When, Where and Why to Average Weights?
Abstract: Averaging checkpoints along the training trajectory is a simple yet powerful approach to improve the generalization performance of Machine Learning models and reduce training time. Motivated by these potential gains, and in an effort to fairly and thoroughly benchmark this technique, we present an extensive evaluation of averaging techniques in modern Deep Learning, which we perform using AlgoPerf \citep{dahl_benchmarking_2023}, a large-scale benchmark for optimization algorithms. We investigate whether weight averaging can reduce training time, improve generalization, and replace learning rate decay, as suggested by recent literature. Our evaluation across seven architectures and datasets reveals that averaging significantly accelerates training and yields considerable efficiency gains, at the price of a minimal implementation and memory cost, while mildly improving generalization across all considered workloads. Finally, we explore the relationship between averaging and learning rate annealing and show how to optimally combine the two to achieve the best performances.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future work:
- Limited optimizer coverage
- Results hinge primarily on NadamW; only a single second-order case (Shampoo on WMT) is shown. It remains unclear whether findings generalize across other widely used optimizers (e.g., AdamW variants, Adafactor, Lion, SGD+momentum, SAM) and on more workloads.
- The claimed connection between averaging and LR decay is untested with adaptive optimizers’ internal dynamics (momentum, adaptive moments); a theoretical and empirical analysis for AdamW-like methods is missing.
- Incomplete comparison to alternative averaging variants
- No direct, controlled comparison to SWA, Tail/Two-Tailed Averaging, or Switch-EMA (SEMA). It is unknown whether the chosen LAWA/EMA variants are near-optimal across the reported workloads.
- Per-parameter, per-layer, or adaptive averaging coefficients (e.g., layer-wise EMA rates, noise-scale-aware averaging) are not explored.
- Averaging hyperparameters remain heuristic
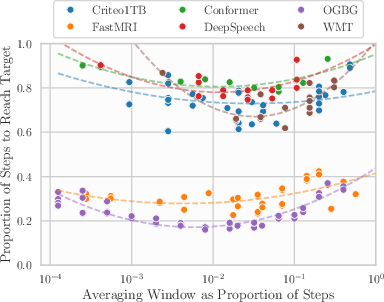
- The “~1% of total training budget” horizon guideline is empirical and benchmark-specific; there is no general method to choose the window length L, update frequency ν, or EMA decay γ across tasks and budgets.
- No adaptive or data-driven procedure is provided to set/adjust averaging hyperparameters online (e.g., based on validation loss curvature, gradient noise scale, or learning-rate phase).
- Relationship to learning-rate scheduling is under-characterized
- While averaging approximates shorter LR schedules, the precise failure modes where averaging cannot replace annealing are not characterized (e.g., which noise regimes, batch sizes, or schedule shapes).
- Only cosine decay is evaluated; the interaction with linear decay, step decay, warm restarts, or piecewise schedules is not studied.
- The mechanism behind the stronger improvements on WMT compared to other tasks is not analyzed.
- Scope limitations of tasks, scales, and settings
- No experiments on LLM pretraining or very-large-scale models where high learning rates and massive batches are standard (a regime where prior work reports larger averaging gains).
- Distribution shift, robustness (adversarial or natural), and calibration effects are not measured, despite prior claims that WA can improve robustness.
- Continual learning and long-horizon fine-tuning settings (where LR decay is undesirable) are not evaluated, though the paper motivates this use case.
- Generalization results need deeper analysis
- The modest end-of-training generalization gains of WA (with LR schedules) are reported but not dissected. It is unclear which factors (data regime, regularization, overfitting onset) govern when WA helps or saturates.
- Interactions with common regularizers (weight decay magnitude, label smoothing, dropout, data augmentation) are not explored; these might alter WA’s efficacy.
- Overhead and systems aspects are under-quantified
- Claims of “minimal implementation and memory cost” are not backed by systematic wall-clock profiling, GPU utilization metrics, or distributed training overhead measurements (e.g., checkpoint I/O pressure, EMA maintenance with model sharding/ZeRO).
- The disk/memory implications of LAWA’s window for large models are not quantified; practical strategies (compression, low-precision checkpoints, sparse averaging) are not evaluated.
- Online vs offline averaging trade-offs (latency, communication, precision of EMA in bf16/fp16 vs fp32 shadow copies) are not rigorously benchmarked.
- Replacement vs complement of LR decay remains open in broader settings
- The conclusion that offline averaging cannot replace LR schedules is shown for AlgoPerf and specific averaging forms; it remains open whether alternative schedule-free or “average-in-the-loop” methods (e.g., ROAD, SEMA-like switching, Polyak-inspired updates) can close the gap across all workloads.
- How to best combine partial annealing with WA (schedule shapes, timings, handoff criteria) to achieve Pareto-optimal speed–accuracy trade-offs is not specified.
- Limited statistical rigor for variability
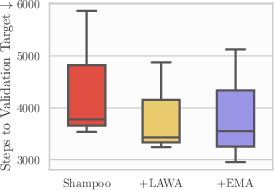
- Only three seeds are used; tasks with high variance (e.g., FastMRI) show large dispersion. Confidence intervals and robust statistical tests are absent, limiting the certainty of small reported gains.
- Missing mechanistic and geometric insights
- The paper does not measure landscape properties (e.g., sharpness/flatness, curvature, Hessian spectra) to explain when/why WA accelerates training or improves generalization.
- No analysis of gradient noise, batch-size scaling, or noise–averaging interactions that could predict where WA should be most effective.
- Early stopping and run-time usage
- The speed-up claims rely on known target thresholds; methods for practical early stopping using averaged checkpoints without predefined targets (e.g., online validation heuristics) are not provided.
- Interactions with training recipes not explored
- Effects of WA with mixed precision, gradient clipping, activation/weight scaling, or parameter-efficient fine-tuning (LoRA, adapters) are untested.
- Compatibility with privacy-preserving training (DP-SGD) and its impact on utility–privacy trade-offs is unexplored.
- Model soups and averaging across runs
- The paper does not evaluate whether within-run averaging synergizes with cross-run soups (e.g., LAWA/EMA followed by soup) or whether one can replace the other in practice.
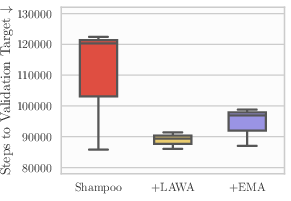
- Shampoo/second-order optimizers: narrow evidence
- Only a single workload (WMT) is shown for Shampoo+LAWA; it is unknown whether similar gains hold across other architectures/datasets or whether second-order curvature estimates obviate some benefits of WA.
- Practical guidance remains incomplete
- There is no recipe for selecting update frequency ν vs window length L given I/O constraints, nor for setting EMA decay γ relative to training horizon, batch size, or LR schedule.
- No guidance on safely using WA in resource-constrained pipelines (e.g., how to checkpoint sparsely without losing most of WA’s benefit).
Practical Applications
Immediate Applications
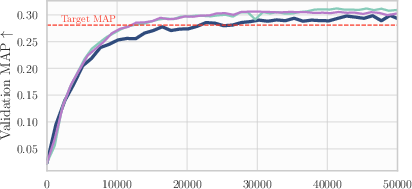
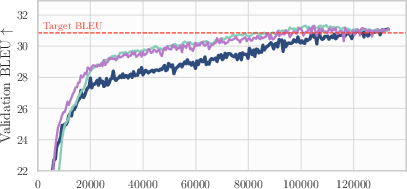
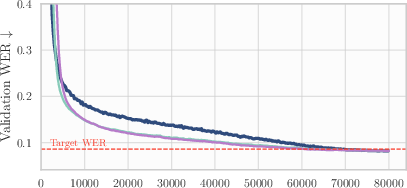
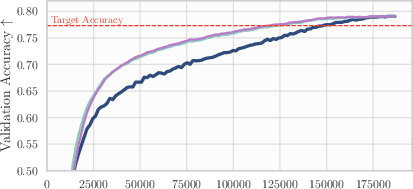
The following applications can be deployed now, based on the paper’s demonstrated findings across seven modern deep learning workloads (vision, NLP, speech, graphs, recsys), with minimal implementation and memory overhead.
- Industry — Training efficiency: add LAWA/EMA to existing training pipelines to reduce compute costs and time
- Sector: software/AI infrastructure, cloud, energy, finance
- Workflow/product: a training callback/plugin that maintains a rolling window (LAWA) or an EMA of model weights; update frequency every ν steps; trigger early stopping when the averaged model reaches the target validation score
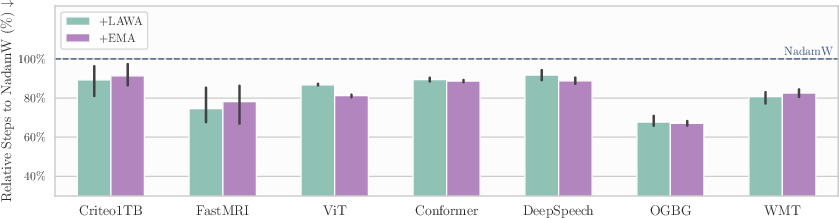
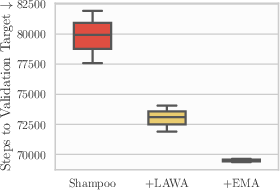
- Evidence: ~15% GPU-hour savings across AlgoPerf; ~78% of steps to target vs NadamW; minimal code and memory cost
- Assumptions/dependencies: target metric thresholds defined; storage for a small buffer of checkpoints; compatibility with existing optimizers (e.g., NadamW, Shampoo); horizon set near ~1% of total training steps for best results
- Industry — Production accuracy uplift without architecture changes
- Sector: NLP (machine translation), speech recognition, computer vision, recommender systems, medical imaging
- Workflow/product: deploy averaged weights periodically during training to get mild generalization gains; in WMT (Transformer-big), gains are notable; small but consistent improvements elsewhere (ViT on ImageNet, Conformer/DeepSpeech on Librispeech, DLRM on Criteo, U-Net on FastMRI, GNN on OGBG)
- Assumptions/dependencies: LR scheduling still used; averaging buffer hyperparameters tuned lightly (e.g., window/horizon ~1% of budget)
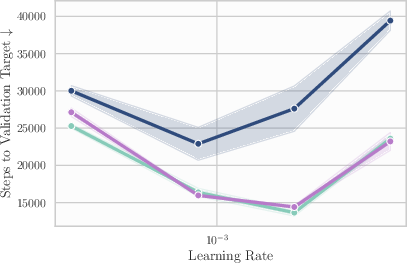
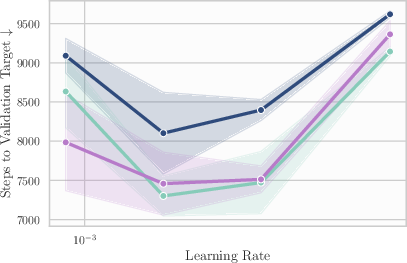
- Industry — Combine LR annealing with averaging for best performance
- Sector: cross-sector ML training recipes
- Workflow/product: update standard recipes to apply cosine/other LR schedules plus LAWA/EMA; use averaged checkpoints for validation/early deployment
- Evidence: coupling WA with LR decay consistently outperforms either alone
- Assumptions/dependencies: LR schedules retained; WA does not replace LR annealing fully in these offline flavors
- Industry — Second-order optimizer acceleration
- Sector: high-performance ML (large-scale NLP/CV)
- Workflow/product: integrate LAWA on top of Distributed Shampoo to cut iterations to target (e.g., WMT)
- Evidence: LAWA speeds convergence even with Shampoo
- Assumptions/dependencies: access to optimizer states; compatible checkpointing cadence
- Industry — Cost and carbon reduction in ML operations
- Sector: sustainability/energy management
- Workflow/product: mandate WA callbacks in training for large jobs; report GPU-hour reductions
- Evidence: ~15% GPU-hour savings across AlgoPerf
- Assumptions/dependencies: monitoring and reporting tools; small extra storage/compute for averaging
- Academia — Benchmarking and teaching
- Sector: education/research
- Workflow/product: adopt AlgoPerf-style evaluation with WA baselines; assign labs on LAWA/EMA vs LR schedules; demonstrate optimal horizon selection (~1% budget)
- Assumptions/dependencies: reproducible seeds; fixed budgets or target scores; minimal extra implementation
- Academia — Hyperparameter tuning stabilizer
- Sector: ML research/engineering
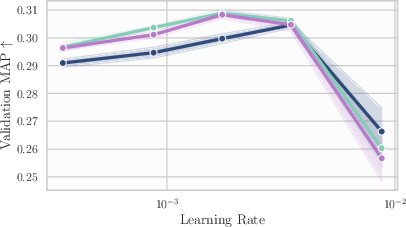
- Workflow/product: use LAWA/EMA to maintain performance across suboptimal top learning rates; cut tuning cycles by leveraging averaged checkpoints
- Evidence: WA preserves efficiency gains across LR sweeps; no need for peak-tuned baselines
- Assumptions/dependencies: LR schedule still preferred for final generalization; averaging parameters loosely tuned
- Daily life — Faster rollout of improved translations/speech models
- Sector: consumer apps (translation, dictation), accessibility
- Workflow/product: deploy averaged checkpoints mid-training to accelerate release cycles; run A/B tests on averaged vs base models
- Assumptions/dependencies: continuous integration for models; target metrics for go/no-go; data drift monitoring
- Software/MLOps — “Averaging-as-a-Service”
- Sector: tooling/platforms
- Workflow/product: provide PyTorch/TF callbacks; Hugging Face Trainer extension; MLflow/Kubeflow integration to maintain LAWA/EMA, visualize averaged vs base validation, auto-trigger early stopping
- Assumptions/dependencies: checkpoint management (ring buffer/circular queue); cross-framework support; low-latency metric evaluation
- Applied domains — Healthcare (FastMRI), Recsys (Criteo), CV (ImageNet), Graphs (OGBG), Speech (Librispeech), MT (WMT)
- Sector: healthcare, advertising/retail, software, research labs
- Workflow/product: apply WA to accelerate training to predefined targets; use averaged weights for model selection without inference overhead
- Assumptions/dependencies: domain-specific target metrics; responsible deployment checks; dataset/task similarity to benchmark settings
Long-Term Applications
These applications require further research, scaling, or development to realize fully (e.g., deeper integrations, standardization, or new algorithms).
- Industry/Academia — Schedule-free optimization that replaces LR annealing via integrated averaging
- Sector: optimization algorithms
- Product/workflow: design optimizers that use averaged weights directly in updates (beyond “offline” WA), extending ideas like Defazio et al.’s schedule-free methods
- Dependencies: theoretical guarantees; broad benchmarking; robust performance across tasks; careful stability controls
- Cloud/Hardware — Native support for weight averaging in managed training services and accelerators
- Sector: cloud platforms, semiconductor/GPU vendors
- Product/workflow: hardware-level EMA accumulators; checkpoint ring buffers; asynchronous CPU/GPU memory pathways for averaged weights; service-level toggles for WA with best-practice defaults (e.g., 1% horizon)
- Dependencies: API standards; memory safety; performance profiling; sharded models and distributed training compatibility
- Policy — Efficiency standards and disclosures for compute-intensive training
- Sector: sustainability and governance
- Product/workflow: guidelines requiring inclusion of WA or equivalent efficiency measures in publicly funded/enterprise AI training; GPU-hour and carbon reporting; “efficiency badges”
- Dependencies: standardized metrics; independent audits; sector-specific exemptions
- AutoML/MLOps — Automated horizon and cadence selection
- Sector: ML platform automation
- Product/workflow: auto-tuners that select averaging window and checkpoint frequency (ν, L) using heuristics/meta-learning; dynamic policies that track validation improvements against training time
- Dependencies: reliable validation signals; minimal overhead; task-adaptive policies
- Continual/online learning — Averaging-enabled snapshotting while continuing training
- Sector: foundation models, streaming/online applications
- Product/workflow: maintain EMA/LAWA snapshots for evaluation/deployment mid-training even when LR does not decay to zero; support continuous updates without losing access to strong intermediate models
- Dependencies: drift detection; snapshot governance; high-throughput evaluation pipelines
- Standardized benchmarks and reporting
- Sector: research/industry consortia
- Product/workflow: include WA baselines and LR schedule interplay in optimization benchmarks; report target-reaching time and generalization under fixed budgets, with and without WA
- Dependencies: community adoption; reproducible configs; cross-task comparability
- Model soups at scale
- Sector: fine-tuning large pre-trained models
- Product/workflow: aggregate weights from multiple fine-tunes/hyperparams into “soups” for robustness/accuracy without inference overhead; combine with LAWA/EMA within and across runs
- Dependencies: basin compatibility (models lie in same low-error region); safe averaging protocols; tooling to manage multiple runs
- Carbon-aware job scheduling using averaged checkpoints
- Sector: data center operations
- Product/workflow: schedulers that leverage faster target attainment via WA to lower peak energy usage; shift workloads to cleaner energy windows with confidence in early stopping
- Dependencies: forecasting models; target metrics; job prioritization policies
- Test-time compute policies that exploit averaged training trajectories
- Sector: deployment engineering
- Product/workflow: calibrate when to “lock” averaged weights for evaluation/deployment vs continue training; integrate with strategies that scale test-time compute for latent performance (e.g., in the spirit of scaling test-time compute)
- Dependencies: team policies; latency budgets; real-world feedback loops
- Sector-specific protocols — healthcare, finance, safety-critical AI
- Sector: regulated domains
- Product/workflow: codify WA use for model selection and early stopping to reduce training costs while meeting performance targets; include WA settings in documentation for audits and reproducibility
- Dependencies: regulatory acceptance; thorough validation; documentation standards
Notes on feasibility and assumptions across applications:
- WA in this paper is “offline” (averaged weights do not drive updates). It improves efficiency and mild generalization but does not fully replace LR schedules.
- Best-practice defaults from the study: maintain a small buffer; checkpoint every ν steps; set averaging horizon near ~1% of total training steps; combine with LR decay for optimal final performance.
- Benefits are consistent across diverse workloads and optimizers, but the magnitude varies; WMT shows notable generalization gains, others are modest.
- Storage and compute overhead are minimal, but very large models may require sharded checkpoint management.
- Early stopping via averaged models assumes clear target metrics and reliable validation pipelines.
Collections
Sign up for free to add this paper to one or more collections.