- The paper introduces SongEval, a dataset that provides five-dimensional expert evaluations for full-length songs.
- It employs professional annotators to rate overall coherence, memorability, vocal phrasing, song structure, and musicality.
- Results show that models trained on SongEval outperform traditional audio metrics, advancing music generation evaluation.
Introduction to SongEval
The paper introduces SongEval, a pioneering dataset designed to evaluate the aesthetics of full-length songs, addressing the limitations of existing metrics in capturing subjective musical appeal. It includes over 2,399 songs, rated by professional annotators across five aesthetic dimensions: overall coherence, memorability, naturalness of vocal phrasing, clarity of song structure, and overall musicality.
Dataset Characteristics
SongEval encompasses songs in both English and Chinese across nine genres, providing a comprehensive resource for assessing musical generation models. Each song is annotated by experts, ensuring high reliability in the evaluation. The dataset’s diversity spans various languages and music styles, making it versatile for different musical applications.
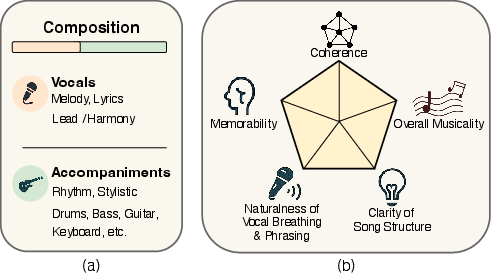
Figure 1: Aesthetic evaluation dimensions and structural components of a song. (a) Structural components of a song. (b) Five aesthetic dimensions used in SongEval for full-length song evaluation.
The data collection process involves generating lyrics and genre-aligned prompts, followed by full-length song synthesis using established commercial systems. This ensures diversity in vocal and instrumental characteristics.
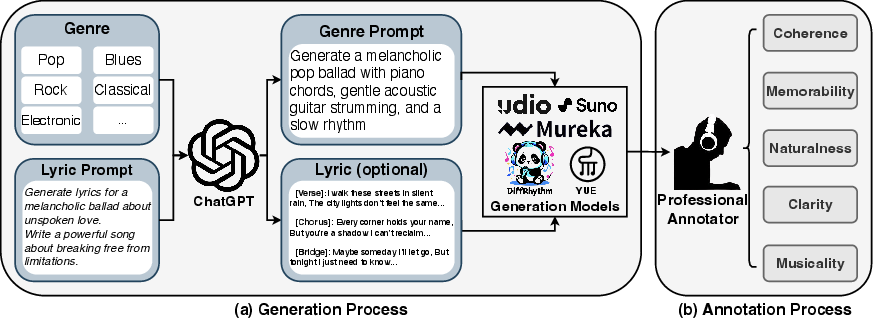
Figure 2: The data collection pipeline of SongEval. Lyrics are an optional input, as some commercial systems can generate songs using only a genre prompt.
Aesthetic Annotation
Each song is evaluated across five key dimensions, providing a rich framework for understanding musical quality beyond traditional metrics. The annotated dimensions are designed to capture subjective qualities that influence musical perception significantly.
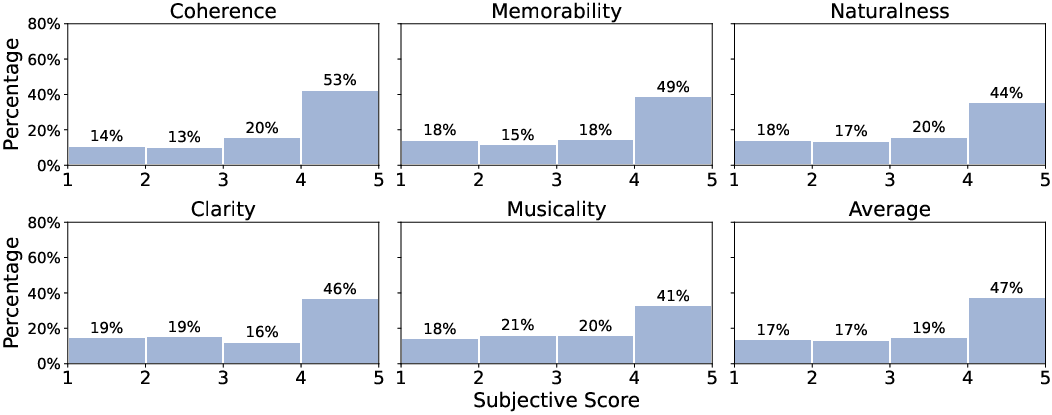
Figure 3: Distribution of overall subjective scores over five evaluation dimensions.
The annotation process utilizes professional evaluators, ensuring the dataset reflects expert consensus on musical aesthetics. This multidimensional approach enhances the reliability of aesthetic evaluation, facilitating nuanced assessments of generative models.
Experimental Setup
SongEval supports training aesthetic prediction models across multiple dimensions, using advanced architectures like MOSNet, LDNet, SSL-based models, and UTMOS-based frameworks. These systems demonstrate robust performance in predicting aesthetic attributes, highlighting SongEval’s effectiveness in modeling human musical perception.
Comparison with Objective Metrics
Models trained on SongEval outperform conventional audio metrics in correlating human-perceived aesthetics, underscoring SongEval's value in comprehensive song evaluation.
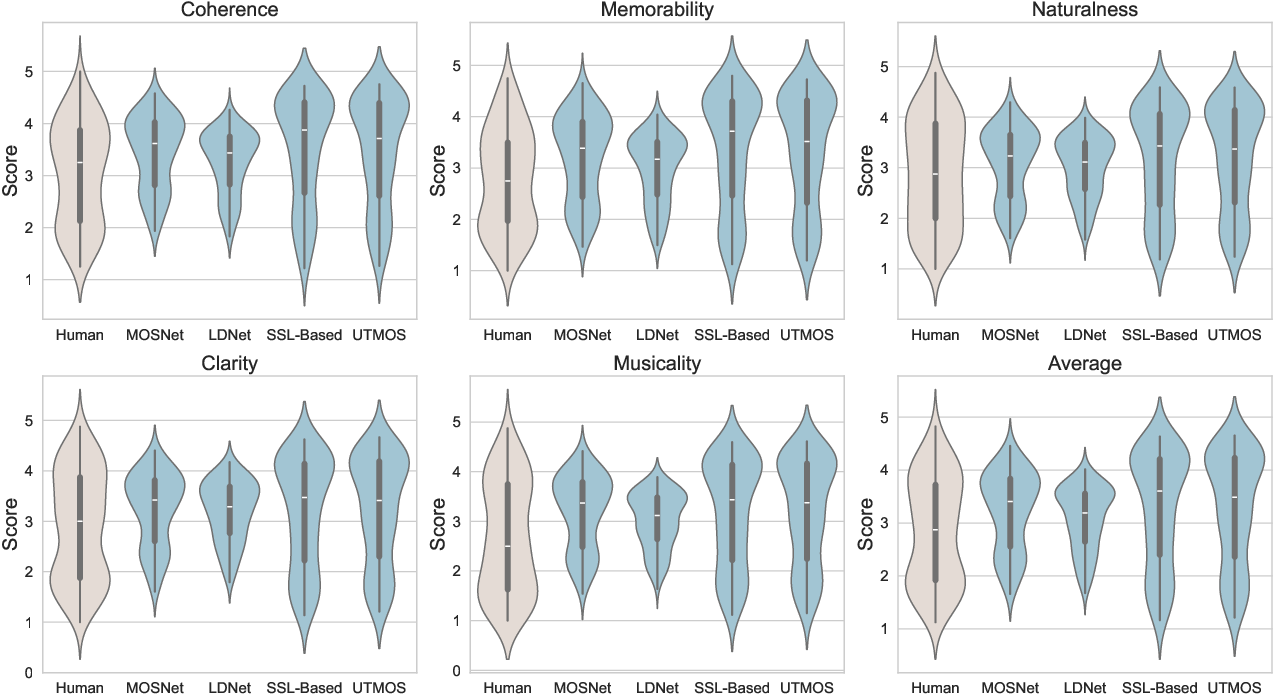
Figure 4: Violin plots of the aesthetic evaluation results between human annotation and different prediction systems.
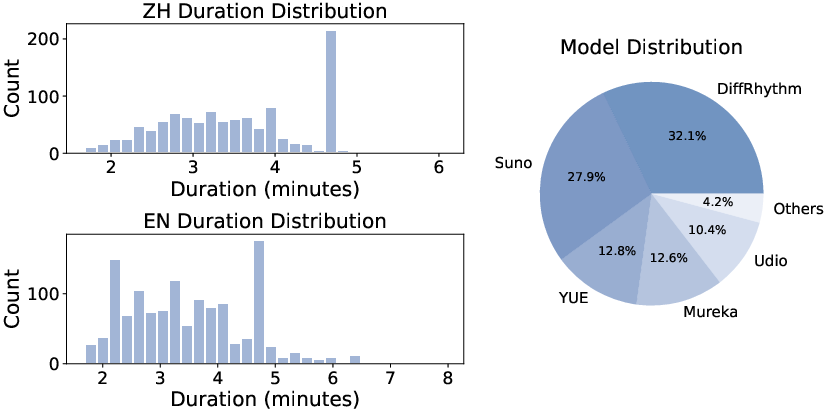
Figure 5: Duration distribution across different languages and generation models. Since the songs generated by DiffRhythm have a fixed duration of 285 seconds, a noticeable concentration of songs around the four-minute mark in the distribution.
Conclusion
SongEval sets a new benchmark in song aesthetics evaluation, offering a reliable, professional standard for examining generative models. This dataset provides critical insights into musical quality, offering a foundational resource for advancing music generation technology and evaluation methods.
Limitations and Future Work
Though SongEval provides a robust framework for aesthetic evaluation, it is limited by potential overlaps between dimensions. Future research aims to refine evaluative tools, enhancing model predictions across diverse music styles and genres.
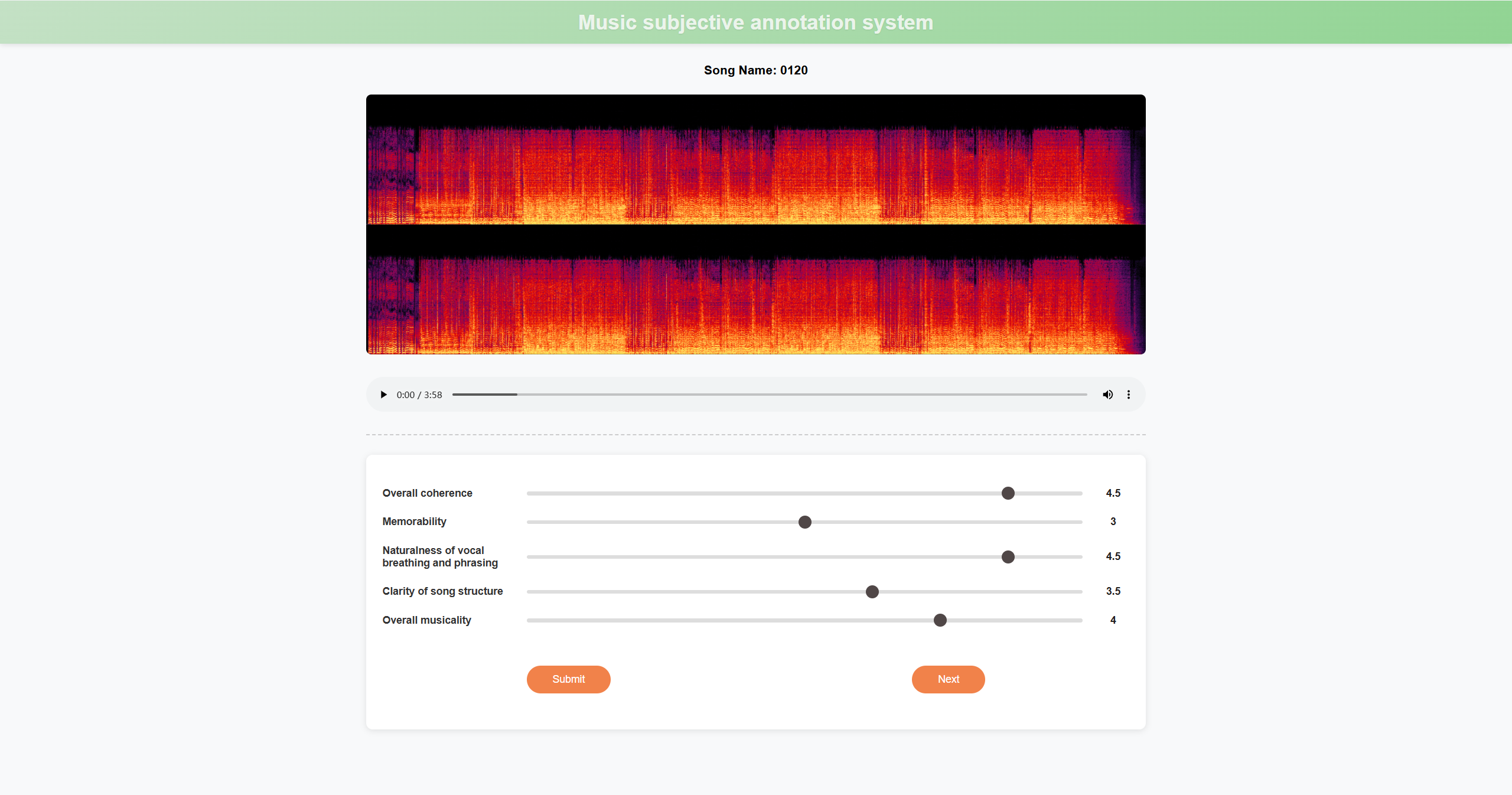
Figure 6: Screenshot of subjective annotation interface used for evaluating musical aesthetics.
This comprehensive dataset serves as a valuable resource for academia and industry, fostering developments in automatic song aesthetic evaluation and improving generative model capabilities for music production.