- The paper presents a unified framework that decomposes audio aesthetics into four axes: Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness.
- It employs a Transformer-based model with a WavLM encoder, optimizing predictions through MAE and MSE loss, and demonstrates competitive performance with existing benchmarks.
- The research offers an open-source dataset with 97k annotated samples, paving the way for scalable automatic evaluation of synthetic audio quality.
Introduction
The paper "Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound" presents a methodological approach for automating the evaluation of audio aesthetics across different modalities. Addressing the subjective nature of audio aesthetics, the authors propose a system that predicts audio quality without human intervention, crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models.
Audio aesthetic evaluation traditionally involves human listeners, which results in inconsistencies and demands substantial resources. As a solution, the paper introduces a unified framework decomposing audio aesthetics into four distinct axes: Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness. This approach enables a more comprehensive assessment and facilitates scalable solutions to evaluate synthetic audio quality from generative models.
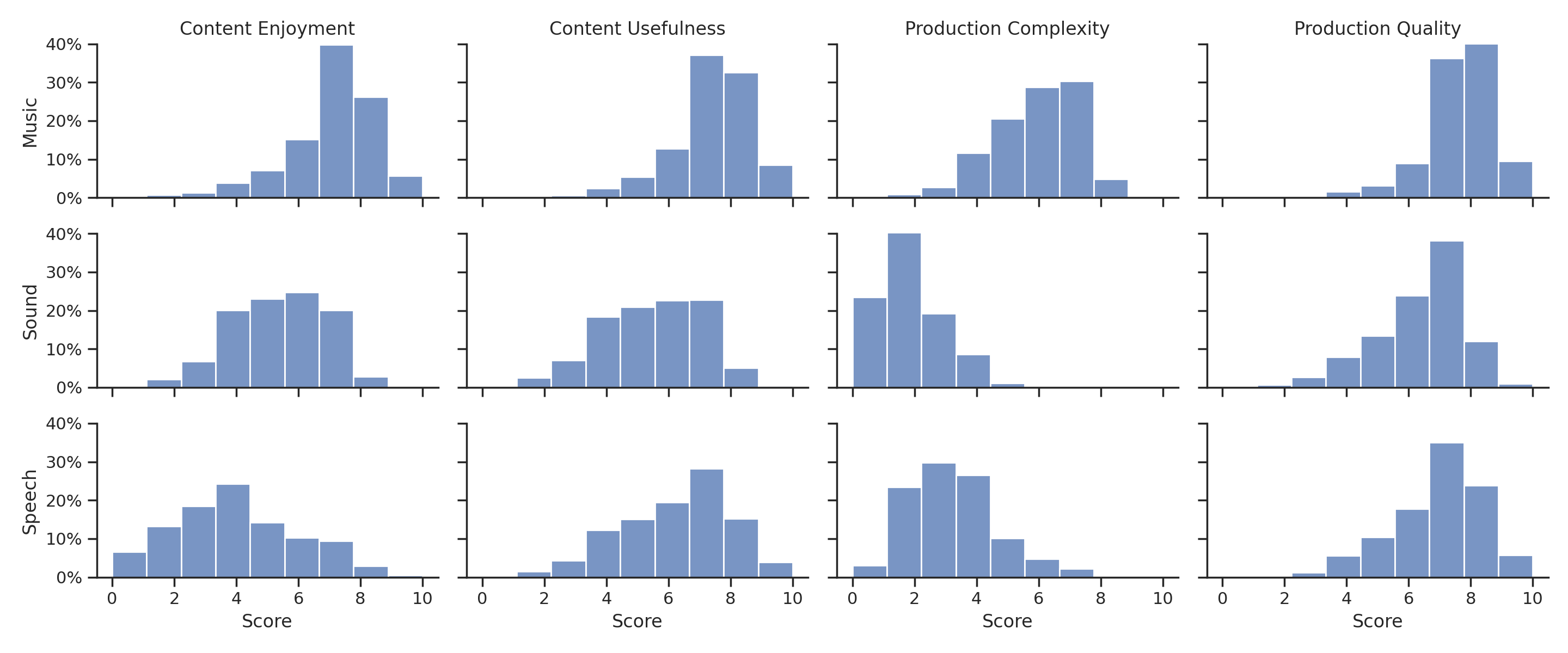
Figure 1: Aesthetic score distribution by evaluation axes and audio modalities, y-axis shows percentages in each score bucket.
Proposed Approach
Audio Aesthetics Evaluation Axes
The authors propose four axes to categorize audio aesthetics:
- Production Quality (PQ): Focuses on technical aspects like clarity, fidelity, and spatialization.
- Production Complexity (PC): Evaluates the complexity of an audio scene by the number of audio components.
- Content Enjoyment (CE): Assesses emotional impact and artistic expression.
- Content Usefulness (CU): Determines the audio's potential as source material for content creation.
These axes provide a refined evaluation framework compared to traditional mean opinion scores (MOS), which can be biased depending on individual rater perceptions.
Annotation and Dataset
The paper details the method of annotating 97k audio samples across speech, sound effects, and music. Raters assess audio clips on a scale from 1 to 10 based on the defined axes. The authors developed an annotation UI (Figure 2) to streamline the process and ensure quality data collection.
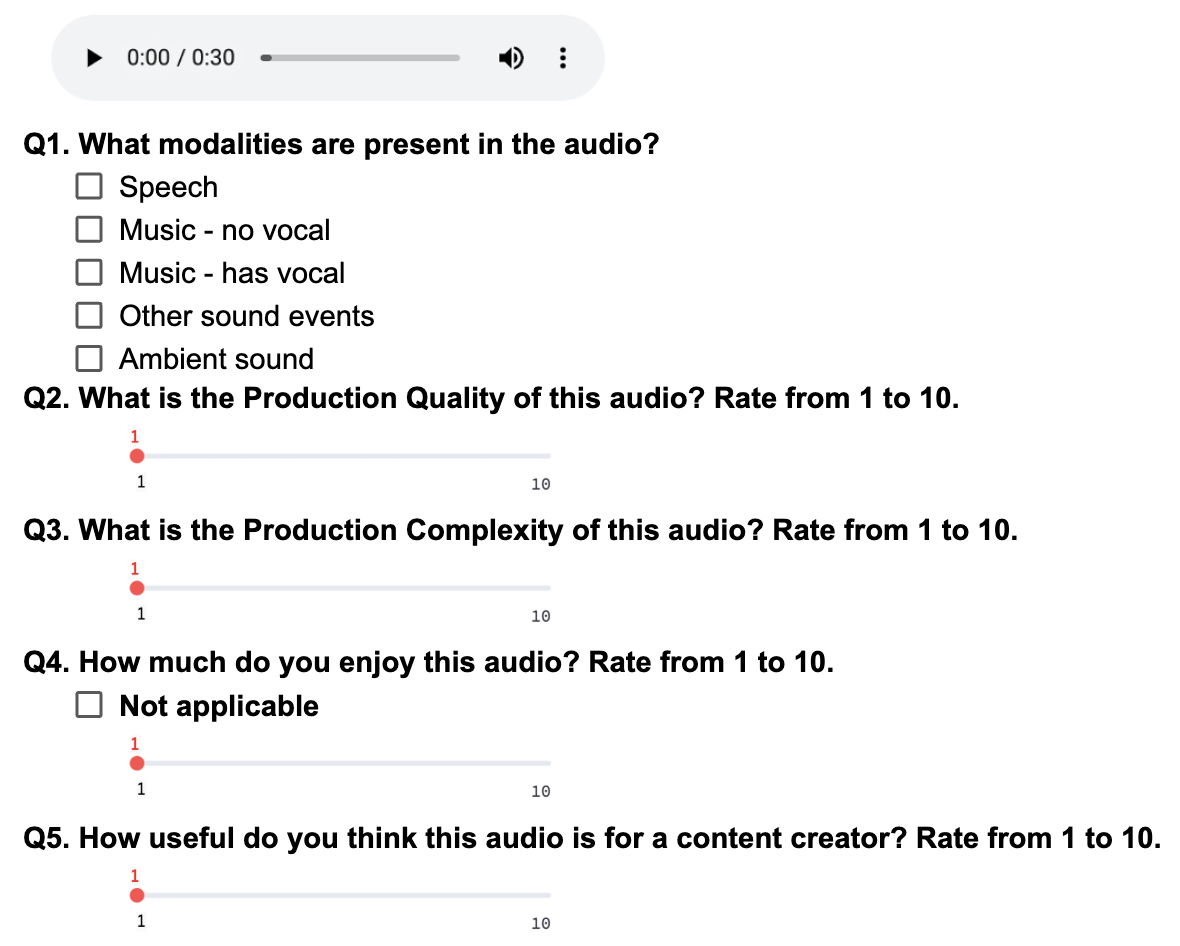
Figure 2: Aesthetic score annotation UI.
Predictor Model and Architecture
The Audiobox-Aesthetics predictor model employs a Transformer-based architecture with a WavLM-based encoder. A series of Transformer layers extracts audio embeddings, which are processed through MLP blocks to output predicted aesthetic scores across the four axes.
The model is trained using a mean-absolute error (MAE) and mean squared error (MSE) loss minimization, optimizing predictions against human-annotated target scores.
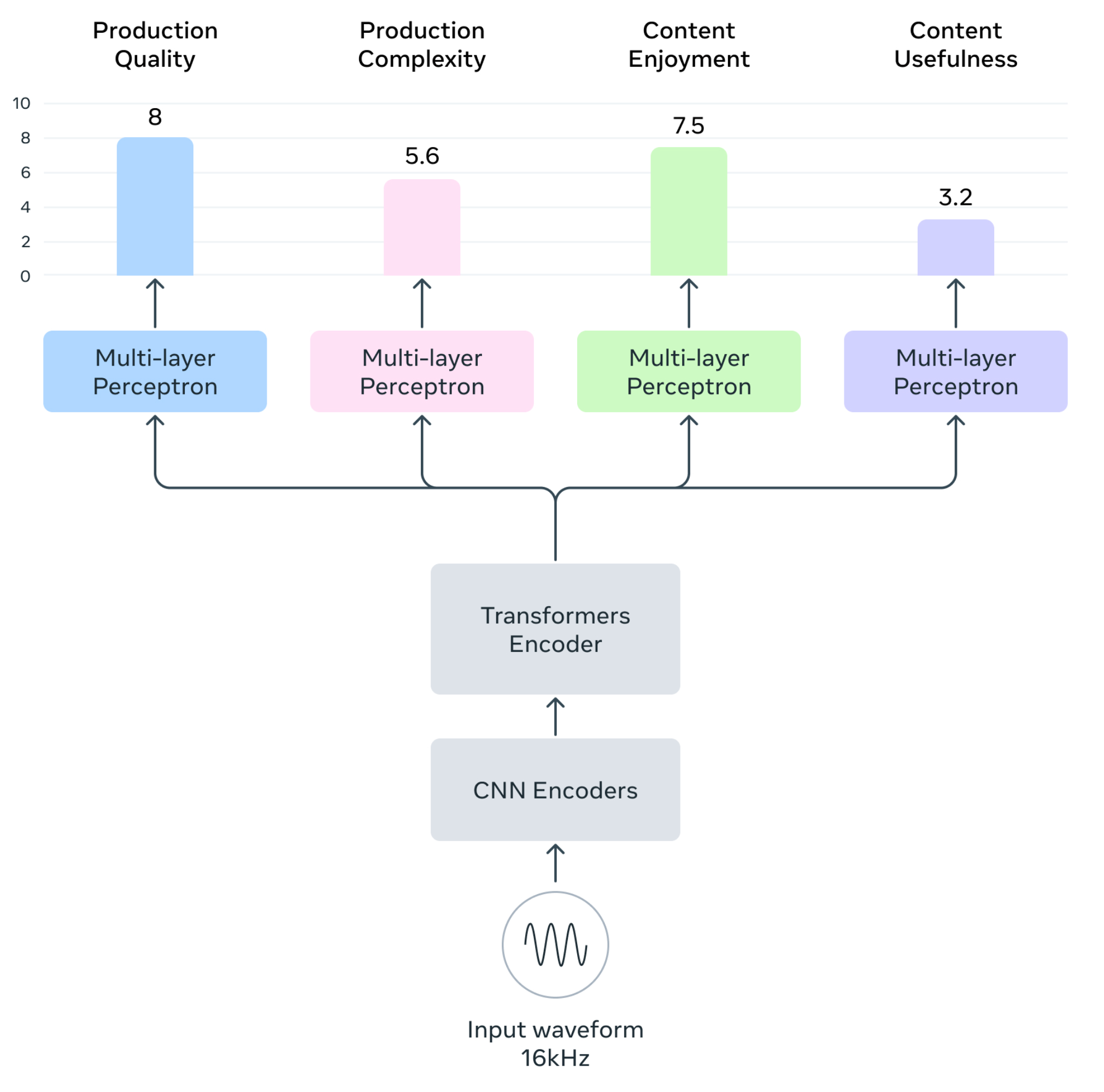
Figure 3: An overview of Audiobox-Aesthetics architectures, input and output.
Evaluation and Results
The authors compare their models with existing benchmarks, demonstrating competitive performance across various audio types:
- Speech Prediction: The Audiobox-Aesthetics models achieved Pearson correlation coefficients comparable to established predictors like DNSMOS and UTMOSv2, particularly for Production Quality and Content Enjoyment.
- Sound and Music Prediction: For datasets like PAM-sound and PAM-music, Audiobox-Aesthetics models provide valuable insights across axes, outperforming PAM when measuring axes individually.
Correlation between different aesthetics score axes (Figure 4) further validates the need for multi-dimensional assessment over simple MOS scores.
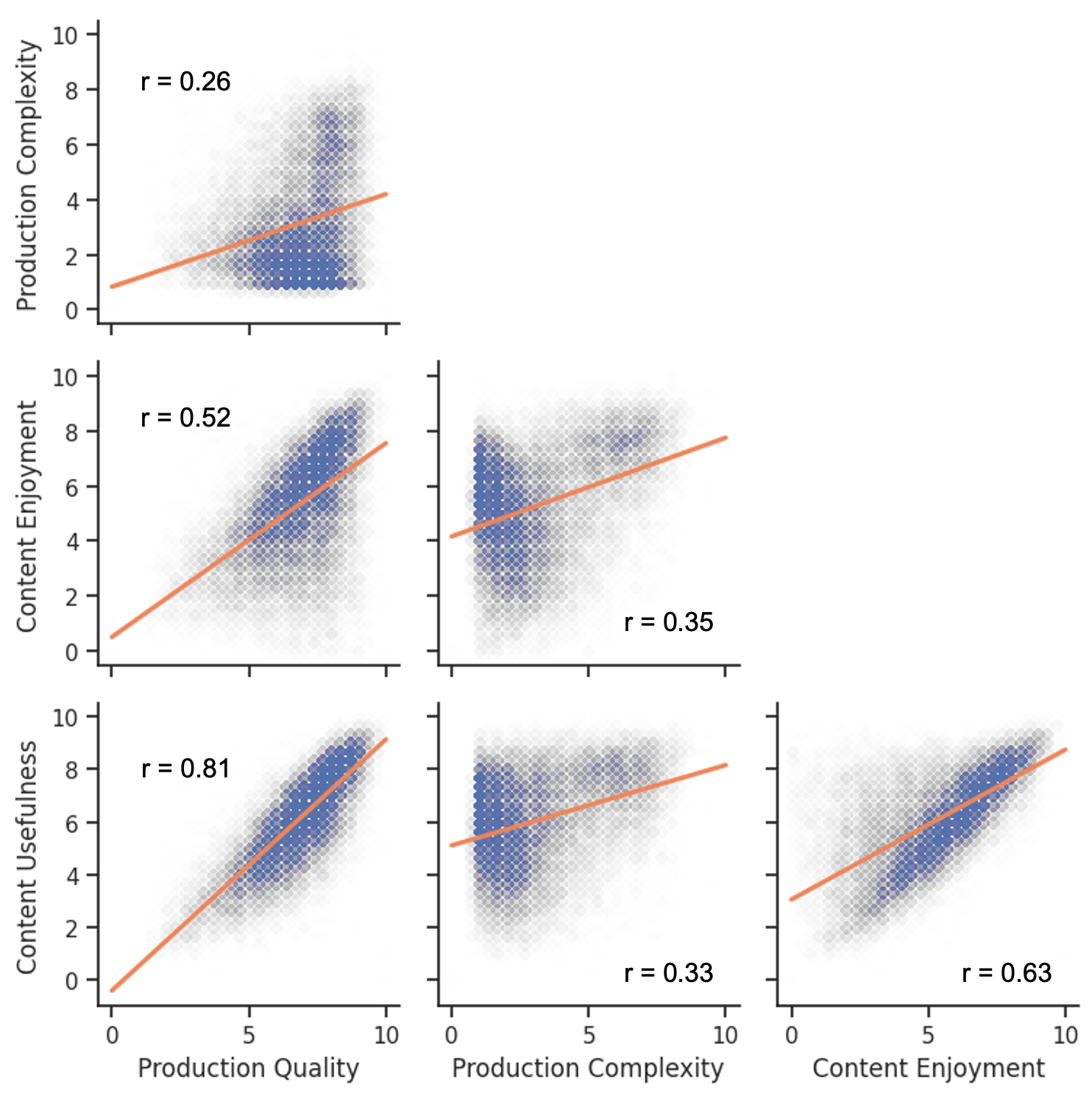
Figure 4: Correlation between different aesthetics score axes. Pearson rs are reported.
Implications and Future Work
The study provides an open-source framework and dataset, enabling further research and benchmarking in audio aesthetics evaluation. As generative audio models continue to advance, this research outlines a scalable and reliable approach for assessing synthetic audio quality.
Future work may explore enhancements in neural network architectures, improved annotation methodologies, and further integration with generative audio model evaluations.
Conclusion
This paper delineates a comprehensive framework for audio aesthetics evaluation, advancing the field with automated, reliable methodologies across speech, sound, and music domains. The unified approach with distinct evaluation axes facilitates deeper insights into audio quality, paving the way for improved generative model assessments and scalable applications in audio processing. The authors’ contributions in data and model availability promote ongoing research, enhancing automated aesthetic evaluation's efficacy and reach.