- The paper introduces a hierarchical modeling approach that treats speech enhancement as a conditional language modeling task using semantic and acoustic tokens.
- The methodology employs a two-step process—noise-to-semantic transformation and semantic-to-speech generation—using XLSR and SimCodec to boost performance.
- Experimental results show GenSE outperforms benchmarks with superior PESQ, MOS, and DNSMOS scores, ensuring naturalness and speaker similarity across noisy conditions.
GenSE: Generative Speech Enhancement via LLMs using Hierarchical Modeling
Introduction
GenSE introduces an innovative approach to speech enhancement by leveraging LMs for semantic representation of speech signals. The framework addresses limitations in traditional methods which often neglect semantic information critical for achieving high-quality speech, especially under challenging noise conditions. GenSE reframes the SE task as a conditional language modeling problem, employing semantic and acoustic tokens derived from a self-supervised speech model and a custom neural codec, respectively.
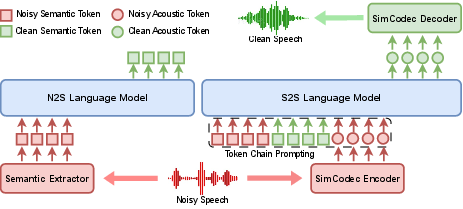
Figure 1: The hierarchical modeling framework of LLM in GenSE.
Framework Design
Semantic and Acoustic Tokenization
GenSE utilizes semantic tokens to capture high-level linguistic information through a pre-trained model, XLSR, and acoustic tokens using SimCodec, a novel codec model designed to reduce token prediction complexity. The tokenization process is key in bridging continuous speech and LMs, allowing for enhanced modeling capabilities beyond mere noise suppression.
Hierarchical Modeling
Implemented through a two-step process, the hierarchical modeling segregates token generation into distinct stages: noise-to-semantic (N2S) transformation and semantic-to-speech (S2S) generation. This separation helps ensure that noise does not adversely affect semantic token accuracy, ultimately leading to better acoustic token prediction and enriched final speech output.

Figure 2: The detailed architecture and training process of SimCodec, with the reorganization process of the group quantizer highlighted in the red dashed block.
SimCodec and Quantization Process
SimCodec reduces computational complexity by using a single quantizer with an expanded codebook, facilitated by a unique reorganization process. This approach carefully balances the number of tokens and reconstruction quality, ensuring efficient LM prediction while maintaining audio fidelity.
Reorganization Process: By selecting the most used tokens from an initial multi-stage quantization sequence, SimCodec reorganizes these into an augmented codebook space, substantially improving codebook utilization and enhancing performance metrics like PESQ and MOS scores.
Experimental Results
GenSE's performance was evaluated against several state-of-the-art SE systems using objective metrics such as DNSMOS and SECS, alongside subjective assessments for speech naturalness and speaker similarity. The framework consistently outperformed baselines, particularly demonstrating robustness in unseen acoustic environments like the CHiME-4 dataset.
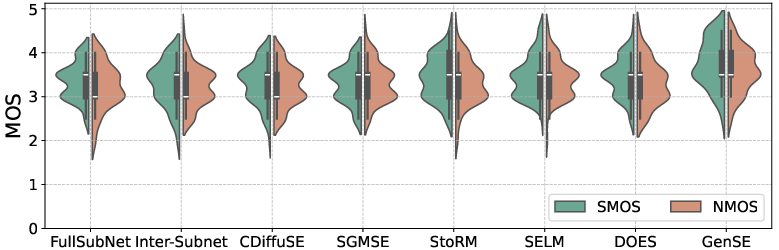
Figure 3: Violin plots for speech naturalness and speaker similarity, comparing the signals enhanced by baseline systems and GenSE.
Objective Metrics: GenSE notably improved scores across both reverb and non-reverb conditions, with substantial gains in OVL and SECS metrics emphasizing its ability to preserve speech quality and speaker identity.
Subjective Metrics: Violin plots confirmed enhanced perceptual qualities of GenSE over baselines, with median scores for naturalness and similarity showcasing its superior enhancement capabilities.
Conclusion
GenSE stands out as a robust framework kindled by hierarchical modeling and efficient tokenization strategies, achieving unprecedented results in SE tasks. The integration of SimCodec significantly reduces token prediction complexity while preserving semantic and acoustic attributes vital for high-quality speech production. Future research will explore model scalability and real-time processing optimizations to further enhance applicability in diverse acoustic settings.