, under certain regimes (e.g., b≤a), constant LR with averaging is strictly anytime optimal, while for other regimes, a decaying schedule is required for minimaxity.
Empirical Evaluation: LLM Pretraining Experiments
Central to the empirical contribution are comprehensive ablations on OLMo-based transformer models of 150M and 300M parameters, pretrained on the C4 dataset under various LR schedules:
Horizon-dependent Cosine Decay: Tuned for each training budget using separate runs.
Horizon-independent ("Anytime") Schedules: Constant LR with averaging, 1/t schedule with averaging, and the Warmup-Stable-Decay (WSD) schedule.
Performance is reported across compute budgets spanning 1×–32× Chinchilla scaling, with each "anytime" schedule realized in a single run and evaluated at intermediate checkpoints—contrasted against individually tuned cosine runs at every horizon.
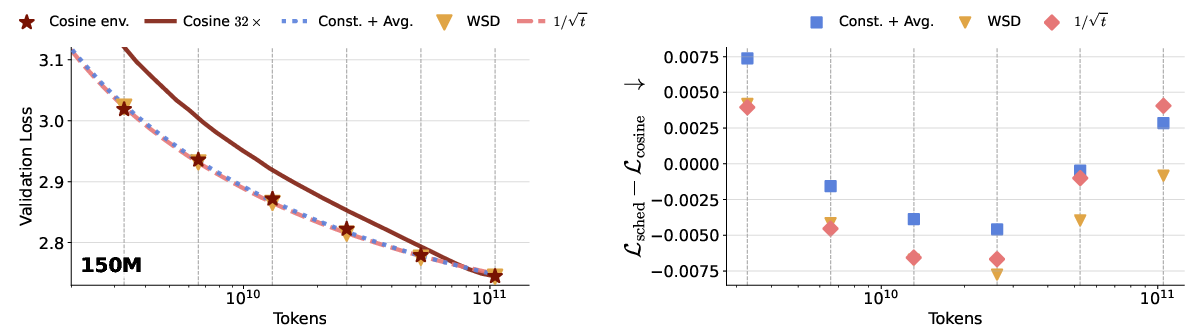
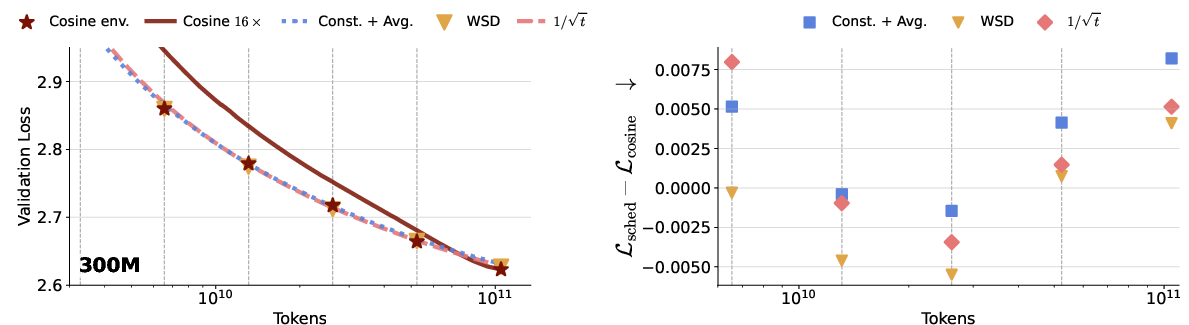
Empirical findings show that both constant LR with tail averaging and 1/t-type schedules can closely track the "cosine envelope": their validation loss trajectories at all horizons are essentially indistinguishable from the optimally tuned horizon-aware cosine runs, with negligible degradation except for endpoints and early phases. The WSD schedule also performs competitively, although it is only "almost-anytime" due to its dependence on checkpointed information for decay transitions.
Figure 1: Validation loss and compute tradeoff for 150M and 300M parameter models under cosine decay, constant LR with averaging, WSD, and 1/t-type anytime schedules.
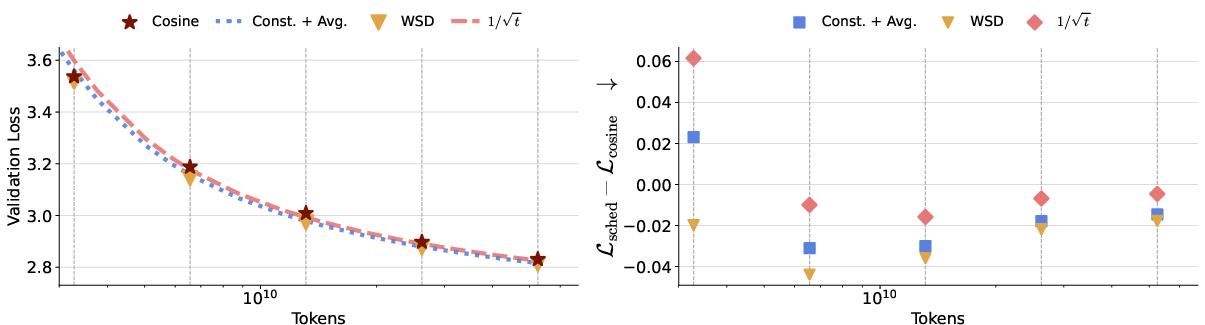
Moreover, experiments at extremely large batch sizes (well above the critical batch size threshold) highlight a regime where LR decay becomes less beneficial—here, constant LR with averaging outperforms cosine across long horizons, confirming theoretical expectations derived from SGD noise suppression via batching.
Figure 2: Loss comparison for 150M models with batch size 4096—constant LR with averaging outperforms cosine decay at longer horizons.
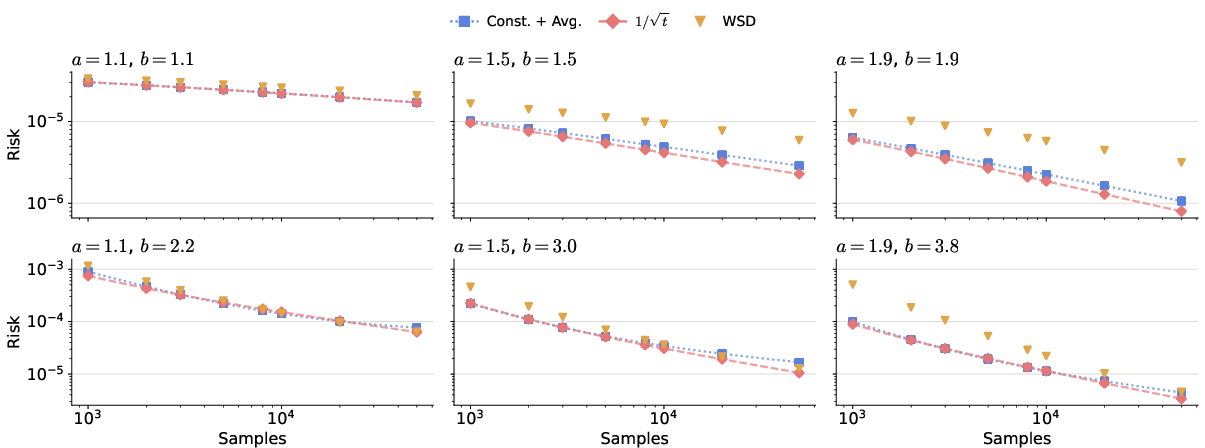
Theoretical Risk Analysis and Synthetic Validation
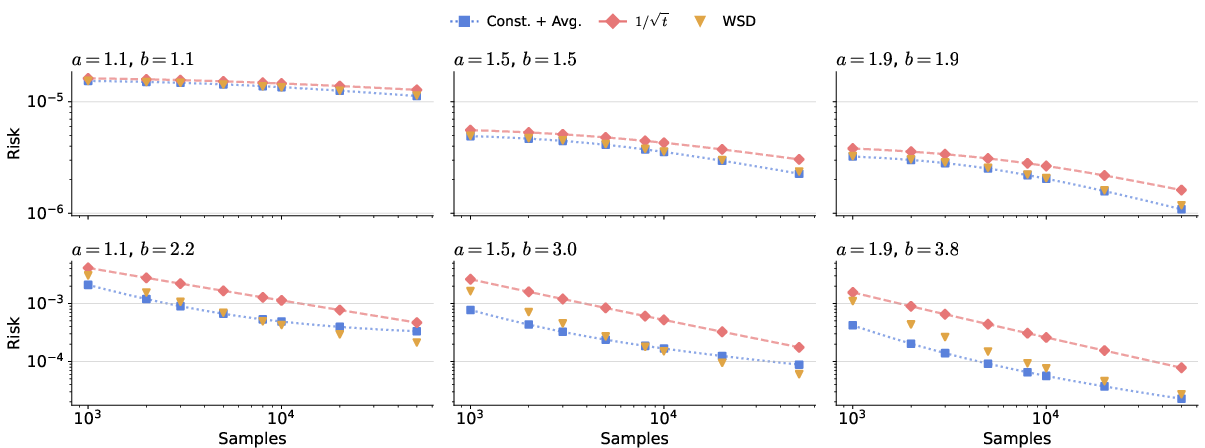
Risk analysis on synthetic linear regression tasks further supports the minimaxity of the proposed anytime schemes. Finite-sample risk comparisons (via bias-variance segmentation) confirm that 1/t-type schedules with averaging approximate the theoretical rates of constant LR with averaging in both finite and infinite-dimensional settings, provided hyperparameters are tuned for near-optimality across all evaluation points.
Figure 3: Risk recursion for different LR schedules verifies theoretical predictions for minimax rates under polynomially decaying schedules with averaging.
Figure 4: Detailed risk comparison for SGD on linear regression under various schedules.
Practical Implications and Contradictory Insights
A significant practical implication is the demonstration that cosine decay, a de facto standard in LLM training, is ill-suited for environments where horizon length is dynamic or unknown. Cosine schedules optimized for long-horizon training substantially underperform at intermediate checkpoints, yielding marked sub-optimality (see the gap to the "cosine envelope").
Key empirical claim: Properly tuned, horizon-free schedules plus weight averaging can match or exceed the performance of horizon-tuned cosine schedules at all intermediate training budgets, establishing them as practical, robust alternatives for both research and production-scale continual learning.
Theoretical and Future Directions
The paper's results suggest that the optimal choice between constant or decaying LR anytime schedules hinges on the interplay of data spectrum and signal alignment. The analysis connects statistical learning theory (e.g., minimax risk bounds in the high-dimensional or nonparametric regime) with practical recipe development for massive-scale transformer model optimization.
Given the utility of weight averaging in smoothing optimization noise and implicitly regularizing generalization (with connections to flatness and optima sharpness), further investigations could extend these results into the non-convex domain, including fully nonlinear neural architectures where sharp spectral decay assumptions may not hold. Future work may also examine adaptive or data-driven schemes to select optimal γ or averaging windows, especially during dynamic data stream conditions inherent in continual pretraining scenarios.
Moreover, translating these insights to distributed, parallelized, or asynchronous optimizer variants presents further challenges. An exploration of anytime schedule interplay with memory-augmented checkpointing mechanisms (as in WSD) could yield hybrid approaches with both theoretical guarantees and system-level efficiency.
Conclusion
This work provides both rigorous theoretical and empirical evidence that horizon-free learning rate schedules—particularly constant or polynomially decaying LRs with appropriate weight averaging—are viable, minimax-optimal alternatives to horizon-coupled scheduling like cosine decay. These results have direct implications for the design of scalable, robust, and efficient continual pretraining pipelines for LLMs, reducing hyperparameter dependency on prescient horizon specification, and enabling more flexible long-term model optimization strategies—contributing substantial clarity to the foundations of large-scale neural optimization.