MAGE: A Coarse-to-Fine Speech Enhancer with Masked Generative Model
Abstract: Speech enhancement remains challenging due to the trade-off between efficiency and perceptual quality. In this paper, we introduce MAGE, a Masked Audio Generative Enhancer that advances generative speech enhancement through a compact and robust design. Unlike prior masked generative models with random masking, MAGE employs a scarcity-aware coarse-to-fine masking strategy that prioritizes frequent tokens in early steps and rare tokens in later refinements, improving efficiency and generalization. We also propose a lightweight corrector module that further stabilizes inference by detecting low-confidence predictions and re-masking them for refinement. Built on BigCodec and finetuned from Qwen2.5-0.5B, MAGE is reduced to 200M parameters through selective layer retention. Experiments on DNS Challenge and noisy LibriSpeech show that MAGE achieves state-of-the-art perceptual quality and significantly reduces word error rate for downstream recognition, outperforming larger baselines. Audio examples are available at https://hieugiaosu.github.io/MAGE/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MAGE: What this paper is about
This paper introduces MAGE, a smart tool that cleans up noisy speech so it sounds clearer to people and to machines. It uses a “generative” approach, which means it learns what clean speech should look like and then tries to rebuild it from a messy recording. The big idea is to make this process both high-quality and efficient, so it works well in real life, not just in labs.
The main goals and questions
The researchers wanted to solve three main problems:
- How can we make speech enhancement sound natural and clear, not robotic or muffled?
- How can we make it fast enough and small enough to run on normal hardware?
- How can we avoid the common mistakes that happen when models try to fix noise in different real-world situations?
They asked: Can a smarter “masking” strategy (deciding which parts to guess and when) and a simple “corrector” (a checker that fixes low-confidence guesses) improve quality and speed at the same time?
How MAGE works, in simple terms
Think of cleaning up noisy speech like fixing a blurry, puzzle-like picture:
- First, the audio is turned into small building blocks called “tokens” (like Lego pieces). A speech codec called BigCodec does this, creating about 80 tokens per second.
- MAGE is a language-model-like system that learns how these tokens should look for clean speech.
- It uses “masking,” which is like covering certain puzzle pieces and asking the model to guess them using the surrounding context.
Here are the key ideas explained with everyday analogies:
- Masked generative model: Imagine a fill-in-the-blanks game for sound. The model hides some pieces and predicts what they should be to make the speech clean.
- Coarse-to-fine (CTF) masking: Instead of hiding tokens randomly, MAGE starts by fixing the most common, easy parts first, then tackles rare, tricky parts later. It’s like painting the background of a picture first, then adding the fine details. This saves time and helps the model generalize to new types of noise.
- Corrector module: After the model makes predictions, a lightweight “proofreader” checks for low-confidence pieces and asks the model to re-try only those parts. This prevents errors from piling up and improves the final sound.
- Band-aware encoder (TF-GridNet): This component looks at different frequency bands (think bass vs. treble) and how they interact, helping the model understand both the voice and the noise more efficiently.
- Small but smart: MAGE starts with a general-purpose LLM (Qwen2.5-0.5B) and trims it down to about 200 million parameters by keeping only selected layers. It uses LoRA (a way to fine-tune big models cheaply) to train on a single GPU.
What they found and why it matters
The team tested MAGE on two major benchmarks:
- DNS Challenge: A widely used test set for noisy and real recordings.
- Noisy LibriSpeech: Clean audiobooks mixed with different types of noise.
They measured:
- SIG (signal quality), BAK (background noise), and OVL (overall quality), from DNSMOS.
- WER (Word Error Rate), which shows how well an automatic speech recognizer understands the enhanced audio.
Main results:
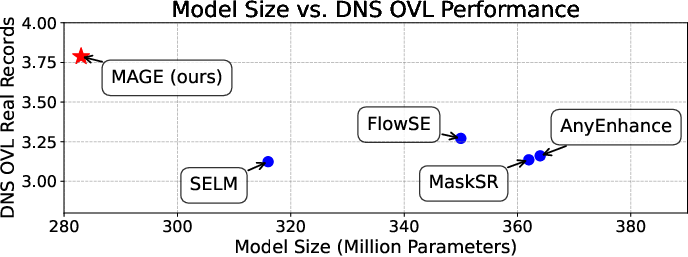
- MAGE achieves state-of-the-art perceptual quality compared to bigger, more expensive models.
- The CTF strategy clearly improves overall quality, especially on real recordings and non-reverberant audio.
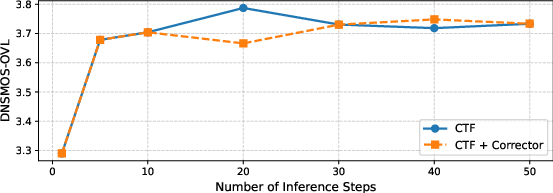
- The corrector makes the system more stable during inference (prediction time), further boosting scores.
- On Noisy LibriSpeech, MAGE reduces WER to about 23.45%, better than other top generative methods (lower WER means the speech is easier for machines to understand).
Why this matters:
- People get cleaner, more natural-sounding speech in everyday environments like homes, streets, or offices.
- Machines (like voice assistants, captioning systems, or transcription tools) make fewer mistakes because the speech is clearer.
- The model is compact and efficient, making it practical for real-world apps and devices.
What this could change in the future
This research shows that you don’t need massive models or slow methods to get great audio quality. By:
- Fixing common parts first, then refining rare details,
- And adding a simple “proofreader” to catch mistakes,
MAGE bridges the gap between high-quality sound and practical speed. This can impact:
- Better phone calls and online meetings,
- More accurate voice assistants and transcription,
- Easier data collection for building speech systems,
- Future multilingual and streaming enhancements,
- Joint systems that combine enhancement with speech recognition and text-to-speech.
In short, MAGE is a smart, efficient way to clean up speech that helps both humans and machines understand audio better.
Glossary
- ASR (Automatic Speech Recognition): A system that transcribes spoken audio into text; used for evaluating intelligibility improvements. "We also use the released ASR model to compute WER, reflecting intelligibility gains."
- BAK (Background Intrusiveness): A DNSMOS metric indicating how intrusive background noise is in the enhanced audio. "SIG (signal distortion), BAK (background intrusiveness), and OVL (overall quality) from ITU-T P.835"
- Band-Aware Encoder: An encoder that models frequency bands explicitly to capture cross-band spectral dependencies. "Besides, speaker identity is extracted by a Band-Aware Encoder and a pretrained Speaker Encoder, enabling it to capture the acoustic characteristics."
- BigCodec: A neural speech codec providing discrete tokens and high-quality reconstruction for audio language modeling. "we adopt BigCodec, which provides stable tokenization and high-quality reconstruction using a single codebook with 80 tokens per second."
- BLSTM (Bidirectional Long Short-Term Memory): A recurrent neural network variant that processes sequences in both forward and backward directions. "we train a lightweight 4-layer BLSTM corrector that identifies low-confidence tokens and re-masks them."
- Codebook: The discrete set of indices used by a neural codec to represent audio tokens. "using a single codebook with 80 tokens per second."
- Coarse-to-Fine (CTF) masking strategy: A scarcity-aware schedule that masks frequent tokens earlier and rare tokens later to improve efficiency and generalization. "we introduce a coarse-to-fine (CTF) masking strategy."
- Corrector module: A lightweight post-processing component that detects low-confidence tokens and re-masks them for iterative refinement. "We also propose a lightweight corrector module that further stabilizes inference by detecting low-confidence predictions and re-masking them for refinement."
- Cosine schedule: A masking probability schedule based on a cosine function used across denoising steps. "where follows a cosine schedule~\cite{zhang2025anyenhanceunifiedgenerativemodel,li2024MaskSR}."
- DNS Challenge: A benchmark dataset and evaluation framework for noise suppression and speech enhancement. "Experiments on DNS Challenge and noisy LibriSpeech show that MAGE achieves state-of-the-art perceptual quality and significantly reduces word error rate for downstream recognition, outperforming larger baselines."
- DNSMOS: A non-intrusive objective metric suite (SIG/BAK/OVL) that estimates perceptual speech quality. "DNSMOS scores (SIG/BAK/OVL) and speaker cosine similarity (SSIM) are reported."
- Document frequency: The count of how often a token appears across the training corpus, used to compute rarity for masking. "where is the document frequency~\cite{tf-idf} of token in the training corpus."
- HuBERT: A self-supervised speech representation model used as a strong but compute-intensive encoder baseline. "SSL models, such as HuBERT, deliver strong performance but are computationally intensive."
- IDF-like score (Inverse Document Frequency-like): A rarity measure computed from document frequency to prioritize masking of rare tokens later. "We then calculate an IDF-like score:"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method for LLMs. "We finetune the masked LLM from Qwen2.5-0.5B using LoRA~\cite{hu2022lora}."
- Mask Generative Model (MGM): A generative framework that reconstructs masked tokens iteratively, conditioned on context and acoustic information. "the MGM learns to reconstruct masked tokens over denoising steps."
- Neural Encodec: A neural audio compression model that converts target audio into discrete tokens for modeling. "Target audio is first converted into sequence of tokens using a Neural Encodec."
- Non-autoregressive mode (attention): An attention configuration that predicts tokens without relying on past outputs in sequence order. "attention is configured in a non-autoregressive mode."
- OVL (Overall Quality): A DNSMOS metric capturing the overall perceptual quality of the enhanced audio. "SIG (signal distortion), BAK (background intrusiveness), and OVL (overall quality) from ITU-T P.835"
- PESQ (Perceptual Evaluation of Speech Quality): An intrusive metric assessing speech quality by comparing enhanced audio to clean references. "Discriminative models directly map noisy inputs to clean signals by optimizing losses aligned with intrusive metrics such as SI-SDR, PESQ, and STOI."
- Qwen2.5-0.5B: A LLM backbone from which MAGE is finetuned and selectively pruned for efficiency. "The LLM is a reduced Qwen2.5-0.5B, where only the odd-numbered layers are kept (layer 1 is the first), and attention is configured in a non-autoregressive mode."
- Short-time Fourier Transform (STFT): A time-frequency analysis method used to obtain complex spectrograms for conditioning. "The MAGE speech encoder applies Short-time Fourier Transform with , , "
- SIG (Signal Distortion): A DNSMOS metric reflecting the amount of distortion introduced to the speech signal. "SIG (signal distortion), BAK (background intrusiveness), and OVL (overall quality) from ITU-T P.835"
- Speaker embedding: A vector representation of speaker identity used to condition the generative model. "concatenated with the speaker embedding, which is projected from using a lightweight adaptor."
- Speaker Similarity (SSIM): A cosine-similarity-based measure comparing speaker embeddings to assess identity preservation. "Speaker Similarity (SSIM), computed as the cosine similarity between speaker embeddings from Wespeaker \cite{wang2023wespeaker}."
- STOI (Short-Time Objective Intelligibility): An intrusive intelligibility metric estimating how understandable speech is after enhancement. "Discriminative models directly map noisy inputs to clean signals by optimizing losses aligned with intrusive metrics such as SI-SDR, PESQ, and STOI."
- TF-GridNet: A lightweight architecture that models full- and sub-band frequency interactions for conditioning. "we leverage a TF-GridNet block~\cite{ZhongQiuWang2023TF_gridnet}, which efficiently models cross-band frequency interactions while remaining lightweight."
- WavLM: A large-scale self-supervised model providing discrete token representations for language-model-driven speech enhancement. "Discrete representations facilitate language-model-driven SE, as demonstrated by SELM~\cite{wang2024selm}, which leverages WavLM~\cite{Chen2022WavLM}, and MaskSR~\cite{li2024MaskSR}"
- Word Error Rate (WER): A standard ASR metric measuring transcription error rate, used to quantify intelligibility. "We also use the released ASR model to compute WER, reflecting intelligibility gains."
Collections
Sign up for free to add this paper to one or more collections.